Monitoreo de una base de datos global de Amazon Aurora
Al crear los clústeres de base de datos Aurora que componen la base de datos Aurora global, puede elegir muchas opciones que le permitan supervisar el rendimiento del clúster de base de datos. Las opciones incluyen:
Amazon RDS Información sobre rendimiento – Permite el esquema de rendimiento en el motor de base de datos Aurora subyacente. Para obtener más información sobre la información sobre rendimiento y bases de datos Aurora globales, consulte Supervisión de una base de datos Amazon Aurora global con Amazon RDS la información sobre rendimiento.
Supervisión mejorada – Genera métricas para la utilización de procesos o subprocesos en la CPU. Para obtener más información sobre la supervisión mejorada, consulte Supervisión de las métricas del sistema operativo con Supervisión mejorada.
Amazon CloudWatch Logs – Publica los tipos de registro especificados en CloudWatch Logs. Los registros de errores se publican de forma predeterminada, pero puede elegir otros registros específicos del motor de base de datos Aurora.
Para los clústeres de base de datos Aurora basados en Aurora MySQL–, puede exportar el registro de auditoría, el registro general y el registro de consulta lenta.
En el caso de clústeres de base de datos de Aurora basados en Aurora PostgreSQL, puede exportar el registro de PostgreSQL.
Para bases de datos globales basadas en Aurora MySQL, puede consultar determinadas tablas
information_schemapara comprobar el estado de la base de datos global de Aurora y sus instancias. Para aprender a hacerlo, consulte Supervisión de las bases de datos globales basadas en Aurora MySQL.Para bases de datos globales basadas en Aurora PostgreSQL, puede utilizar funciones específicas para comprobar el estado de la base de datos global de Aurora y sus instancias. Para saber cómo hacerlo, consulte Supervisión de bases de datos globales basadas en Aurora PostgreSQL.
La siguiente captura de pantalla muestra algunas de las opciones disponibles en la pestaña Supervisión de un clúster de base de datos Aurora principal en una base de datos Aurora global.
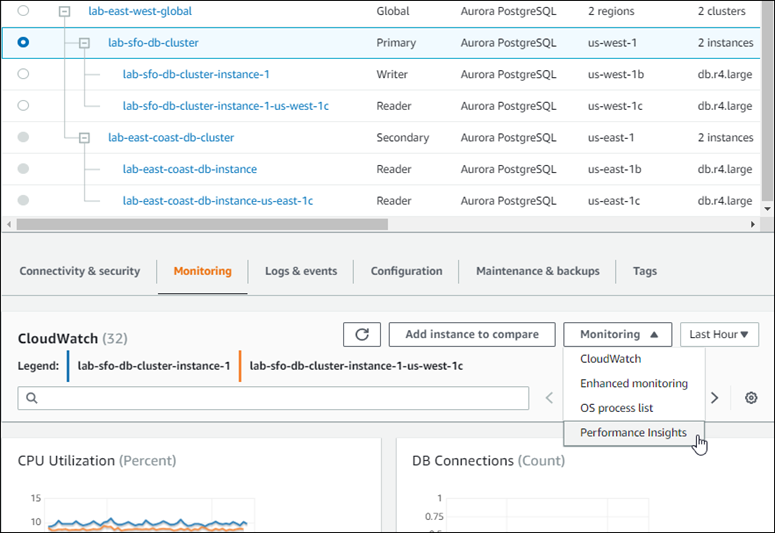
Para obtener más información, consulte Supervisión de métricas en un clúster de Amazon Aurora.
Supervisión de una base de datos Amazon Aurora global con Amazon RDS la información sobre rendimiento
Puede utilizar Amazon RDS Información sobre seguimiento para sus bases de datos globales Aurora. Esta función se habilita individualmente, para cada clúster de base de datos Aurora de la base de datos Aurora global. Para ello, elija Enable Performance Insights (Habilitar información sobre rendimiento) en la sección Additional configuration (Configuración adicional) de la página Crear base de datos. O bien, puede modificar los clústeres de base de datos de Aurora para utilizar esta característica después de que estén en funcionamiento. Puede habilitar o desactivar la información sobre rendimiento para cada clúster que forma parte de la base de datos Aurora global.
