Multi-AZ DB cluster deployments for Amazon RDS
A Multi-AZ DB cluster deployment is a semisynchronous, high availability deployment mode of Amazon RDS with two readable replica DB instances. A Multi-AZ DB cluster has a writer DB instance and two reader DB instances in three separate Availability Zones in the same AWS Region. Multi-AZ DB clusters provide high availability, increased capacity for read workloads, and lower write latency when compared to Multi-AZ DB instance deployments.
You can import data from an on-premises database to a Multi-AZ DB cluster by following the instructions in Importing data to an Amazon RDS for MySQL database with reduced downtime.
You can purchase reserved DB instances for a Multi-AZ DB cluster. For more information, see Reserved DB instances for a Multi-AZ DB cluster.
Feature availability and support varies across specific versions of each database engine, and across AWS Regions. For more information on version and Region availability of Amazon RDS with Multi-AZ DB clusters, see Supported Regions and DB engines for Multi-AZ DB clusters in Amazon RDS.
Topics
Automatically connecting an AWS compute resource and a Multi-AZ DB cluster for Amazon RDS
Upgrading the engine version of a Multi-AZ DB cluster for Amazon RDS
Rebooting a Multi-AZ DB cluster and reader DB instances for Amazon RDS
Setting up PostgreSQL logical replication with Multi-AZ DB clusters for Amazon RDS
Working with Multi-AZ DB cluster read replicas for Amazon RDS
Setting up external replication from Multi-AZ DB clusters for Amazon RDS
Important
Multi-AZ DB clusters aren't the same as Aurora DB clusters. For information about Aurora DB clusters, see the Amazon Aurora User Guide.
Instance class availability for Multi-AZ DB clusters
Multi-AZ DB cluster deployments are supported for the following DB instance classes: db.m5d,
db.m6gd, db.m6id, db.m6idn,
db.r5d, db.r6gd, db.x2iedn,
db.r6id, and db.r6idn, and db.c6gd.
Note
The c6gd instance classes are the only ones that support the medium
instance size.
For more information about DB instance classes, see DB instance classes.
Multi-AZ DB cluster architecture
With a Multi-AZ DB cluster, Amazon RDS replicates data from the writer DB instance to both of the reader DB instances using the DB engine's native replication capabilities. When a change is made on the writer DB instance, it's sent to each reader DB instance.
Multi-AZ DB cluster deployments use semisynchronous replication, which requires acknowledgment from at least one reader DB instance in order for a change to be committed. It doesn't require acknowledgment that events have been fully executed and committed on all replicas.
Reader DB instances act as automatic failover targets and also serve read traffic to increase application read throughput. If an outage occurs on your writer DB instance, RDS manages failover to one of the reader DB instances. RDS does this based on which reader DB instance has the most recent change record.
The following diagram shows a Multi-AZ DB cluster.
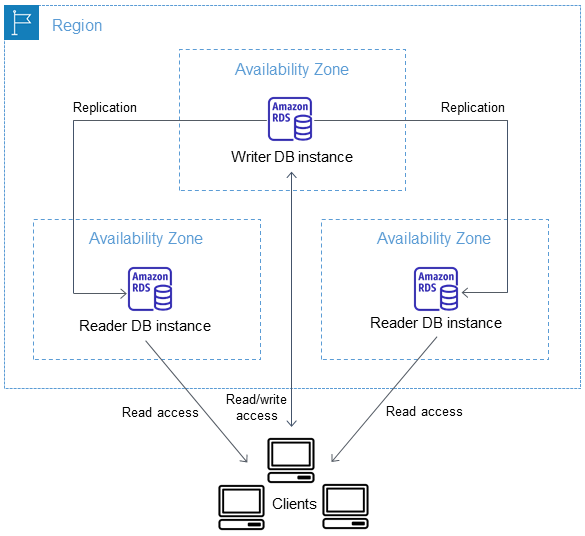
Multi-AZ DB clusters typically have lower write latency when compared to Multi-AZ DB instance deployments. They also allow read-only workloads to run on reader DB instances. The RDS console shows the Availability Zone of the writer DB instance and the Availability Zones of the reader DB instances. You can also use the describe-db-clusters CLI command or the DescribeDBClusters API operation to find this information.
Important
To prevent replication errors in RDS for MySQL Multi-AZ DB clusters, we strongly recommend that all tables have a primary key.
Parameter groups for Multi-AZ DB clusters
In a Multi-AZ DB cluster, a DB cluster parameter group acts as a container for engine configuration values that are applied to every DB instance in the Multi-AZ DB cluster.
In a Multi-AZ DB cluster, a DB parameter group is set to the default DB parameter group for the DB engine and DB engine version. The settings in the DB cluster parameter group are used for all of the DB instances in the cluster.
For information about parameter groups, see Working with DB cluster parameter groups for Multi-AZ DB clusters.
RDS Proxy with Multi-AZ DB clusters
You can use Amazon RDS Proxy to create a proxy for your Multi-AZ DB clusters. By using RDS Proxy, your applications can pool and share database connections to improve their ability to scale. Each proxy performs connection multiplexing, also known as connection reuse. With multiplexing, RDS Proxy performs all the operations for a transaction using one underlying database connection. RDS Proxy can also reduce the downtime for a minor version upgrade of a Multi-AZ DB cluster to one second or less. For more information about the benefits of RDS Proxy, see Amazon RDS Proxy.
To set up a proxy for a Multi-AZ DB cluster, choose Create an RDS Proxy when creating the cluster. For instructions to create and manage RDS Proxy endpoints, see Working with Amazon RDS Proxy endpoints.
