Clonación de un volumen de clúster de base de datos de Amazon Aurora
Con la clonación de Aurora, puede crear un nuevo clúster que utilice inicialmente las mismas páginas de datos que el original y sea un volumen independiente. El proceso está diseñado para ser rápido y rentable. El nuevo clúster con su volumen de datos asociado se conoce como clon. La creación de un clon es más rápido y más eficiente en el espacio que copiar físicamente los datos mediante una técnica diferente, como la restauración de una instantánea.
Temas
Información general de la clonación de Aurora
Aurora utiliza un protocolo de copia en escritura para crear un clon. Este mecanismo utiliza un espacio adicional mínimo para crear un clon inicial. Cuando se crea el clon por primera vez, Aurora guarda una sola copia de los datos que utiliza el clúster de base de datos de Aurora de origen y el nuevo clúster de base de datos de Aurora (clonado). El almacenamiento adicional solo se asigna cuando el clúster de base de datos de Aurora de origen o el clon del clúster de base de datos de Aurora realizan cambios en los datos (en el volumen de almacenamiento de Aurora). Para obtener más información sobre el protocolo de copia en escritura, consulte Cómo funciona la clonación de Aurora.
La clonación de Aurora es especialmente útil para configurar rápidamente entornos de prueba mediante sus datos de producción, sin riesgo de corrupción de datos. Puede utilizar clones para muchos tipos de aplicaciones de corta duración, como las siguientes:
-
Experimente con cambios potenciales (por ejemplo, cambios de esquema y cambios de grupo de parámetros) para evaluar todos los impactos.
-
Realice operaciones intensivas de carga de trabajo, como exportar datos o ejecutar consultas analíticas en el clon.
-
Cree una copia del clúster de base de datos de producción para desarrollo, pruebas u otros fines.
Puede crear más de un clon desde el mismo clúster de base de datos de Aurora. También puede crear varios clones desde otro clon.
Después de crear un clon de Aurora, puede configurar las instancias de base de datos de Aurora de forma diferente al clúster de base de datos de Aurora de origen. Por ejemplo, es posible que no necesite un clon con fines de desarrollo para cumplir con los mismos requisitos de alta disponibilidad que el clúster de base de datos Aurora de producción de origen. En este caso, puede configurar el clon con una única instancia de base de datos de Aurora en lugar de las múltiples instancias de base de datos utilizadas por el clúster de base de datos de Aurora.
Cuando crea un clon con una configuración de implementación diferente a la de origen, el clon se crea con la versión secundaria más reciente del motor de base de datos Aurora.
Cuando crea clones desde sus clústeres de base de datos de Aurora, los clones se crean en su cuenta de:AWS la misma cuenta que posee el clúster de base de datos de Aurora de origen. Sin embargo, también puede compartir clústeres y clones de base de datos de Aurora DB aprovisionados y de Aurora Serverless v2 con otras cuentas de AWS. Para obtener más información, consulte Clonación entre cuentas con AWS RAM y Amazon Aurora.
Cuando termine de utilizar el clon para realizar pruebas, desarrollo u otros fines, puede eliminarlo.
Limitaciones de la clonación de Aurora
La clonación de Aurora tiene las siguientes limitaciones:
-
Puede crear tantos clones como desee, hasta el número máximo de clústeres de base de datos permitido en la Región de AWS.
-
Puede crear hasta 15 clones con protocolo de copia en escritura. Después de crear 15 clones, el siguiente clon que se cree es una copia completa. El protocolo de copia completa actúa como una recuperación en un momento dado.
-
No se puede crear un clon en una región de AWS distinta a la del clúster de base de datos de Aurora de origen.
-
No se puede crear un clon desde un clúster de base de datos de Aurora sin la característica de consulta paralela a un clúster que utiliza consulta paralela. Para llevar datos a un clúster que utiliza la consulta paralela, cree una instantánea del clúster original y restáurela al clúster donde está habilitada la característica de consulta paralela.
-
No se puede crear un clon desde un clúster de base de datos de Aurora que no tiene instancias de base de datos. Solo se pueden clonar clústeres de base de datos de Aurora que tengan al menos una instancia de base de datos.