Los informes creados por la información sobre rendimiento se aplican a cada clúster de la base de datos global. Cuando agregue una nueva Región de AWS secundaria a una base de datos global de Aurora que ya está utilizando Información sobre rendimiento, habilítela en el clúster que se agregó recientemente. No hereda la configuración de Performance Insights de la base de datos global existente.
Puede cambiar Regiones de AWS mientras ve la página de Información sobre rendimiento para una instancia de base de datos que está conectada a una base de datos global. Sin embargo, es posible que no vea la información sobre rendimiento de inmediato después del cambio de Regiones de AWS. Aunque las instancias de base de datos pueden tener nombres idénticos en cada Región de AWS, la URL de Información sobre rendimiento asociada es distinta para cada instancia de base de datos. Después de cambiar las Regiones de AWS, elija el nombre de la instancia de base de datos de nuevo en el panel de navegación de Información sobre rendimiento.
Para las instancias de base de datos asociadas a una base de datos global, los factores que afectan al rendimiento pueden ser distintos en cada Región de AWS. Por ejemplo, las instancias de base de datos en cada Región de AWS pueden tener una capacidad diferente.
Para obtener más información sobre el uso de la información sobre rendimiento, consulte Monitoreo de la carga de base de datos con Performance Insights en Amazon Aurora.
Supervisión de bases de datos globales Aurora mediante las secuencias de actividad de base de datos
Utilizando la característica de secuencias de actividad de base de datos, puede supervisar y establecer alarmas para auditar la actividad en los clústeres de base de datos de su base de datos global. Se inicia una secuencia de actividad de base de datos en cada clúster de base de datos por separado. Cada clúster suministra datos de auditoría a su propio flujo de Kinesis dentro de su propia Región de AWS. Para obtener más información, consulte Supervisión de Amazon Aurora con flujos de actividad de la base de datos.
Supervisión de las bases de datos globales basadas en Aurora MySQL
Para ver el estado de una base de datos global basada en Aurora MySQL, consulte las tablas information_schema.aurora_global_db_status y information_schema.aurora_global_db_instance_status.
nota
Las tablas information_schema.aurora_global_db_status y information_schema.aurora_global_db_instance_status solo están disponibles para las bases de datos globales de la versión 3.04.0 y posteriores de Aurora MySQL.
Para supervisar una base de datos global basada en Aurora MySQL
-
Conéctese al punto de conexión del clúster principal de la base de datos global mediante un cliente MySQL. Para obtener más información acerca de cómo conectarse, consulte Conexión a la base de datos global de Amazon Aurora.
-
Utilice la tabla
information_schema.aurora_global_db_statusen un comando psql para enumerar los volúmenes primario y secundario. Esta consulta devuelve los tiempos de retraso de los clústeres de bases de datos secundarios de la base de datos global, como en el siguiente ejemplo.mysql> select * from information_schema.aurora_global_db_status;AWS_REGION | HIGHEST_LSN_WRITTEN | DURABILITY_LAG_IN_MILLISECONDS | RPO_LAG_IN_MILLISECONDS | LAST_LAG_CALCULATION_TIMESTAMP | OLDEST_READ_VIEW_TRX_ID -----------+---------------------+--------------------------------+------------------------+---------------------------------+------------------------ us-east-1 | 183537946 | 0 | 0 | 1970-01-01 00:00:00.000000 | 0 us-west-2 | 183537944 | 428 | 0 | 2023-02-18 01:26:41.925000 | 20806982 (2 rows)El resultado incluye una fila para cada clúster de base de datos de la base de datos global que contiene las siguientes columnas:
-
AWS_REGION: la Región de AWS donde está este clúster de base de datos. Para ver tablas que muestres las Regiones de AWS por motor, consulte Disponibilidad por región.
-
HIGHEST_LSN_WRITTEN: el número de secuencia de registro (LSN) más alto escrito actualmente en este clúster de base de datos.
