Rendimiento y escalado para Aurora Serverless v2
Los siguientes procedimientos y ejemplos muestran cómo se puede establecer el rango de capacidad para clústeres de Aurora Serverless v2 y sus instancias de base de datos asociadas. También puede utilizar los siguientes procedimientos para supervisar la ocupación de las instancias de base de datos. A continuación, puede utilizar lo averiguado para determinar si necesita ajustar el rango de capacidad a más o a menos.
Antes de utilizar estos procedimientos, asegúrese de estar familiarizado con cómo funciona el escalado en Aurora Serverless v2. El mecanismo de escalado es diferente al de Aurora Serverless v1. Para obtener más información, consulte Escalado en Aurora Serverless v2.
Contenido
Elegir el rango de capacidad de Aurora Serverless v2 para un clúster de Aurora
Elegir la configuración de capacidad de Aurora Serverless v2 mínima para un clúster
Elegir la configuración de capacidad de Aurora Serverless v2 máxima para un clúster
Ejemplo: Cambiar el rango de capacidad de Aurora Serverless v2 de un clúster de Aurora MySQL
Ejemplo: Cambiar el rango de capacidad Aurora Serverless v2 de un clúster de Aurora PostgreSQL
Trabajo con los grupos de parámetros para Aurora Serverless v2
Métricas importantes de Amazon CloudWatch para Aurora Serverless v2
Supervisión del rendimiento de Aurora Serverless v2 con la información de rendimiento
Elegir el rango de capacidad de Aurora Serverless v2 para un clúster de Aurora
Con las instancias de base de datos Aurora Serverless v2, usted establece el rango de capacidad que se aplica a todas las instancias de base de datos del clúster de bases de datos al mismo tiempo que agrega la primera instancia de base de datos Aurora Serverless v2 en el clúster de bases de datos. Para ver el procedimiento para hacerlo, consulte Configuración del rango de capacidad de Aurora Serverless v2 para un clúster.
También puede cambiar el rango de capacidad de un clúster existente. En las siguientes secciones se explica con más detalle cómo elegir los valores mínimos y máximos adecuados y qué ocurre cuando se realiza un cambio en el rango de capacidad. Por ejemplo, cambiar el rango de capacidad puede modificar los valores predeterminados de algunos parámetros de configuración. Aplicar todos los cambios de parámetros puede requerir reiniciar cada instancia de base de datos Aurora Serverless v2.
Temas
Elegir la configuración de capacidad de Aurora Serverless v2 mínima para un clúster
Elegir la configuración de capacidad de Aurora Serverless v2 máxima para un clúster
Ejemplo: Cambiar el rango de capacidad de Aurora Serverless v2 de un clúster de Aurora MySQL
Ejemplo: Cambiar el rango de capacidad Aurora Serverless v2 de un clúster de Aurora PostgreSQL
Elegir la configuración de capacidad de Aurora Serverless v2 mínima para un clúster
Es tentador elegir siempre 0,5 para la configuración de capacidad mínima de Aurora Serverless v2. Este valor permite que la instancia de base de datos reduzca verticalmente al mínimo la capacidad cuando esté completamente inactiva y, al mismo tiempo, permanezca activa. También puede activar el comportamiento de pausa automática especificando una capacidad mínima de 0 ACU, como se explica en Escalado a cero ACU con pausa y reanudación automáticas para Aurora Serverless v2. No obstante, en función de cómo se utilice ese clúster y de los demás ajustes que se configuren, un capacidad mínima diferente podría ser lo más efectivo. Debe tener en cuenta los factores siguientes al elegir la configuración de capacidad mínima:
-
La tasa de escalado de una instancia de base de datos Aurora Serverless v2 depende de su capacidad actual. Cuanto mayor sea la capacidad actual, más rápido podrá ampliarse. Si necesita que la instancia de base de datos se amplíe rápidamente a una capacidad muy alta, piense en establecer la capacidad mínima en un valor en el que la tasa de escalado cumpla con sus requisitos.
-
Si normalmente modifica la clase de instancia de base de datos de sus instancias de base de datos en previsión de una carga de trabajo especialmente alta o baja, puede aprovechar esa experiencia para hacer una estimación aproximada del rango de capacidad de Aurora Serverless v2 equivalente. Para determinar el tamaño de la memoria que se utilizará en momentos de poco tráfico, consulte Especificaciones de hardware para clases de instancia de base de datos para Aurora.
Por ejemplo, supongamos que utiliza la clase de instancia de base de datos db.r6g.xlarge cuando el clúster tiene una carga de trabajo baja. Esta clase de instancia de base de datos tiene 32 GiB de memoria. Por lo tanto, puede especificar una configuración mínima de unidad de capacidad Aurora (ACU) de 16 para configurar una instancia de base de datos Aurora Serverless v2 que puede escalarse hacia menos a aproximadamente a la misma capacidad. Esto se debe a que cada ACU corresponde a aproximadamente 2 GiB de memoria. Puede especificar un valor algo inferior para permitir que la instancia de base de datos se amplíe aún más en caso de que la instancia de base de datos db.r6g.xlarge se haya infrautilizado a veces.
-
Si la aplicación funciona de la manera más eficiente cuando las instancias de base de datos tienen cierta cantidad de datos en la memoria caché del búfer, piense en especificar una configuración mínima de ACU en la que la memoria sea lo suficientemente grande como para contener los datos a los que se accede con frecuencia. De lo contrario, algunos datos se sacan de la memoria caché del búfer cuando las instancias de base de datos Aurora Serverless v2 se escalan a un tamaño de memoria inferior. Luego, cuando las instancias de base de datos se escalan a más, la información se vuelve a leer en la caché del búfer a lo largo del tiempo. Si la cantidad de E/S para devolver los datos a la caché del búfer es importante, podría resultar más eficaz elegir un valor de ACU mínimo más alto.
