Invocaciones de modelos
La observabilidad de la IA generativa de CloudWatch le permite monitorear el rendimiento de las invocaciones de modelos. Puede hacer un seguimiento de métricas como el recuento de invocaciones, el uso de tokens y los errores mediante vistas listas para usar. Para obtener una visibilidad detallada del contenido de la invocación, como las entradas y las salidas, habilite el registro de invocación de Bedrock y envíe los registros a CloudWatch. Para más información, consulte Configuración de un destino de CloudWatch Logs y Ayuda para proteger los datos de registro confidenciales con el enmascaramiento.
Activación de la invocación de modelos en Amazon Bedrock
nota
Debe activar el registro de invocación del modelo en Amazon Bedrock para ver las invocaciones.
Haga lo siguiente para activar el registro de invocaciones de modelos en Amazon Bedrock:
Abra la consola de Amazon Bedrock en https://console.aws.amazon.com/bedrock/
. Elija Configuración.
En Registro de invocaciones de modelos, seleccione Registro de invocaciones de modelos.
Elija los tipos de datos necesarios para incluirlos en los registros. Elija enviar los registros solo a CloudWatch Logs o a Amazon S3 y CloudWatch Logs.
En las configuraciones de CloudWatch Logs, cree el nombre del grupo de registros y seleccione los roles de servicio adecuados.
Elija los tipos de datos necesarios para incluirlos en los registros.
Elija Guardar configuración.
Puede ver los paneles preconfigurados automáticamente cuando comience a utilizar las invocaciones de Amazon Bedrock. Tras activar
Model Invocation logging, podrá ver los paneles predeterminados y acceder a la tabla de invocación situada debajo de estos.

Recuento de invocaciones: número de solicitudes hechas correctamente a las operaciones de las API Converse, ConverseStream, InvokeModel yInvokeModelWithResponseStream
Latencia de invocación: latencia de las invocaciones
Recuentos de tokens por modelo: recuentos de tokens por modelo delineados por los recuentos de tokens de entrada y salida
Recuentos diarios de tokens por ID de modelo: recuentos totales diarios de tokens por ID de modelo
InputTokenCount, OutputTokenCount: número total de tokens en la entrada y la salida de esta cuenta en los modelos seleccionados
Solicitudes agrupadas por tokens de entrada: número de solicitudes agrupadas por tokens de entrada en 6 rangos. Cada línea representa el número de solicitudes que se encuentran en un rango determinado
Límites de invocación: número de invocaciones que el sistema ha limitado. El número de limitaciones que vea dependerá de la configuración de reintentos del SDK. Para más información, consulte el comportamiento de Retry en la Guía de referencia de herramientas y SDK de AWS
Recuento de errores de invocación: recuento de las invocaciones que provocan errores del lado del servidor y del lado del cliente
Haga esto para utilizar el panel de invocación del modelo:
Pase el ratón sobre cualquier gráfico de métricas para ver los detalles de la invocación. Puede seleccionar el icono de Alarm para configurar
Alarmsy monitorear la calidad y el rendimiento de la aplicación. Para más información acerca de las alarmas, consulte Alarmas. Para más información sobre las métricas, consulte Métricas de tiempo de ejecución de Amazon Bedrock.En el menú desplegable ModelID, puede seleccionar un ID de modelo para ver las métricas correspondientes.
Seleccione Ver en las métricas de CloudWatch para ver las métricas del panel en CloudWatch.
Seleccione Anulación de periodo para ajustar el plazo de las métricas (por ejemplo, 1 minuto, 1 hora o 6 horas).
En Invocaciones, seleccione ID de solicitud para ver los detalles de la solicitud. Puede ver los detalles de entrada y salida de las invocaciones del modelo en el panel derecho.