Un número de secuencia de registro (LSN) es un número secuencial único que identifica un registro en el registro de transacciones de la base de datos. Los LSN se ordenan de tal manera que un LSN más grande representa una transacción posterior.
-
DURABILITY_LAG_IN_MILLISECONDS: la diferencia en los valores de marca temporal entre el
HIGHEST_LSN_WRITTENde un clúster de base de datos secundario y elHIGHEST_LSN_WRITTENdel clúster de base de datos principal. Este valor es siempre 0 en el clúster de base de datos principal de la base de datos global de Aurora. -
RPO_LAG_IN_MILLISECONDS: el retraso del objetivo de punto de recuperación (RPO). El retardo de RPO es el tiempo que tarda la transacción de usuario más reciente en almacenarse en un clúster de base de datos secundario después de almacenarse en el clúster de base de datos principal de una base de datos global de Aurora. Este valor es siempre 0 en el clúster de base de datos principal de la base de datos global de Aurora.
En términos sencillos, esta métrica calcula el objetivo de punto de recuperación de cada clúster de base de datos de Aurora MySQL de una base de datos global de Aurora, es decir, cuántos datos podrían perderse si se produce una interrupción. Al igual que con el retraso, el RPO se mide en tiempo.
-
LAST_LAG_CALCULATION_TIMESTAMP: la marca temporal que especifica cuándo se calcularon por última vez los valores para
DURABILITY_LAG_IN_MILLISECONDSyRPO_LAG_IN_MILLISECONDS. Un valor temporal como1970-01-01 00:00:00+00significa que este es el clúster de base de datos principal. -
OLDEST_READ_VIEW_TRX_ID: el ID de la transacción más antigua a la que se puede purgar la instancia de base de datos del escritor.
-
-
Utilice la tabla
information_schema.aurora_global_db_instance_statuspara enumerar todas las instancias de base de datos secundarias tanto para el clúster de base de datos principal como para los clústeres de base de datos secundarios.mysql> select * from information_schema.aurora_global_db_instance_status;SERVER_ID | SESSION_ID | AWS_REGION | DURABLE_LSN | HIGHEST_LSN_RECEIVED | OLDEST_READ_VIEW_TRX_ID | OLDEST_READ_VIEW_LSN | VISIBILITY_LAG_IN_MSEC ---------------------+--------------------------------------+------------+-------------+----------------------+-------------------------+----------------------+------------------------ ams-gdb-primary-i2 | MASTER_SESSION_ID | us-east-1 | 183537698 | 0 | 0 | 0 | 0 ams-gdb-secondary-i1 | cc43165b-bdc6-4651-abbf-4f74f08bf931 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 0 ams-gdb-secondary-i2 | 53303ff0-70b5-411f-bc86-28d7a53f8c19 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 677 ams-gdb-primary-i1 | 5af1e20f-43db-421f-9f0d-2b92774c7d02 | us-east-1 | 183537697 | 183537698 | 20806930 | 183537691 | 21 (4 rows)El resultado incluye una fila para cada instancia de base de datos de la base de datos global que contiene las siguientes columnas:
-
SERVER_ID: el identificador del servidor de la instancia de base de datos.
-
SESSION_ID: un identificador único para la sesión actual. Un valor
MASTER_SESSION_IDidentifica la instancia de base de datos de Writer (principal). -
AWS_REGION: la Región de AWS donde está esta instancia de base de datos. Para ver tablas que muestres las Regiones de AWS por motor, consulte Disponibilidad por región.
-
DURABLE_LSN: el LSN hecho permanente en el almacenamiento.
-
HIGHEST_LSN_RECEIVED: el LSN más alto recibido por la instancia de base de datos de la instancia de base de datos del escritor.
-
OLDEST_READ_VIEW_TRX_ID: el ID de la transacción más antigua a la que puede purgar la instancia de base de datos del escritor.
-
OLDEST_READ_VIEW_LSN: el LSN más antiguo utilizado por la instancia de base de datos para leer desde el almacenamiento.