-
Si las instancias de base de datos Aurora Serverless v2 se ejecutan la mayor parte del tiempo en una capacidad determinada, piense en especificar una configuración de capacidad mínima inferior a esa línea de base, pero no muy inferior. Aurora Serverless v2 Las instancias de base de datos pueden estimar de la manera más eficaz cuánto y con qué rapidez deben ampliarse cuando la capacidad actual no es drásticamente inferior a la capacidad requerida.
-
Si la carga de trabajo aprovisionada tiene requisitos de memoria demasiado altos para clases de instancias de base de datos pequeñas como T3 o T4g, elija una configuración de ACU mínima que proporcione memoria comparable a una instancia de base de datos R5 o R6g.
En particular, recomendamos la siguiente capacidad mínima de uso con las funciones especificadas (estas recomendaciones están sujetas a cambios):
-
Performance Insights (Información sobre rendimiento): 2 ACU
-
Bases de datos globales de Aurora: 8 ACU (se aplica solo a la Región de AWS principal)
-
-
En Aurora, la replicación se produce en la capa de almacenamiento, por lo que la capacidad del lector no afecta directamente a la replicación. Sin embargo, en el caso de las instancias de bases de datos de lector de Aurora Serverless v2 que se escalan de forma independiente, asegúrese de que la capacidad mínima sea suficiente para gestionar las cargas de trabajo durante los periodos de escritura intensiva a fin de evitar la latencia de las consultas. Si las instancias de base de datos de lector en los niveles de promoción 2 a 15 experimentan problemas de rendimiento, considere aumentar la capacidad mínima del clúster. Para obtener más información sobre cómo elegir si las instancias de base de datos de lectura se escalan junto con el escritor o de manera independiente, consulte Elegir el nivel de promoción para un lector Aurora Serverless v2.
-
Si tiene un clúster de base de datos con instancias de base de datos lectoras de Aurora Serverless v2, los lectores no se escalan junto con la instancia de base de datos escritora cuando el nivel de promoción de los lectores no es 0 o 1. En ese caso, establecer una capacidad mínima baja puede provocar un retraso excesivo de la replicación. Esto se debe a que es posible que los lectores no tengan la capacidad suficiente para aplicar cambios de escritura cuando la base de datos esté ocupada. Se recomienda establecer la capacidad mínima en un valor que represente una cantidad de memoria y CPU comparables con la de la instancia de base de datos escritora.
-
El valor del parámetro
max_connectionspara las instancias de base de datos de Aurora Serverless v2 se basa en el tamaño de memoria obtenido del número máximo de ACU. Sin embargo, cuando especifique una capacidad mínima de 0 o 0,5 ACU en instancias de base de datos compatibles con PostgreSQL, el valor máximo demax_connectionsestá limitado a 2000.Si desea utilizar el clúster de Aurora PostgreSQL para una carga de trabajo de alta conexión, piense en utilizar una configuración de ACU mínima de 1 o más. Para obtener más información acerca de cómo Aurora Serverless v2 maneja el parámetro de configuración
max_connections, consulte Número máximo de conexiones para Aurora Serverless v2. -
El tiempo que se tarda en una instancia de base de datos Aurora Serverless v2 en escalar desde su capacidad mínima hasta su capacidad máxima depende de la diferencia entre sus valores de ACU mínima y máxima. Cuando la capacidad actual de la instancia de base de datos es grande, Aurora Serverless v2 se amplía en incrementos mayores que cuando la instancia de base de datos comienza desde una pequeña capacidad. Por lo tanto, si especifica una capacidad máxima relativamente grande y la instancia de base de datos está la mayor parte del tiempo cerca de esa capacidad, considere aumentar la configuración mínima de ACU. De esta forma, una instancia de base de datos inactiva podrá escalar de nuevo hasta la máxima capacidad más rápidamente.
Elegir la configuración de capacidad de Aurora Serverless v2 máxima para un clúster
Es tentador elegir siempre un valor alto para la configuración de capacidad de Aurora Serverless v2 máxima. Una alta capacidad máxima permite que la instancia de base de datos se amplíe al máximo cuando ejecuta una carga de trabajo intensiva. Un valor bajo evita la posibilidad de cobros inesperados. Según cómo utilice ese clúster y los demás ajustes que configure, el valor más efectivo podría ser mayor o menor de lo que pensaba originalmente. Tenga en cuenta los factores siguientes al elegir la configuración de capacidad máxima:
-
La capacidad máxima debe ser al menos tan alta como la capacidad mínima. Usted puede definir la capacidad mínima y máxima para que sean idénticas. Sin embargo, en ese caso, la capacidad nunca aumenta ni baja. Por lo tanto, utilizar valores idénticos para la capacidad mínima y máxima no es apropiado fuera de situaciones de prueba.
-
La capacidad máxima debe ser superior a 0,5 ACU. Puede establecer la capacidad mínima y máxima para que sean iguales en la mayoría de los casos. No obstante, no puede especificar 0,5 tanto para el mínimo como para el máximo. Utilice un valor de 1 o superior para obtener la capacidad máxima.