-
Se puede crear un clon en una Virtual Private Cloud (VPC) diferente de la del clúster de base de datos de Aurora. Sin embargo, las subredes de esas VPC deben estar asignadas al mismo conjunto de zonas de disponibilidad.
-
Puede crear un clon aprovisionado de Aurora desde un clúster de base de datos de Aurora aprovisionado.
-
Los clústeres con instancias de Aurora Serverless v2 siguen las mismas reglas que los clústeres aprovisionados.
-
En:Aurora Serverless v1
-
Puede crear un clon aprovisionado desde un clúster de base de datos de Aurora Serverless v1.
-
Puede crear un clon de Aurora Serverless v1 desde un clúster de base de datos aprovisionado o de Aurora Serverless v1.
-
No se puede crear un clon de Aurora Serverless v1 a partir de un clúster de base de datos de Aurora aprovisionado no cifrado.
-
La clonación entre cuentas actualmente no admite la clonación de clústeres de base de datos de Aurora Serverless v1. Para obtener más información, consulte Limitaciones de la clonación entre cuentas.
-
Un clúster de base de datos de Aurora Serverless v1 clonado tiene el mismo comportamiento y limitaciones que cualquier clúster de base de datos de Aurora Serverless v1. Para obtener más información, consulte Uso de Amazon Aurora Serverless v1.
-
Los clústeres de base de datos de Aurora Serverless v1 están siempre cifrados. Cuando clona un clúster de base de datos de de Aurora Serverless v1 en un clúster de base de datos de Aurora aprovisionado, el clúster de de base de datos de Aurora aprovisionado está cifrado. Puede elegir la clave de cifrado, pero no puede desactivar el cifrado. Para crear un clon aprovisionado de base de datos de Aurora a un Aurora Serverless v1, debe hacerlo a partir de un clúster de base de datos de Aurora cifrado y aprovisionado.
-
Cómo funciona la clonación de Aurora
La clonación de Aurora funciona en la capa de almacenamiento de un clúster de base de datos de Aurora. Utiliza un protocolo copy-on-write que es rápido y eficiente en el espacio en términos de los medios permanentes subyacentes que soportan el volumen de almacenamiento de Aurora. Puede obtener más información sobre volúmenes de clúster de Aurora en Información general del almacenamiento de Amazon Aurora.
Descripción del protocolo de copia en escritura
Un clúster de base de datos de Aurora almacena datos en páginas en el volumen de almacenamiento de Aurora subyacente.
Por ejemplo, en el siguiente diagrama puede encontrar un clúster de base de datos de Aurora (A) que tiene cuatro páginas de datos, 1, 2, 3 y 4. Imagine que un clon, B, se crea desde del clúster de base de datos de Aurora. Cuando se crea el clon, no se copian datos. Más bien, el clon apunta al mismo conjunto de páginas que el clúster de base de datos de Aurora de origen.
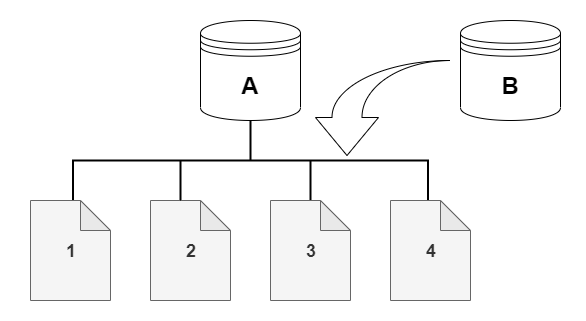
Cuando se crea el clon, generalmente no se necesita almacenamiento adicional. El protocolo de copia en escritura utiliza el mismo segmento en los medios de almacenamiento físico que el segmento de origen. Solo se requiere almacenamiento adicional si la capacidad del segmento de origen no es suficiente para todo el segmento de clones. Si ese es el caso, el segmento de origen se copia en otro dispositivo físico.
