Amazon Redshift will no longer support the creation of new Python UDFs starting November 1, 2025.
If you would like to use Python UDFs, create the UDFs prior to that date.
Existing Python UDFs will continue to function as normal. For more information, see the
blog post
Loading data from Amazon EMR
You can use the COPY command to load data in parallel from an Amazon EMR cluster configured to write text files to the cluster's Hadoop Distributed File System (HDFS) as fixed-width files, character-delimited files, CSV files, or JSON-formatted files.
Process for loading data from Amazon EMR
This section walks you through the process of loading data from an Amazon EMR cluster. The following sections provide the details that you must accomplish each step.
-
Step 1: Configure IAM permissions
The users that create the Amazon EMR cluster and run the Amazon Redshift COPY command must have the necessary permissions.
-
Step 2: Create an Amazon EMR cluster
Configure the cluster to output text files to the Hadoop Distributed File System (HDFS). You will need the Amazon EMR cluster ID and the cluster's main public DNS (the endpoint for the Amazon EC2 instance that hosts the cluster).
-
Step 3: Retrieve the Amazon Redshift cluster public key and cluster node IP addresses
The public key enables the Amazon Redshift cluster nodes to establish SSH connections to the hosts. You will use the IP address for each cluster node to configure the host security groups to permit access from your Amazon Redshift cluster using these IP addresses.
-
Step 4: Add the Amazon Redshift cluster public key to each Amazon EC2 host's authorized keys file
You add the Amazon Redshift cluster public key to the host's authorized keys file so that the host will recognize the Amazon Redshift cluster and accept the SSH connection.
-
Step 5: Configure the hosts to accept all of the Amazon Redshift cluster's IP addresses
Modify the Amazon EMR instance's security groups to add input rules to accept the Amazon Redshift IP addresses.
-
Step 6: Run the COPY command to load the data
From an Amazon Redshift database, run the COPY command to load the data into an Amazon Redshift table.
Step 1: Configure IAM permissions
The users that create the Amazon EMR cluster and run the Amazon Redshift COPY command must have the necessary permissions.
To configure IAM permissions
-
Add the following permissions for the user that will create the Amazon EMR cluster.
ec2:DescribeSecurityGroups ec2:RevokeSecurityGroupIngress ec2:AuthorizeSecurityGroupIngress redshift:DescribeClusters -
Add the following permission for the IAM role or user that will run the COPY command.
elasticmapreduce:ListInstances -
Add the following permission to the Amazon EMR cluster's IAM role.
redshift:DescribeClusters
Step 2: Create an Amazon EMR cluster
The COPY command loads data from files on the Amazon EMR Hadoop Distributed File System (HDFS). When you create the Amazon EMR cluster, configure the cluster to output data files to the cluster's HDFS.
To create an Amazon EMR cluster
-
Create an Amazon EMR cluster in the same AWS Region as the Amazon Redshift cluster.
If the Amazon Redshift cluster is in a VPC, the Amazon EMR cluster must be in the same VPC group. If the Amazon Redshift cluster uses EC2-Classic mode (that is, it is not in a VPC), the Amazon EMR cluster must also use EC2-Classic mode. For more information, see Managing Clusters in Virtual Private Cloud (VPC) in the Amazon Redshift Management Guide.
-
Configure the cluster to output data files to the cluster's HDFS. The HDFS file names must not include asterisks (*) or question marks (?).
Important
The file names must not include asterisks ( * ) or question marks ( ? ).
-
Specify No for the Auto-terminate option in the Amazon EMR cluster configuration so that the cluster remains available while the COPY command runs.
Important
If any of the data files are changed or deleted before the COPY completes, you might have unexpected results, or the COPY operation might fail.
-
Note the cluster ID and the main public DNS (the endpoint for the Amazon EC2 instance that hosts the cluster). You will use that information in later steps.
Step 3: Retrieve the Amazon Redshift cluster public key and cluster node IP addresses
You will use the IP address for each cluster node to configure the host security groups to permit access from your Amazon Redshift cluster using these IP addresses.
To retrieve the Amazon Redshift cluster public key and cluster node IP addresses for your cluster using the console
-
Access the Amazon Redshift Management Console.
-
Choose the Clusters link in the navigation pane.
-
Select your cluster from the list.
-
Locate the SSH Ingestion Settings group.
Note the Cluster Public Key and Node IP addresses. You will use them in later steps.