-
Si normalmente modifica la clase de instancia de base de datos de sus instancias de base de datos en previsión de una carga de trabajo especialmente alta o baja, puede aprovechar esa experiencia para hacer una estimación del rango de capacidad de Aurora Serverless v2 equivalente. Para determinar el tamaño de la memoria que se utilizará en momentos de mucho tráfico, consulte Especificaciones de hardware para clases de instancia de base de datos para Aurora.
Por ejemplo, supongamos que utiliza la clase de instancia de base de datos db.r6g.4xlarge cuando el clúster tiene una carga de trabajo elevada. Esta clase de instancia de base de datos tiene 128 GiB de memoria. Por lo tanto, puede especificar una configuración de ACU máxima de 64 para configurar una instancia de base de datos Aurora Serverless v2 que pueda escalar hasta aproximadamente la misma capacidad. Esto se debe a que cada ACU corresponde a aproximadamente 2 GiB de memoria. Puede especificar un valor algo mayor para permitir que la instancia de base de datos se amplíe más en caso de que la instancia de base de datos db.r6g.4xlarge a veces no tenga la capacidad suficiente para gestionar la carga de trabajo de forma eficaz.
-
Si tiene un límite presupuestario para usar su base de datos, elija un valor que se mantenga dentro de ese límite, incluso si todas las instancias de base de datos de Aurora Serverless v2 se ejecutan a máxima capacidad todo el tiempo. Recuerde eso cuando tenga n Aurora Serverless v2instancias de base de datos en el clúster, la máxima capacidad de Aurora Serverless v2 teórica que el clúster puede consumir en cualquier momento es n veces la configuración máxima de ACU para el clúster. (La cantidad real consumida podría ser menor, por ejemplo, si algunos lectores escalan independientemente del escritor).
-
Si hace uso de instancias de base de datos Aurora Serverless v2 de lector para descargar parte de la carga de trabajo de solo lectura de la instancia de base de datos de escritor, es posible que pueda elegir una configuración de capacidad máxima inferior. Esto se hace para reflejar que cada instancia de base de datos de lector no necesita escalar tan alto como si el clúster contuviera solo una instancia de base de datos.
-
Supongamos que desea protegerse contra el uso excesivo por parámetros de base de datos mal configurados o consultas ineficientes en la aplicación. En ese caso, puede evitar un uso excesivo por error eligiendo un ajuste de capacidad máxima inferior al más alto absoluto que podría establecer.
-
Si los picos por actividad real del usuario son poco frecuentes, pero sí ocurren, puede tener en cuenta esas ocasiones al elegir la configuración de capacidad máxima. Si la prioridad es que la aplicación siga funcionando con un rendimiento y escalabilidad completos, puede especificar una configuración de capacidad máxima superior a la observada en el uso normal. Si está bien que la aplicación se ejecute con un rendimiento reducido durante picos de actividad muy extremos, puede elegir una configuración de capacidad máxima ligeramente inferior. Asegúrese de elegir una configuración que aún tenga suficiente memoria y recursos de CPU para mantener la aplicación en ejecución.
-
Si habilita opciones de configuración en el clúster que aumenten el uso de memoria para cada instancia de base de datos, tenga en cuenta esa memoria al decidir el valor máximo de ACU. Estas opciones incluyen las de información del rendimiento, consultas paralelas de Aurora MySQL, esquema de rendimiento de Aurora MySQL y replicación de registros binarios de Aurora MySQL. Asegúrese de que el valor máximo de la ACU permite que las instancias de base de datos Aurora Serverless v2 se escalen lo suficiente como para gestionar la carga de trabajo cuando se usen esas funciones. Para obtener información sobre cómo solucionar problemas causados por la combinación de una configuración de ACU máxima baja y características de Aurora que impongan sobrecarga de memoria, consulte Evitar errores de memoria insuficiente.
Ejemplo: Cambiar el rango de capacidad de Aurora Serverless v2 de un clúster de Aurora MySQL
El siguiente ejemplo de AWS CLI muestra cómo actualizar el rango de ACU para instancias de base de datos Aurora Serverless v2 en un clúster de Aurora MySQL existente. En un principio, el rango de capacidad para el clúster es 8-32 ACU.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
La instancia de base de datos está inactiva y se escala a 8 ACU. La siguiente es la configuración relacionada con la capacidad en la instancia de base de datos en este momento. Para representar el tamaño del grupo de búferes en unidades fácilmente legibles, lo dividimos por 2 a la potencia de 30, lo que da lugar a una medición en gibibytes (GiB). Esto es así porque las mediciones relacionadas con la memoria de Aurora utilizan unidades basadas en potencias de 2, no de 10.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 9294577664 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 8.65625 | +-----------+ 1 row in set (0.00 sec)
A continuación, cambiamos el rango de capacidad del clúster. Una vez que finalice el comando modify-db-cluster, el rango de ACU para el clúster pasa de 12,5 a 80.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
El cambio del rango de capacidad provocó cambios en los valores predeterminados de algunos parámetros de configuración. Aurora puede aplicar algunos de esos nuevos valores predeterminados de manera inmediata. No obstante, algunos de los cambios en los parámetros surten efecto solo después de un reinicio. El estado pending-reboot indica que es necesario reiniciar para aplicar algunos cambios en los parámetros.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
En este punto, el clúster está inactivo y la instancia de base de datos serverless-v2-instance-1consume 12,5 ACU. El siguiente ejemplo muestra cómo el parámetro innodb_buffer_pool_size ya se ha ajustado en función de la capacidad actual de la instancia de base de datos. El parámetro max_connections sigue reflejando el valor del rango de capacidad máxima anterior. Para restablecer ese valor es necesario reiniciar la instancia de base de datos.