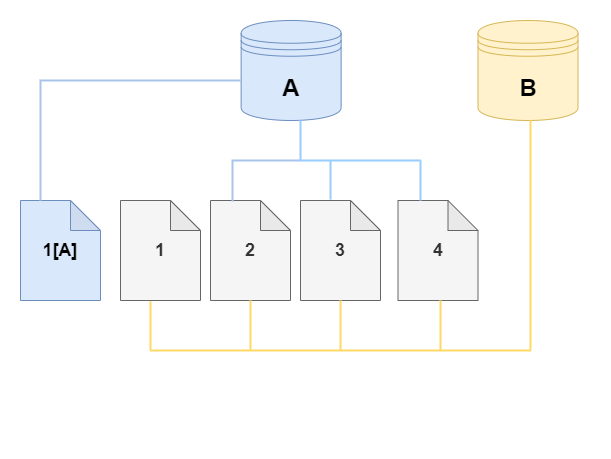
En los diagramas siguientes, puede encontrar un ejemplo del protocolo de copia en escritura en acción utilizando el mismo clúster A y su clon B, como se muestra anteriormente. Supongamos que realiza un cambio en su clúster de base de datos de Aurora (A) que da lugar a un cambio en los datos almacenados en la página 1. En lugar de escribir en la página original 1, Aurora crea una nueva página 1 [A]. El volumen del clúster de base de datos de Aurora para el clúster (A) ahora apunta a la página 1 [A], 2, 3 y 4, mientras que el clon (B) sigue haciendo referencia a las páginas originales.
En el clon, se realiza un cambio en la página 4 del volumen de almacenamiento. En lugar de escribir en la página original 4, Aurora crea una nueva página 4 [B]. El clon ahora apunta a las páginas 1, 2, 3 y a la página 4 [B], mientras que el clúster (A) continúa apuntando a 1 [A], 2, 3 y 4.
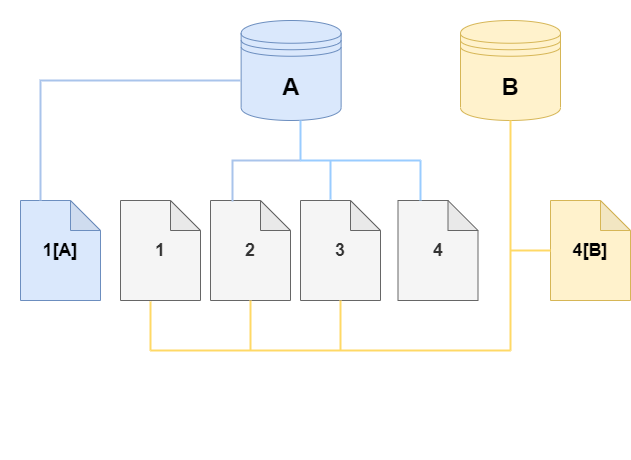
A medida que se producen más cambios a lo largo del tiempo en el clon y el volumen del clúster de base de datos de Aurora de origen, necesitará cada vez más almacenamiento para capturar y almacenar los cambios.
Eliminación de un volumen del clúster de origen
Inicialmente, el volumen de clon comparte las mismas páginas de datos que el volumen original a partir del cual se crea el clon. Mientras exista el volumen original, el volumen del clon solo se considera propietario de las páginas que el clon ha creado o modificado. Por lo tanto, la métrica VolumeBytesUsed del volumen del clon comienza siendo pequeña y solo aumenta a medida que los datos divergen entre el clúster original y el clon. En el caso de páginas idénticas entre el volumen de origen y el clon, los cargos de almacenamiento se aplican únicamente al clúster original. Para obtener más información acerca de la métrica VolumeBytesUsed, consulte Métricas de nivel de clúster para Amazon Aurora.
Cuando elimina un volumen de clúster de origen que tiene uno o más clones asociados, los datos en los volúmenes del clúster de los clones no cambian. Aurora conserva las páginas que antes pertenecían al volumen del clúster de origen. Aurora redistribuye la facturación del almacenamiento de las páginas que pertenecían al clúster eliminado. Por ejemplo, supongamos que un clúster original tenía dos clones y, después, se eliminó el clúster original. La mitad de las páginas de datos que pertenecían al clúster original ahora pertenecerían a un clon. La otra mitad de las páginas pertenecería al otro clon.