Replica lag and Multi-AZ DB clusters
Replica lag is the difference in time between the latest transaction on
the writer DB instance and the latest applied transaction on a reader DB instance. The
Amazon CloudWatch metric ReplicaLag represents this time difference. For more
information about CloudWatch metrics, see Monitoring Amazon RDS metrics with Amazon CloudWatch.
Although Multi-AZ DB clusters allow for high write performance, replica lag can still occur due to the nature of engine-based replication. Because any failover must first resolve the replica lag before it promotes a new writer DB instance, monitoring and managing this replica lag is a consideration.
For RDS for MySQL Multi-AZ DB clusters, failover time depends on replica lag of both remaining reader DB instances. Both the reader DB instances must apply unapplied transactions before one of them is promoted to the new writer DB instance.
For RDS for PostgreSQL Multi-AZ DB clusters, failover time depends on the lowest replica lag of the two remaining reader DB instances. The reader DB instance with the lowest replica lag must apply unapplied transactions before it is promoted to the new writer DB instance.
For a tutorial that shows you how to create a CloudWatch alarm when replica lag exceeds a set amount of time, see Tutorial: Creating an Amazon CloudWatch alarm for Multi-AZ DB cluster replica lag for Amazon RDS.
Common causes of replica lag
In general, replica lag occurs when the write workload is too high for the reader DB instances to apply the transactions efficiently. Various workloads can incur temporary or continuous replica lag. Some examples of common causes are the following:
-
High write concurrency or heavy batch updating on the writer DB instance, causing the apply process on the reader DB instances to fall behind.
-
Heavy read workload that is using resources on one or more reader DB instances. Running slow or large queries can affect the apply process and can cause replica lag.
-
Transactions that modify large amounts of data or DDL statements can sometimes cause a temporary increase in replica lag because the database must preserve commit order.
Mitigating replica lag
For Multi-AZ DB clusters for RDS for MySQL and RDS for PostgreSQL, you can mitigate replica lag by reducing the load on your writer DB instance. You can also use flow control to reduce replica lag. Flow control works by throttling writes on the writer DB instance, which ensures that replica lag doesn't continue to grow unbounded. Write throttling is accomplished by adding a delay into the end of a transaction, which decreases the write throughput on the writer DB instance. Although flow control doesn't guarantee lag elimination, it can help reduce overall lag in many workloads. The following sections provide information about using flow control with RDS for MySQL and RDS for PostgreSQL.
Mitigating replica lag with flow control for RDS for MySQL
When you are using RDS for MySQL Multi-AZ DB clusters, flow control is turned on by default using the
dynamic parameter rpl_semi_sync_master_target_apply_lag. This
parameter specifies the upper limit that you want for replica lag. As replica
lag approaches this configured limit, flow control throttles the write
transactions on the writer DB instance to try to contain the replica lag below the
specified value. In some cases, replica lag can exceed the specified limit. By
default, this parameter is set to 120 seconds. To turn off flow control, set
this parameter to its maximum value of 86,400 seconds (one day).
To view the current delay injected by flow control, show the parameter
Rpl_semi_sync_master_flow_control_current_delay by running the
following query.
SHOW GLOBAL STATUS like '%flow_control%';
Your output should look similar to the following.
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)Note
The delay is shown in microseconds.
When you have Performance Insights turned on for an RDS for MySQL Multi-AZ DB cluster, you
can monitor the wait event corresponding to a SQL statement indicating that the
queries were delayed by a flow control. When a delay was introduced by a flow
control, you can view the wait event
/wait/synch/cond/semisync/semi_sync_flow_control_delay_cond
corresponding to the SQL statement on the Performance Insights dashboard. To
view these metrics, make sure that the Performance Schema is turned on. For
information about Performance Insights, see Monitoring DB load with Performance Insights on Amazon RDS.
Mitigating replica lag with flow control for RDS for PostgreSQL
When you are using RDS for PostgreSQL Multi-AZ DB clusters, flow control is deployed as an extension. It
turns on a background worker for all DB instances in the DB cluster. By default, the
background workers on the reader DB instances communicate the current replica lag with
the background worker on the writer DB instance. If the lag exceeds two minutes on any
reader DB instance, the background worker on the writer DB instance adds a delay at the end
of a transaction. To control the lag threshold, use the parameter
flow_control.target_standby_apply_lag.
When a flow control throttles a PostgreSQL process, the Extension wait event in
pg_stat_activity and Performance Insights indicates that. The
function get_flow_control_stats displays details about how much delay
is currently being added.
Flow control can benefit most online transaction processing (OLTP) workloads that have short but highly concurrent transactions. If the lag is caused by long-running transactions, such as batch operations, flow control doesn't provide as strong a benefit.
You can turn off flow control by removing the extension from the
shared_preload_libraries and rebooting your DB instance.
Multi-AZ DB cluster snapshots
Amazon RDS creates and saves automated backups of your Multi-AZ DB cluster during the configured backup window. RDS creates a storage volume snapshot of your DB cluster, backing up the entire cluster and not just individual instances.
You can also take manual backups of your Multi-AZ DB cluster. For very long-term backups, consider exporting the snapshot data to Amazon S3. For more information, see Creating a Multi-AZ DB cluster snapshot for Amazon RDS.
You can restore a Multi-AZ DB cluster to a specific point in time, creating a new Multi-AZ DB cluster. For instructions, see Restoring a Multi-AZ DB cluster to a specified time.
Alternately, you can restore a Multi-AZ DB cluster snapshot to a Single-AZ deployment or Multi-AZ DB instance deployment. For instructions, see Restoring from a Multi-AZ DB cluster snapshot to a DB instance.