nota
Si establece el parámetro max_connections directamente en un grupo de parámetros de base de datos personalizado, no será necesario reiniciar.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 15572402176 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +---------------+ | gibibytes | +---------------+ | 14.5029296875 | +---------------+ 1 row in set (0.00 sec)
Ahora reiniciamos la instancia de base de datos y esperamos a que vuelva a estar disponible.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
El estado pending-reboot se borra. El valor in-sync confirma que Aurora ha aplicado todos los cambios de parámetros pendientes.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
El parámetro innodb_buffer_pool_size ha aumentado a su tamaño final para una instancia de base de datos inactiva. El parámetro max_connections ha aumentado para reflejar un valor derivado del valor de ACU máximo. La fórmula que utiliza Aurora para max_connections provoca un aumento de 1000 cuando el tamaño de la memoria se duplica.
mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 16139681792 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 15.03125 | +-----------+ 1 row in set (0.00 sec) mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 4000 | +-------------------+ 1 row in set (0.00 sec)
Establecemos el rango de capacidad entre 0,5 y 128 ACU y reiniciamos la instancia de base de datos. Ahora la instancia de base de datos inactiva tiene un tamaño de caché de búfer inferior a 1 GiB, por lo que la medimos en mebibytes (MiB). El valor max_connections de 5000 se deriva del tamaño de memoria de la configuración de capacidad máxima.
mysql> select @@innodb_buffer_pool_size / pow(2,20) as mebibytes, @@max_connections; +-----------+-------------------+ | mebibytes | @@max_connections | +-----------+-------------------+ | 672 | 5000 | +-----------+-------------------+ 1 row in set (0.00 sec)
Ejemplo: Cambiar el rango de capacidad Aurora Serverless v2 de un clúster de Aurora PostgreSQL
Los siguientes ejemplos de la CLI muestran cómo actualizar el rango de ACU para instancias de base de datos de Aurora Serverless v2 en un clúster de Aurora PostgreSQL existente.
-
El rango de capacidad del clúster comienza en 0,5 a 1 ACU.
-
Cambie el rango de capacidad a 8-32 ACU.
-
Cambie el rango de capacidad a 12,5–80 ACU.
-
Cambie el rango de capacidad a 0,5–128 ACU.
-
Devuelva la capacidad a su rango inicial de 0,5-1 ACU.
En el siguiente gráfico, se muestran los cambios de capacidad en Amazon CloudWatch.
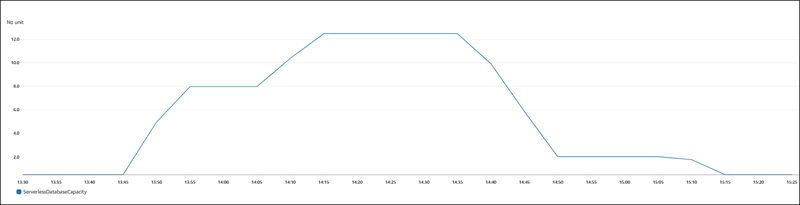
La instancia de base de datos está inactiva y se escala a 0,5 ACU. La siguiente es la configuración relacionada con la capacidad en la instancia de base de datos en este momento.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
A continuación, cambiamos el rango de capacidad del clúster. Una vez que finalice el comando modify-db-cluster, el rango de ACU para el clúster es 8,0–32.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
El cambio del rango de capacidad provoca cambios en los valores predeterminados de algunos parámetros de configuración. Aurora puede aplicar algunos de esos nuevos valores predeterminados de manera inmediata. No obstante, algunos de los cambios en los parámetros surten efecto solo después de un reinicio. El estado pending-reboot indica que es necesario reiniciar para aplicar algunos cambios en los parámetros.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
En este punto, el clúster está inactivo y la instancia de base de datos serverless-v2-instance-1 consume 8,0 ACU. El siguiente ejemplo muestra cómo el parámetro shared_buffers ya se ha ajustado en función de la capacidad actual de la instancia de base de datos. El parámetro max_connections sigue reflejando el valor del rango de capacidad máxima anterior. Para restablecer ese valor es necesario reiniciar la instancia de base de datos.
nota
Si establece el parámetro max_connections directamente en un grupo de parámetros de base de datos personalizado, no será necesario reiniciar.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
Reiniciamos la instancia de base de datos y esperamos a que vuelva a estar disponible.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
Ahora que la instancia de base de datos se ha reiniciado, el estado pending-reboot queda borrado. El valor in-sync confirma que Aurora ha aplicado todos los cambios de parámetros pendientes.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
Tras el reinicio, max_connections muestra el valor de la nueva capacidad máxima.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
A continuación, cambiamos el rango de capacidad del clúster a 12,5–80 ACU.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
En este punto, el clúster está inactivo y la instancia de base de datos serverless-v2-instance-1consume 12,5 ACU. El siguiente ejemplo muestra cómo el parámetro shared_buffers ya se ha ajustado en función de la capacidad actual de la instancia de base de datos. El valor de max_connections sigue siendo 5000.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
Reiniciamos de nuevo, pero los valores de los parámetros siguen siendo los mismos. Esto se debe a que max_connections tiene un valor máximo de 5000 para un clúster de base de datos de Aurora Serverless v2 que ejecuta Aurora PostgreSQL.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
Ahora establecemos el rango de capacidad entre 0,5 y 128 ACU. El clúster de base de datos se reduce verticalmente a 10 ACU y, luego, a 2. Reiniciamos la instancia de base de datos.
postgres=> show max_connections; max_connections ----------------- 2000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
El valor de max_connections de las instancias de base de datos de Aurora Serverless v2 se basa en el tamaño de memoria obtenido del número máximo de ACU. Sin embargo, cuando especifique una capacidad mínima de 0 o 0,5 ACU en instancias de base de datos compatibles con PostgreSQL, el valor máximo de max_connections está limitado a 2000.