Si elimina el clúster original, a medida que crea o elimina más clones, Aurora sigue redistribuyendo la propiedad de las páginas de datos entre todos los clones que comparten las mismas páginas. Por lo tanto, es posible que observe que el valor de la métrica VolumeBytesUsed cambia para el volumen del clúster de un clon. El valor de la métrica puede disminuir a medida que se crean más clones y la propiedad de la página se distribuye entre más clústeres. El valor de la métrica también puede aumentar a medida que se eliminan los clones y se asigna la propiedad de la página a una cantidad menor de clústeres. Para obtener información sobre cómo afectan las operaciones de escritura a las páginas de datos de los volúmenes de clones, consulte Descripción del protocolo de copia en escritura.
Cuando el clúster original y los clones pertenecen a la misma cuenta de AWS, todos los cargos de almacenamiento de esos clústeres se aplican a esa misma cuenta de AWS. Si algunos de los clústeres son clones entre cuentas, eliminar el clúster original puede conllevar cargos de almacenamiento adicionales a las cuentas de AWS que poseen los clones entre cuentas.
Por ejemplo, supongamos que un volumen de clúster tiene 1000 páginas de datos usados antes de crear cualquier clon. Al clonar ese clúster, inicialmente el volumen del clon no tiene ninguna página utilizada. Si el clon modifica 100 páginas de datos, solo esas 100 páginas se almacenan en el volumen del clon y se marcan como usadas. Las otras 900 páginas sin cambios del volumen principal se comparten entre ambos clústeres. En este caso, el clúster principal tiene cargos de almacenamiento para 1000 páginas y el volumen del clon para 100 páginas.
Si elimina el volumen de origen, los cargos de almacenamiento del clon incluyen las 100 páginas modificadas, más las 900 páginas compartidas del volumen original, lo que da un total de 1000 páginas.
Creación de un clon de Amazon Aurora
Puede crear un clon en la misma cuenta de AWS como clúster de base de datos de Aurora de origen. Para ello, puede utilizar la AWS Management Console o la AWS CLI, y los procedimientos siguientes.
Para permitir que otra cuenta de AWS cree un clon o comparta un clon con otra cuenta de AWS, utilice los procedimientos en Clonación entre cuentas con AWS RAM y Amazon Aurora.
El siguiente procedimiento describe cómo clonar un clúster de base de datos de Aurora mediante la AWS Management Console.
Al crear un clon con la AWS Management Console resulta en un clúster de base de datos de Aurora con una instancia de base de datos de Aurora.
Estas instrucciones se aplican a los clústeres de base de datos que pertenecen a la misma AWS cuenta que crea la clonación. Si el clúster de base de datos es propiedad de otra AWS cuenta, consulte Clonación entre cuentas con AWS RAM y Amazon Aurora en su lugar.
Para crear un clon de un clúster de base de datos propiedad de la AWS cuenta mediante el comando AWS Management Console
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. En el panel de navegación, seleccione Databases (Bases de datos).
Elija su clúster de base de datos de Aurora de la lista y para Actions (Acciones), elija Create clone (Crear clon).
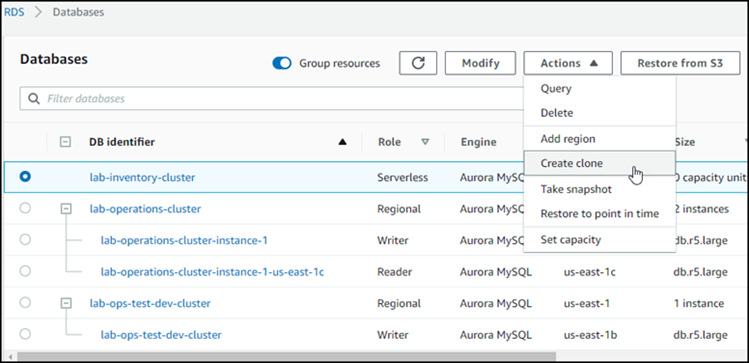
Se abre la página Crear clon donde puede configurar Configuración, Conectividad y otras opciones para el clon del clúster de base de datos de Aurora.
-
Para el identificador de instancia de base de datos, indique el nombre que desea asignar a su clúster de base de datos de Aurora clonado.
Para los clústeres de bases de datos de Aurora Serverless v1, elija Aprovisionado o Sin servidor como Tipo de capacidad.