-
VISIBILITY_LAG_IN_MSEC: para los lectores del clúster de base de datos principal, cuánto se está retrasando esta instancia de base de datos con respecto a la instancia de base de datos del escritor en milisegundos. En el caso de los lectores de un clúster de base de datos secundario, cuánto se está retrasando esta instancia de base de datos respecto al volumen secundario en milisegundos.
-
Para ver cómo cambian estos valores con el tiempo, tenga en cuenta el siguiente bloque de transacciones en el que una inserción de tabla tarda una hora.
mysql> BEGIN;
mysql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
mysql> COMMIT;
En algunos casos, puede haber una desconexión de red entre el clúster de base de datos principal y el clúster de base de datos secundario después de la instrucción BEGIN. Si es así, el valor de DURABILITY_LAG_IN_MILLISECONDS del clúster de base de datos secundario comienza a aumentar. Al final de la instrucción INSERT, el valor de DURABILITY_LAG_IN_MILLISECONDS es 1 hora. Sin embargo, el valor de RPO_LAG_IN_MILLISECONDS es 0 porque todos los datos de usuario confirmados entre el clúster de base de datos principal y el clúster de base de datos secundario siguen siendo los mismos. Tan pronto como la instrucción COMMIT se completa, el valor de RPO_LAG_IN_MILLISECONDS aumenta.
Supervisión de bases de datos globales basadas en Aurora PostgreSQL
Utilice las funciones aurora_global_db_status y aurora_global_db_instance_status para ver el estado de una base de datos global basada en Aurora PostgreSQL.
nota
Solo Aurora PostgreSQL es compatible con las funciones aurora_global_db_status y aurora_global_db_instance_status.
Para supervisar una base de datos global basada en Aurora PostgreSQL
-
Conéctese al punto de enlace del clúster principal de la base de datos global mediante una utilidad PostgreSQL como psql. Para obtener más información acerca de cómo conectarse, consulte Conexión a la base de datos global de Amazon Aurora.
-
Utilice la función
aurora_global_db_statusde un comando psql para enumerar los volúmenes primario y secundario. Esto muestra los tiempos de retraso de los clústeres de bases de datos secundarios de la base de datos global.postgres=> select * from aurora_global_db_status();aws_region | highest_lsn_written | durability_lag_in_msec | rpo_lag_in_msec | last_lag_calculation_time | feedback_epoch | feedback_xmin ------------+---------------------+------------------------+-----------------+----------------------------+----------------+--------------- us-east-1 | 93763984222 | -1 | -1 | 1970-01-01 00:00:00+00 | 0 | 0 us-west-2 | 93763984222 | 900 | 1090 | 2020-05-12 22:49:14.328+00 | 2 | 3315479243 (2 rows)El resultado incluye una fila para cada clúster de base de datos de la base de datos global que contiene las siguientes columnas:
-
aws_region: la Región de AWS donde está este clúster de base de datos. Para ver tablas que muestres las Regiones de AWS por motor, consulte Disponibilidad por región.
-
highest_lsn_written: el número de secuencia de registro (LSN) más alto escrito actualmente en este clúster de base de datos.
Un número de secuencia de registro (LSN) es un número secuencial único que identifica un registro en el registro de transacciones de la base de datos. Los LSN se ordenan de tal manera que un LSN más grande representa una transacción posterior.
-
durability_lag_in_msec: la diferencia de marca temporal entre el número de secuencia de registro más alto escrito en un clúster de base de datos secundario (
highest_lsn_written) y elhighest_lsn_writtendel clúster de base de datos principal. -
rpo_lag_in_msec: el retraso del objetivo del punto de recuperación (RPO). Este retraso es la diferencia de tiempo entre la confirmación de transacción de usuario más reciente almacenada en un clúster de base de datos secundario y la confirmación de transacción de usuario más reciente almacenada en el clúster de base de datos principal.