Ahora devolvemos la capacidad a su rango inicial de 0,5 a 1 ACU y reiniciamos la instancia de base de datos. El parámetro max_connections ha recuperado su valor original.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Trabajo con los grupos de parámetros para Aurora Serverless v2
Cuando crea el clúster de bases de datos de Aurora Serverless v2, elige un motor de base de datos de Aurora y un grupo de parámetros de clúster de bases de datos asociado. Si no está familiarizado con cómo Aurora utiliza los grupos de parámetros para aplicar la configuración de forma coherente en clústeres, consulte Grupos de parámetros para Amazon Aurora. Todos estos procedimientos para crear, modificar, aplicar y otras acciones para grupos de parámetros son aplicables a Aurora Serverless v2.
La característica de grupo de parámetros suele funcionar igual entre clústeres aprovisionados y clústeres que contienen instancias de base de datos Aurora Serverless v2:
-
Los valores de los parámetros predeterminados de todas las instancias de base de datos en el clúster los define el grupo de parámetros del clúster.
-
Puede anular algunos parámetros para instancias de base de datos concretas especificando un grupo de parámetros de base de datos personalizado para esas instancias de base de datos. Puede hacerlo al ajustar las opciones de depuración o de rendimiento de instancias de base de datos específicas. Por ejemplo, suponga que tiene un clúster que contiene algunas instancias de base de datos Aurora Serverless v2 y algunas instancias de base de datos aprovisionadas. En este caso, puede especificar algunos parámetros diferentes para las instancias de base de datos aprovisionadas con un grupo de parámetros de base de datos personalizado.
-
Para Aurora Serverless v2, podría utilizar todos los parámetros que tengan el valor
provisioneden el atributoSupportedEngineModesdel grupo de parámetros. En Aurora Serverless v1 solo puede utilizar el subconjunto de parámetros que tienenserverlessen el atributoSupportedEngineModes.
Temas
Valores de parámetros predeterminados
Una diferencia crucial entre las instancias de base de datos aprovisionadas y las instancias de base de datos Aurora Serverless v2 es que Aurora anula cualquier valor de parámetro personalizado para determinados parámetros relacionados con la capacidad de las instancias de base de datos. Los valores de los parámetros personalizados se seguirán aplicando a cualquier instancia de base de datos aprovisionada del clúster. Para obtener más información acerca de cómo interpretan las instancias de base de datos Aurora Serverless v2 los parámetros de los grupos de parámetros Aurora, consulte Parámetros de configuración de los clústeres de Aurora. Para los parámetros específicos que Aurora Serverless v2 anula, consulte Parámetros que Aurora ajusta cuando se escala Aurora Serverless v2 a más o a menos y Parámetros en los que Aurora hace sus cómputos basándose en la capacidad máxima de Aurora Serverless v2.
Puede ver la lista de valores predeterminados de los grupos de parámetros predeterminados para los diferentes motores de base de datos de Aurora mediante el comando describe-db-cluster-parameters de la CLI y consultando la Región de AWS. A continuación se indican los valores que puede utilizar para las opciones --db-parameter-group-family y -db-parameter-group-name para versiones de motor compatibles con Aurora Serverless v2.
| Motor de base de datos y versión | Familia de grupos de parámetros | Nombre del grupo de parámetros predeterminado |
|---|---|---|
|
Aurora MySQL versión 3 |
|
|
|
Versión 13.x de Aurora PostgreSQL |
|
|
|
Versión 14.x de Aurora PostgreSQL |
|
|
|
Versión 15.x de Aurora PostgreSQL |
|
|
|
Versión 16.x de Aurora PostgreSQL |
|
|
|
Versión 17.x de Aurora PostgreSQL |
|
|
En el ejemplo siguiente se obtiene una lista de parámetros del grupo de clústeres de base de datos predeterminado para Aurora MySQL versión 3 y Aurora PostgreSQL 13. Estas son las versiones de Aurora MySQL y Aurora PostgreSQL que se usan con Aurora Serverless v2.
Para Linux, macOS o Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-mysql8.0 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-postgresql13 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text
Para Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-mysql8.0 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-postgresql13 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text
Número máximo de conexiones para Aurora Serverless v2
Para Aurora MySQL y Aurora PostgreSQL, las instancias de base de datos Aurora Serverless v2 contienen constante el parámetro max_connections para que las conexiones no se pierdan cuando la instancia de base de datos se escala a menos. El valor predeterminado de este parámetro se deriva de una fórmula que se basa en el tamaño de memoria de la instancia de base de datos. Para obtener más información sobre la fórmula y los valores predeterminados de las clases de instancia de base de datos aprovisionadas, consulte Número máximo de conexiones a una instancia de base de datos Aurora MySQL y Número máximo de conexiones a una instancia de base de datos Aurora PostgreSQL.
Cuando Aurora Serverless v2 evalúa la fórmula, utiliza el tamaño de memoria en función de las unidades de capacidad máxima de Aurora (ACU) para la instancia de base de datos, no en el valor ACU actual. Si cambia el valor predeterminado, le recomendamos utilizar una variación de la fórmula en lugar de especificar un valor constante. De esa forma, Aurora Serverless v2 puede utilizar un ajuste del tamaño adecuado basado en la capacidad máxima.