Puede elegir Serverless (Sin servidor) solo si el clúster de base de datos de Aurora de origen es una clúster de base de datos de Aurora Serverless v1 o es un clúster de base de datos de Aurora aprovisionado que está cifrado.
-
Para los clústeres de bases de datos de Aurora Serverless v2 o aprovisionados, elija Aurora I/O-Optimized o Aurora Standard para Configuración de almacenamiento del clúster.
Para obtener más información, consulte Configuraciones de almacenamiento para los clústeres de base de datos de Amazon Aurora.
-
Elija el tamaño de la instancia de base de datos o la capacidad del clúster de base de datos:
-
Para un clon aprovisionado, elija una Clase de instancia de base de datos.

Puede aceptar la configuración proporcionada o puede usar una clase de instancia de base de datos diferente para su clon.
-
Para un clon de Aurora Serverless v1 o Aurora Serverless v2, elija la Configuración de capacidad.
Puede aceptar la configuración proporcionada o cambiarla para su clon.
-
-
Seleccione el resto de ajustes según sea necesario para su clon. Para obtener más información sobre la configuración del clúster y de la instancia de base de datos de Aurora, consulte Creación de un clúster de base de datos de Amazon Aurora.
-
Elija Crear clon.
Cuando se crea el clon, aparece junto con los otros clústeres de base de datos de Aurora en la sección Databases (Bases de datos) de la consola y muestra su estado actual. Su clon está listo para utilizar cuando su estado es Available (Disponible).
El uso de la AWS CLI para clonar el clúster de base de datos de Aurora implica pasos separados para crear el clúster de clones y agregarle una o más instancias de base de datos.
El comando restore-db-cluster-to-point-in-time de la AWS CLI que utiliza produce un clúster de base de datos de Aurora con los mismos datos de almacenamiento que el clúster original, pero ninguna instancia de base de datos de Aurora. Se crean instancias de base de datos por separado después de que el clon esté disponible. Puede elegir el número de instancias de base de datos y sus clases de instancias para dar al clon una capacidad de procesamiento mayor o menor que la del clúster original. Los pasos del proceso son los siguientes:
-
Cree el clon mediante el comando restore-db-clúster-to-point-in-time de la CLI.
-
Cree la instancia de base de datos de escritor para el clon con el comando de la CLI create-db-instance.
-
(Opcional) Ejecute comandos de la CLI create-db-instance adicionales para agregar una o más instancias de lector al clúster de clones. El uso de instancias de lector ayuda a mejorar los aspectos de alta disponibilidad y escalabilidad de lectura del clon. Puede omitir este paso si tiene pensado utilizar el clon para el desarrollo y las pruebas.
Temas
Creación del clon
Utilice el comando de la CLI restore-db-cluster-to-point-in-time para crear el clúster de clones inicial.
Creación de un clon desde un clúster de base de datos de Aurora de origen
-
Utilice el comando CLI
restore-db-cluster-to-point-in-time. Especifique los valores de los siguientes parámetros. En este caso típico, el clon utiliza el mismo modo de motor que el clúster original, ya sea aprovisionado o Aurora Serverless v1.-
--db-cluster-identifier: elija un nombre significativo para su clon. Se asigna un nombre al clon cuando se utiliza el comando restore-db-clúster-to-point-in-time de la CLI. A continuación, pase el nombre del clon en el comando create-db-instance de la CLI. -
--restore-type: utilicecopy-on-writepara crear un clon del clúster de base de datos de origen. Sin este parámetro,restore-db-cluster-to-point-in-timerestaura el clúster de base de datos de Aurora en lugar de crear un clon. -
--source-db-cluster-identifier: utilice el nombre del clúster de base de datos de Aurora de origen que desea clonar. -
--use-latest-restorable-time: este valor apunta a los datos de volumen restaurables más recientes para el clúster de base de datos de origen. Úselo para crear clones.
-
El siguiente ejemplo crea un clon del clúster de denominado my-clone desde un clúster denominado my-source-cluster.