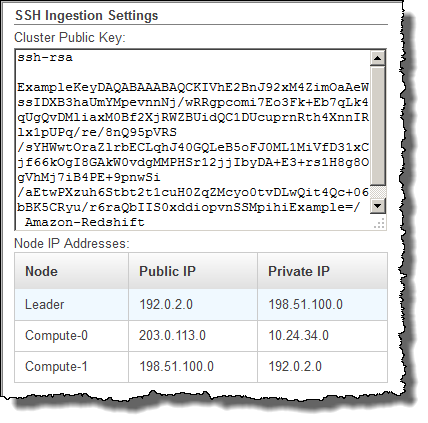
You will use the private IP addresses in Step 3 to configure the Amazon EC2 host to accept the connection from Amazon Redshift.
To retrieve the cluster public key and cluster node IP addresses for your cluster using the Amazon Redshift CLI, run the describe-clusters command. For example:
aws redshift describe-clusters --cluster-identifier <cluster-identifier>
The response will include a ClusterPublicKey value and the list of private and public IP addresses, similar to the following:
{ "Clusters": [ { "VpcSecurityGroups": [], "ClusterStatus": "available", "ClusterNodes": [ { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "LEADER", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-0", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-1", "PublicIPAddress": "10.nnn.nnn.nnn" } ], "AutomatedSnapshotRetentionPeriod": 1, "PreferredMaintenanceWindow": "wed:05:30-wed:06:00", "AvailabilityZone": "us-east-1a", "NodeType": "dc2.large", "ClusterPublicKey": "ssh-rsa AAAABexamplepublickey...Y3TAl Amazon-Redshift", ... ... }
To retrieve the cluster public key and cluster node IP addresses for your cluster
using the Amazon Redshift API, use the DescribeClusters action. For more
information, see describe-clusters in the Amazon Redshift CLI Guide or
DescribeClusters in the
Amazon Redshift API Guide.
Step 4: Add the Amazon Redshift cluster public key to each Amazon EC2 host's authorized keys file
You add the cluster public key to each host's authorized keys file for all of the Amazon EMR cluster nodes so that the hosts will recognize Amazon Redshift and accept the SSH connection.
To add the Amazon Redshift cluster public key to the host's authorized keys file
-
Access the host using an SSH connection.
For information about connecting to an instance using SSH, see Connect to Your Instance in the Amazon EC2 User Guide.
-
Copy the Amazon Redshift public key from the console or from the CLI response text.
-
Copy and paste the contents of the public key into the
/home/<ssh_username>/.ssh/authorized_keysfile on the host. Include the complete string, including the prefix "ssh-rsa" and suffix "Amazon-Redshift". For example:ssh-rsa AAAACTP3isxgGzVWoIWpbVvRCOzYdVifMrh… uA70BnMHCaMiRdmvsDOedZDOedZ Amazon-Redshift
Step 5: Configure the hosts to accept all of the Amazon Redshift cluster's IP addresses
To allow inbound traffic to the host instances, edit the security group and add one Inbound rule for each Amazon Redshift cluster node. For Type, select SSH with TCP protocol on Port 22. For Source, enter the Amazon Redshift cluster node private IP addresses you retrieved in Step 3: Retrieve the Amazon Redshift cluster public key and cluster node IP addresses. For information about adding rules to an Amazon EC2 security group, see Authorizing Inbound Traffic for Your Instances in the Amazon EC2 User Guide.
Step 6: Run the COPY command to load the data
Run a COPY command to connect to the Amazon EMR cluster and load the data into an Amazon Redshift table. The Amazon EMR cluster must continue running until the COPY command completes. For example, do not configure the cluster to auto-terminate.
Important
If any of the data files are changed or deleted before the COPY completes, you might have unexpected results, or the COPY operation might fail.
In the COPY command, specify the Amazon EMR cluster ID and the HDFS file path and file name.
COPY sales FROM 'emr://myemrclusterid/myoutput/part*' CREDENTIALS IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole';
You can use the wildcard characters asterisk ( * ) and question mark
( ? ) as part of the file name argument. For example, part*
loads the files part-0000, part-0001, and so on. If you
specify only a folder name, COPY attempts to load all files in the folder.
Important
If you use wildcard characters or use only the folder name, verify that no unwanted files will be loaded or the COPY command will fail. For example, some processes might write a log file to the output folder.