Al cambiar la capacidad máxima de un clúster de base de datos de Aurora Serverless v2, debe reiniciar las instancias de base de datos de Aurora Serverless v2 para actualizar el valor de max_connections. Esto se debe a que max_connections es un parámetro estático de Aurora Serverless v2.
La siguiente tabla muestra los valores predeterminados de max_connections para Aurora Serverless v2 en función del valor máximo de ACU.
| Cantidad máxima de ACU | Conexiones máximas predeterminadas en Aurora MySQL | Conexiones máximas predeterminadas en Aurora PostgreSQL |
|---|---|---|
| 1 | 90 | 189 |
| 4 | 135 | 823 |
| 8 | 1 000 | 1669 |
| 16 | 2,000 | 3360 |
| 32 | 3000 | 5 000 |
| 64 | 4.000 | 5 000 |
| 128 | 5 000 | 5 000 |
| 192 | 6000 | 5 000 |
| 256 | 6000 | 5 000 |
nota
El valor de max_connections de las instancias de base de datos de Aurora Serverless v2 se basa en el tamaño de memoria obtenido del número máximo de ACU. Sin embargo, cuando especifique una capacidad mínima de 0 o 0,5 ACU en instancias de base de datos compatibles con PostgreSQL, el valor máximo de max_connections está limitado a 2000.
Para ver ejemplos específicos que muestran cómo max_connections cambia con el valor máximo de ACU, consulte Ejemplo: Cambiar el rango de capacidad de Aurora Serverless v2 de un clúster de Aurora MySQL y Ejemplo: Cambiar el rango de capacidad Aurora Serverless v2 de un clúster de Aurora PostgreSQL.
Parámetros que Aurora ajusta cuando se escala Aurora Serverless v2 a más o a menos
Durante el escalado automático, Aurora Serverless v2 necesita poder cambiar los parámetros de cada instancia de base de datos para que funcione mejor para el aumento o la disminución de la capacidad. Por lo tanto, no puede anular algunos parámetros relacionados con la capacidad. En algunos parámetros que sí se pueden anular, evite codificar valores fijos. Tenga en cuenta lo siguiente en cuanto a esta configuración relacionada con la capacidad.
En Aurora MySQL, Aurora Serverless v2 cambia el tamaño de algunos parámetros dinámicamente durante el escalado. En los parámetros siguientes, Aurora Serverless v2 no utiliza ningún valor de parámetro personalizado que especifique el usuario:
-
innodb_buffer_pool_size -
innodb_purge_threads -
table_definition_cache -
table_open_cache
En Aurora PostgreSQL, Aurora Serverless v2 cambia el tamaño del siguiente parámetro de forma dinámica durante el escalado. En los parámetros siguientes, Aurora Serverless v2 no utiliza ningún valor de parámetro personalizado que especifique el usuario:
-
shared_buffers
Para todos los parámetros distintos de los enumerados aquí, las instancias de base de datos de Aurora Serverless v2 funcionan de la misma manera que las instancias de base de datos aprovisionadas. El valor predeterminado del parámetro se hereda del grupo de parámetros del clúster. Puede modificar el valor predeterminado de todo el clúster mediante un grupo de parámetros de clúster personalizado. O bien, puede modificar el valor predeterminado para determinadas instancias de base de datos mediante un grupo de parámetros de base de datos personalizado. Los parámetros dinámicos se actualizan de inmediato. Los cambios en los parámetros estáticos solo surten efecto después de reiniciar la instancia de base de datos.
Parámetros en los que Aurora hace sus cómputos basándose en la capacidad máxima de Aurora Serverless v2
Para los siguientes parámetros, Aurora PostgreSQL utiliza valores predeterminados derivados del tamaño de memoria basado en la configuración máxima de ACU, al igual que con max_connections:
-
autovacuum_max_workers -
autovacuum_vacuum_cost_limit -
autovacuum_work_mem -
effective_cache_size -
maintenance_work_mem
Evitar errores de memoria insuficiente
Si una de sus instancias de base de datos Aurora Serverless v2 alcanza constantemente el límite de su capacidad máxima, Aurora lo indica estableciendo la instancia de base de datos en un estado de incompatible-parameters. Si bien la instancia de base de datos tiene el estado incompatible-parameters, algunas operaciones quedan bloqueadas. Por ejemplo, no se puede actualizar la versión del motor.
Normalmente, la instancia de base de datos entra en este estado cuando se reinicia con frecuencia debido a errores de falta de memoria. Aurora graba un evento cuando se produce este tipo de reinicio. Puede ver el evento siguiendo el procedimiento en Consulta de eventos de Amazon RDS. Los casos de uso de memoria inusualmente elevados pueden producirse debido a una sobrecarga en el ajuste de configuraciones como la de la información del rendimiento y la autenticación de IAM. También puede provenir de una carga de trabajo pesada en la instancia de base de datos o de la administración de metadatos asociados a un gran número de objetos de esquema.
Si la presión de memoria disminuye para que la instancia de base de datos no alcance su capacidad máxima muy a menudo, Aurora cambia automáticamente el estado de la instancia de base de datos a available.