-
last_lag_calculation_time: la marca temporal en la que se calcularon por última vez los valores para
durability_lag_in_msecyrpo_lag_in_msec. -
feedback_epoch: el tiempo que utiliza el clúster de base de datos secundario cuando genera información de la espera activa.
En espera en caliente es cuando un clúster de base de datos puede conectarse y realizar consultas mientras el servidor está en modo de recuperación o espera. La retroalimentación en espera en caliente es información sobre el clúster de base de datos cuando está en espera en caliente. Para obtener más información, consulte la documentación de PostgreSQL sobre Hot Standby
. -
feedback_xmin: el ID de transacción activa mínima (más antigua) que utiliza el clúster de base de datos secundario.
-
-
Utilice la función
aurora_global_db_instance_statuspara enumerar todas las instancias de base de datos secundarias tanto para el clúster de base de datos principal como para los clústeres de base de datos secundarios.postgres=> select * from aurora_global_db_instance_status();server_id | session_id | aws_region | durable_lsn | highest_lsn_rcvd | feedback_epoch | feedback_xmin | oldest_read_view_lsn | visibility_lag_in_msec --------------------------------------------+--------------------------------------+------------+-------------+------------------+----------------+---------------+----------------------+------------------------ apg-global-db-rpo-mammothrw-elephantro-1-n1 | MASTER_SESSION_ID | us-east-1 | 93763985102 | | | | | apg-global-db-rpo-mammothrw-elephantro-1-n2 | f38430cf-6576-479a-b296-dc06b1b1964a | us-east-1 | 93763985099 | 93763985102 | 2 | 3315479243 | 93763985095 | 10 apg-global-db-rpo-elephantro-mammothrw-n1 | 0d9f1d98-04ad-4aa4-8fdd-e08674cbbbfe | us-west-2 | 93763985095 | 93763985099 | 2 | 3315479243 | 93763985089 | 1017 (3 rows)El resultado incluye una fila para cada instancia de base de datos de la base de datos global que contiene las siguientes columnas:
-
server_id: el identificador del servidor de la instancia de base de datos.
-
session_id: un identificador único para la sesión actual.
-
aws_region: la Región de AWS donde está esta instancia de base de datos. Para ver tablas que muestres las Regiones de AWS por motor, consulte Disponibilidad por región.
-
durable_lsn: el LSN hecho permanente en el almacenamiento.
-
highest_lsn_rcvd: el LSN más alto recibido por la instancia de base de datos de la instancia de base de datos de escritor.
-
feedback_epoch: la fecha de inicio que utiliza la instancia de base de datos cuando genera información en espera en caliente.
La espera activa es cuando una instancia de base de datos puede conectarse y realizar consultas mientras el servidor está en modo de recuperación o espera. La retroalimentación en espera en caliente es información sobre la instancia de base de datos cuando está en espera en caliente. Para obtener más información, consulte la documentación de PostgreSQL sobre Hot Standby
. -
feedback_xmin: el ID de transacción activo mínimo (más antiguo) utilizado por la instancia de base de datos.
-
oldest_read_view_lsn: el LSN más antiguo utilizado por la instancia de base de datos para leer desde el almacenamiento.
-
visibility_lag_in_msec: hasta qué punto esta instancia de base de datos se está quedando por detrás de la instancia de base de datos de escritor.
-
Para ver cómo cambian estos valores con el tiempo, tenga en cuenta el siguiente bloque de transacciones en el que una inserción de tabla tarda una hora.
psql> BEGIN;
psql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
psql> COMMIT;En algunos casos, puede haber una desconexión de red entre el clúster de base de datos principal y el clúster de base de datos secundario después de la instrucción BEGIN. En tal caso, el valor del clúster de base de datos secundario durability_lag_in_msec comienza a aumentar. Al final de la instrucción INSERT, el valor durability_lag_in_msec es 1 hora. Sin embargo, el valor rpo_lag_in_msec es 0 porque todos los datos de usuario confirmados entre el clúster de base de datos principal y el clúster de base de datos secundario siguen siendo los mismos. En cuanto se complete la instrucción COMMIT, el valor rpo_lag_in_msec aumenta.