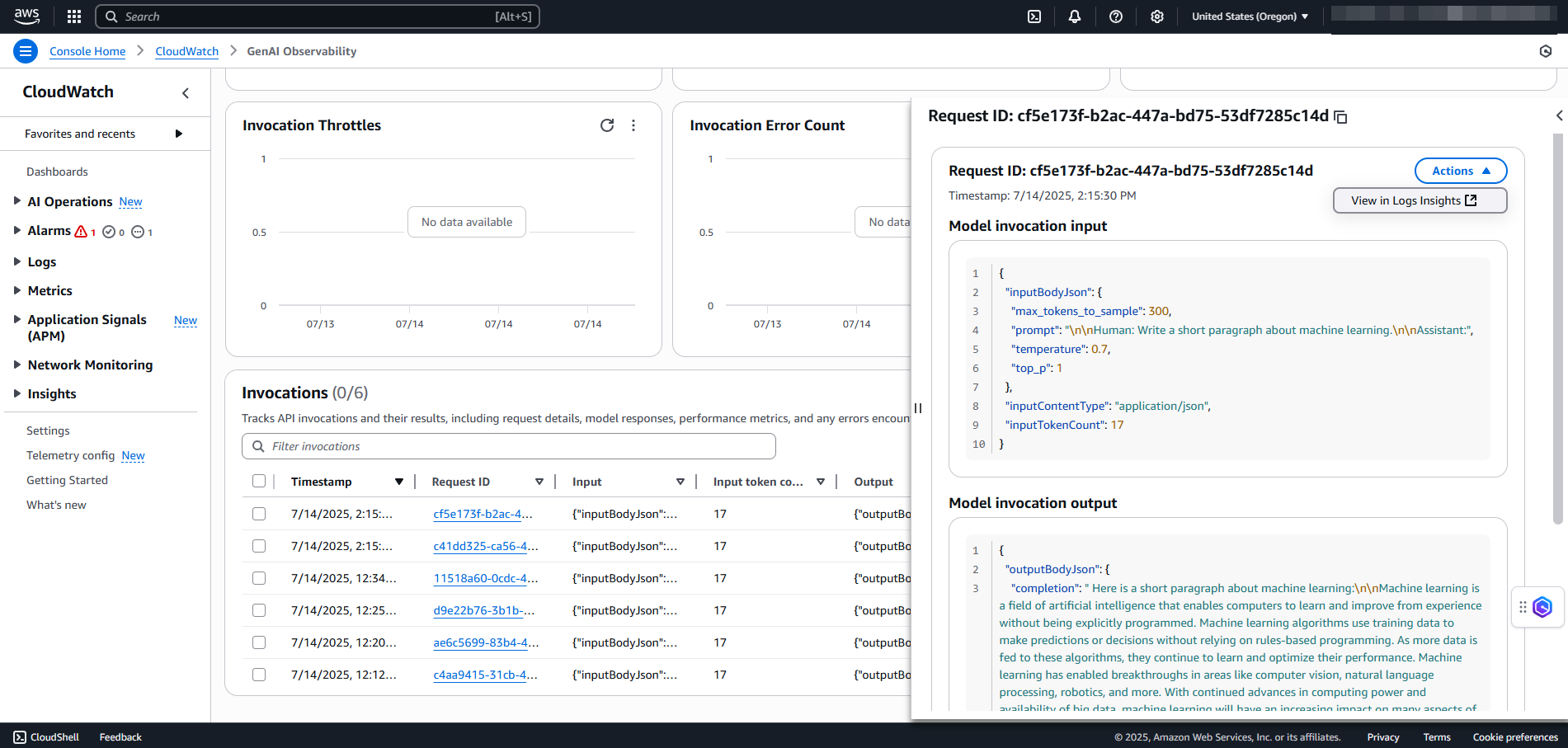
En la página ID de solicitud, en el menú desplegable Acciones, seleccione Ver en Logs Insights para ver los registros en CloudWatch. Para obtener más información, consulte Análisis de los datos de registros con Información de registros de Amazon CloudWatch.