Para recuperarse de esta situación, puede llevar a cabo algunas o todas las acciones siguientes:
-
Aumentar el límite inferior de capacidad para instancias de base de datos Aurora Serverless v2 cambiando el valor mínimo de la unidad de capacidad Aurora (ACU) para el clúster. Al hacerlo, se evitan problemas en los que la capacidad de una base de datos inactiva se escala a menos memoria de la necesaria para las características activadas en el clúster. Después de cambiar la configuración de ACU del clúster, reinicie la instancia de base de datos Aurora Serverless v2. Al hacerlo, se evalúa si Aurora puede restablecer el estado de nuevo a
available. -
Aumentar el límite superior de capacidad para instancias de base de datos Aurora Serverless v2 cambiando el valor máximo de ACU para el clúster. Al hacerlo, se evitan problemas en los que una base de datos ocupada no puede escalar a una capacidad con suficiente memoria para las funciones activadas en el clúster y la carga de trabajo de la base de datos. Después de cambiar la configuración de ACU del clúster, reinicie la instancia de base de datos Aurora Serverless v2. Al hacerlo, se evalúa si Aurora puede restablecer el estado de nuevo a
available. -
Desactivar los ajustes de configuración que requieren sobrecarga de memoria. Por ejemplo, suponga que tiene activadas característica como AWS Identity and Access Management (IAM), información sobre el rendimiento o replicación de registros binarios de Aurora MySQL, pero no las usa. Si es así, puede desactivarlas. O bien, puede ajustar los valores de capacidad mínima y máxima del clúster para tener en cuenta la memoria utilizada por esas funciones. Para ver instrucciones sobre cómo elegir la configuración de capacidad mínima y máxima, consulte Elegir el rango de capacidad de Aurora Serverless v2 para un clúster de Aurora.
-
Reducir la carga de trabajo de la instancia de base de datos. Por ejemplo, puede agregar instancias de base de datos de instancias de lector al clúster para distribuir la carga de las consultas de solo lectura entre más instancias de base de datos.
-
Ajustar el código SQL utilizado por la aplicación para utilizar menos recursos. Por ejemplo, puede ver los planes de consulta, comprobar el registro de consultas lentas o ajustar los índices de las tablas. También puede aplicar otros tipos de ajustes de SQL tradicionales.
Métricas importantes de Amazon CloudWatch para Aurora Serverless v2
Para empezar a trabajar con Amazon CloudWatch para su instancia de base de datos Aurora Serverless v2, consulte Visualización registros de Aurora Serverless v2 en Amazon CloudWatch. Para obtener más información acerca de cómo monitorear los clústeres de base de datos de Aurora a través de CloudWatch, consulte Monitoreo de eventos de registro en Amazon CloudWatch.
Puede ver sus instancias de base de datos Aurora Serverless v2 en CloudWatch para supervisar la capacidad consumida por cada instancia de base de datos con la métrica ServerlessDatabaseCapacity. También puede supervisar todas las métricas estándar de CloudWatch para Aurora, como DatabaseConnections y Queries. Para ver la lista completa de métricas de CloudWatch que puede supervisar para Aurora, consulte Métricas de Amazon CloudWatch para Amazon Aurora. Las métricas se dividen en métricas en el nivel de clúster y de instancia, enMétricas de nivel de clúster para Amazon Aurora y Métricas de nivel de instancia para Amazon Aurora.
Es importante supervisar las siguientes métricas en el nivel de instancia de CloudWatch para comprender cómo se escalan a más o a menos las instancias de base de datos Aurora Serverless v2. Todas estas métricas se calculan cada segundo. De esta forma, puede supervisar el estado en uso de sus instancias de base de datos Aurora Serverless v2. Puede configurar alarmas para notificarle si hay alguna de las instancias de base de datos Aurora Serverless v2 se acerca a un umbral de métricas relacionadas con la capacidad. Puede determinar si los ajustes de capacidad mínima y máxima son apropiados o si necesita ajustarlos. Puede determinar dónde debe centrar sus esfuerzos para optimizar la eficiencia de la base de datos.
-
ServerlessDatabaseCapacity. Como métrica en el nivel de instancia, informa del número de ACU representadas por la capacidad de instancia de base de datos actual. Como métrica en el nivel de clúster, representa la media de los valores deServerlessDatabaseCapacityde todas las instancias de base de datos Aurora Serverless v2 del clúster. Esta métrica es solo una métrica de nivel de clúster en Aurora Serverless v1. En Aurora Serverless v2, está disponible en el nivel de instancia de base de datos y en el nivel de clúster. -
ACUUtilization. Esta métrica es nueva en Aurora Serverless v2. Este valor se representa como un porcentaje. Se calcula como el valor de la métricaServerlessDatabaseCapacitydividida por el valor máximo de ACU del clúster de bases de datos. Tenga en cuenta las siguientes pautas para interpretar esta métrica y tomar medidas:-
Si esta métrica se aproxima a un valor de
100.0, la instancia de base de datos se ha escalado al punto máximo posible. Considere aumentar la configuración máxima de ACU para el clúster. De este modo, las instancias de base de datos de escritor y lector podrán escalarse a una mayor capacidad. -
Supongamos que una carga de trabajo de solo lectura hace que una instancia de base de datos de lector se acerque a un valor
ACUUtilizationde100.0, mientras que la instancia de base de datos de escritor no está cerca de su capacidad máxima. En ese caso, considere agregar instancias de base de datos de lector adicionales al clúster. De esta forma, puede distribuir la parte de solo lectura de la carga de trabajo distribuida en más instancias de base de datos, reduciendo la carga en cada instancia de base de datos de lector. -
Supongamos que está ejecutando una aplicación de producción, donde el rendimiento y la escalabilidad son las principales consideraciones. En ese caso, puede establecer el valor máximo de ACU del clúster en un número elevado. Su objetivo es que la métrica
ACUUtilizationquede siempre por debajo de100.0. Con un valor de ACU máximo alto, puede estar seguro de tener suficiente espacio en caso de que haya picos inesperados en la actividad de la base de datos. Solo se le cobrará por la capacidad de base de datos que se consuma realmente.