Para Linux, macOS o Unix:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --restore-type copy-on-write \ --use-latest-restorable-time
Para Windows:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --restore-type copy-on-write ^ --use-latest-restorable-time
El comando devuelve el objeto JSON que contiene detalles del clon. Compruebe que su clúster de base de datos clonado está disponible antes de intentar crear la instancia de base de datos para su clon. Para obtener más información, consulte Comprobación del estado y obtención de detalles del clon.
Por ejemplo, supongamos que tiene un clúster llamado tpch100g que desea clonar. En el siguiente ejemplo de Linux, se crea un clúster clonado denominado tpch100g-clone, una instancia de escritor de Aurora Serverless v2 denominada tpch100g-clone-instance y una instancia de lector aprovisionada denominada tpch100g-clone-instance-2 para el nuevo clúster.
No es necesario proporcionar algunos parámetros, como --master-username y --master-user-password. Aurora determina automáticamente los parámetros del clúster original. Es necesario especificar el motor de base de datos que se va a utilizar. Por lo tanto, el ejemplo prueba el nuevo clúster para determinar el valor correcto a utilizar para el parámetro --engine.
En este ejemplo también se incluye la opción --serverless-v2-scaling-configuration al crear el clúster de clones. De esta forma, puede agregar instancias de Aurora Serverless v2 al clon aunque el clúster original no usara Aurora Serverless v2.
$aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifier tpch100g \ --db-cluster-identifier tpch100g-clone \ --serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16\ --restore-type copy-on-write \ --use-latest-restorable-time$aws rds describe-db-clusters \ --db-cluster-identifier tpch100g-clone \ --query '*[].[Engine]' \ --output textaurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.serverless \ --engine aurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance-2 \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.r6g.2xlarge \ --engine aurora-mysql
Para crear un clon en un modo de motor distinto al del clúster de base de datos de Aurora de origen.
-
Este procedimiento solo se aplica a las versiones de motor anteriores que admitan Aurora Serverless v1. Supongamos que tiene un clúster de Aurora Serverless v1 y quiere crear un clon que sea un clúster aprovisionado. En ese caso, utilice el comando de la CLI
restore-db-cluster-to-point-in-timey especifique valores de parámetros similares a los del ejemplo anterior, además de estos parámetros adicionales:-
--engine-mode: utilice este parámetro solo para crear clones que sean de un modo de motor diferente al del clúster de base de datos de Aurora de origen. Este parámetro solo se aplica a las versiones de motor anteriores que admitan Aurora Serverless v1. Elija el valor con el que se va a pasar--engine-modede la siguiente manera:-
Utilice
--engine-mode provisionedpara crear un clon de clúster de base de datos de Aurora aprovisionado desde un clúster de base de datos de Aurora Serverless.nota
Si tiene pensado utilizar Aurora Serverless v2 con un clúster que se clonó desde Aurora Serverless v1, siga especificando el modo de motor del clon como
provisioned. A continuación, debe realizar pasos adicionales de actualización y migración. -
Utilice
--engine-mode serverlesspara crear un clon de Aurora Serverless v1 desde un clúster de base de datos de Aurora aprovisionado. Cuando se especifica el modo de motorserverless, también puede elegir la--scaling-configuration.
-
-
--scaling-configuration: (opcional) se utiliza con--engine-mode serverlesspara configurar la capacidad mínima y máxima de un clon de Aurora Serverless v1. Si no utiliza este parámetro, Aurora crea un clon de Aurora Serverless v1 con los valores de capacidad de Aurora Serverless v1 predeterminados del motor de base de datos.
-
El siguiente ejemplo crea un clon aprovisionado denominado my-clone desde un clúster de base de datos de Aurora Serverless v1 denominado my-source-cluster.
Para Linux, macOS o Unix:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --engine-mode provisioned \ --restore-type copy-on-write \ --use-latest-restorable-time
Para Windows:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --engine-mode provisioned ^ --restore-type copy-on-write ^ --use-latest-restorable-time
Estos comandos devuelven el objeto JSON que contiene detalles del clon que necesita para crear la instancia de base de datos. No puede hacer eso hasta que el estado del clon (el clúster vacío de base de datos de Aurora) tenga el estado Available (Disponible).
nota
El comando restore-db-clúster-to-point-in-time de la CLI de AWS solo restaura el clúster de la base de datos, no las instancias de base de datos dicho clúster. Ejecute el comando create-db-instance para crear instancias de base de datos para el clúster de base de datos restaurado. Con ese comando, especifique el identificador del clúster de base de datos restaurado como parámetro --db-cluster-identifier. Solo puede crear instancias de base de datos después de que se haya completado el comando restore-db-cluster-to-point-in-time y de que el clúster de base de datos esté disponible.
Suponga que comienza con un clúster de Aurora Serverless v1 y tiene la intención de migrarlo a un clúster de Aurora Serverless v2. Como paso inicial de la migración, debe crear un clon aprovisionado del clúster de Aurora Serverless v1. Para ver el procedimiento completo, incluidas las actualizaciones de la versión necesarias, consulte Actualización de un clúster de Aurora Serverless v1 a Aurora Serverless v2.
Comprobación del estado y obtención de detalles del clon
Puede utilizar el siguiente comando para verificar el estado del clúster de clones recién creado.
$aws rds describe-db-clusters --db-cluster-identifiermy-clone--query '*[].[Status]' --output text
O puede obtener el estado y los otros valores que necesita paracrear la instancia de base de datos para su clon mediante el uso de la siguiente consulta de la AWS CLI.
Para Linux, macOS o Unix:
aws rds describe-db-clusters --db-cluster-identifiermy-clone\ --query '*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}'
Para Windows:
aws rds describe-db-clusters --db-cluster-identifiermy-clone^ --query "*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}"
Esta consulta devuelve un resultado similar al siguiente:
[ { "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "8.0.mysql_aurora.3.04.1", "EngineMode": "provisioned" } ]
Crear la instancia de base de datos de Aurora para su clon
Use el comando create-db-instance de la CLI para crear la instancia de base de datos para su clon de Aurora Serverless v2 o aprovisionado. No se crea una instancia de base de datos para un clon de Aurora Serverless v1.
La instancia de base de datos hereda las propiedades --master-username y --master-user-password del clúster de base de datos de origen.
El siguiente ejemplo crea una instancia de base de datos para un clon aprovisionado.
Para Linux, macOS o Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-classdb.r6g.2xlarge\ --engine aurora-mysql
Para Windows:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-classdb.r6g.2xlarge^ --engine aurora-mysql
En el siguiente ejemplo, se crea una instancia de base de datos de Aurora Serverless v2 para un clon que utiliza una versión del motor que admite Aurora Serverless v2.
Para Linux, macOS o Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-class db.serverless \ --engine aurora-postgresql
Para Windows:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-class db.serverless ^ --engine aurora-mysql
Parámetros para utilizar durante la clonación
En la siguiente tabla se resumen los diversos parámetros utilizados con restore-db-cluster-to-point-in-time para clonar clústeres de base de datos de Aurora.
| Parámetro | Descripción |
|---|---|
|
|
Utilice el nombre del clúster de base de datos de Aurora de origen que desea clonar. |
|
|
Elija un nombre significativo para su clon al crearlo con el comando |
|
|
Especifique |
|
|
Este valor apunta a los datos de volumen restaurables más recientes para el clúster de base de datos de origen. Úselo para crear clones. |
|
|
(Versiones más recientes que admiten Aurora Serverless v2) Utilice este parámetro para configurar la capacidad mínima y máxima de un clon de Aurora Serverless v2. Si no especifica este parámetro, no podrá crear ninguna instancia de Aurora Serverless v2 en el clúster de clones hasta que modifique el clúster para agregar este atributo. |
|
|
(Versiones anteriores que admiten solo Aurora Serverless v1) Utilice este parámetro para crear clones que sean de un tipo diferente al del clúster de base de datos de Aurora de origen, con uno de los siguientes valores:
|
|
|
(Versiones anteriores que admiten solo Aurora Serverless v1) Utilice este parámetro para configurar la capacidad mínima y máxima de un clon de Aurora Serverless v1. Si no especifica este parámetro, Aurora crea el clon con los valores de capacidad predeterminados del motor de base de datos. |
Para obtener información sobre la clonación entre VPC y entre cuentas, consulte las siguientes secciones.