-
-
CPUUtilization. Esta métrica se interpreta de forma diferente en Aurora Serverless v2 que en las instancias de base de datos aprovisionadas. Para Aurora Serverless v2, este valor es un porcentaje que se calcula como la cantidad de CPU que se utiliza actualmente dividida por la capacidad de CPU disponible bajo el valor máximo de ACU del clúster de bases de datos. Aurora supervisa este valor automáticamente y escala hacia arriba su instancia de base de datos Aurora Serverless v2 cuando esta utiliza sistemáticamente una elevada proporción de su capacidad de CPU.Si esta métrica se aproxima a un valor de
100.0, la instancia de base de datos ha alcanzado su capacidad máxima de CPU. Considere aumentar la configuración máxima de ACU para el clúster. Si esta métrica se aproxima a un valor de100.0en una instancia de base de datos de lector, considere agregar instancias de base de datos de lector adicionales al clúster. De esta forma, puede distribuir la parte de solo lectura de la carga de trabajo distribuida en más instancias de base de datos, reduciendo la carga en cada instancia de base de datos de lector. -
FreeableMemory. Este valor representa la cantidad de memoria sin utilizar que está disponible cuando la instancia de base de datos Aurora Serverless v2 se escala a su capacidad máxima. Por cada ACU en cuya capacidad actual esté por debajo de la capacidad máxima, este valor aumenta aproximadamente 2 GiB. Por lo tanto, esta métrica no se aproxima a cero hasta que la instancia de base de datos se amplía al máximo posible.Si esta métrica se aproxima a un valor de
0, la instancia de base de datos se ha ampliado tanto como puede y se acerca al límite de memoria disponible. Considere aumentar la configuración máxima de ACU para el clúster. Si esta métrica se aproxima a un valor de0en una instancia de base de datos de lector, considere agregar instancias de base de datos de lector adicionales al clúster. De esta forma, puede distribuir la parte de solo lectura entre más instancias de base de datos, reduciendo el uso de memoria en cada instancia de base de datos de lector. -
TempStorageIOPS. El número de IOPS realizadas en el almacenamiento local adjuntas a la instancia de base de datos. Incluye las IOPS de lecturas y escrituras. Esta métrica representa un recuento y se mide una vez por segundo. Esta es una nueva métrica en Aurora Serverless v2. Para obtener más información, consulte Métricas de nivel de instancia para Amazon Aurora. -
TempStorageThroughput. La cantidad de datos transferidos desde y hacia el almacenamiento local asociado a la instancia de base de datos. Esta métrica representa un número de bytes y se mide una vez por segundo. Esta es una nueva métrica en Aurora Serverless v2. Para obtener más información, consulte Métricas de nivel de instancia para Amazon Aurora.
Por lo general, la mayoría de los escalados a más para instancias de base de datos Aurora Serverless v2 son por el uso de la memoria y por la actividad. Las métricas TempStorageIOPS y TempStorageThroughput pueden ayudarle a diagnosticar los raros casos en los que la actividad de red para transferencias entre la instancia de base de datos y los dispositivos de almacenamiento locales es responsable de aumentos de capacidad no esperados. Para supervisar otra actividad de red, puede utilizar estas métricas existentes:
-
NetworkReceiveThroughput -
NetworkThroughput -
NetworkTransmitThroughput -
StorageNetworkReceiveThroughput -
StorageNetworkThroughput -
StorageNetworkTransmitThroughput
Puede hacer que Aurora publique algunos registros de base de datos o todos en Registros de Amazon CloudWatch. Para obtener instrucciones, consulte lo siguiente, en función del motor de base de datos:
Cómo se aplican las métricas de Aurora Serverless v2 en la factura de AWS
Los cargos correspondientes a Aurora Serverless v2 en la factura de AWS se calcula sobre la base de la misma métrica de ServerlessDatabaseCapacity que el usuario puede supervisar. El mecanismo de facturación puede diferir de la media computada de CloudWatch para esta métrica en los casos en los que se utilice capacidad de Aurora Serverless v2 durante solo una parte de una hora. También puede variar si los problemas del sistema hacen que la métrica de CloudWatch no esté disponible durante periodos breves. Por lo tanto, es posible que vea un valor ligeramente diferente de las horas de ACU en su factura que si computa el número usted mismo a partir del valor de ServerlessDatabaseCapacity promedio.
Ejemplos de comandos de CloudWatch para métricas de Aurora Serverless v2
Los siguientes ejemplos de AWS CLI muestran cómo se pueden supervisar las métricas de CloudWatch más importantes relacionadas con Aurora Serverless v2. En cada caso, sustituya la cadena Value= para el parámetro --dimensions con el identificador de su propia instancia de base de datos Aurora Serverless v2.
En el siguiente ejemplo de Linux se muestran los valores de capacidad mínima, máxima y media de una instancia de base de datos, medidos cada 10 minutos durante una hora. El comando de Linux date especifica las horas de inicio y finalización en relación con la fecha y la hora en curso. La función sort_by en el parámetro --query ordena los resultados cronológicamente basándose en el campo Timestamp.
aws cloudwatch get-metric-statistics --metric-name "ServerlessDatabaseCapacity" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Los siguientes ejemplos de Linux muestran la supervisión de la capacidad de cada instancia de base de datos de un clúster. Miden el uso de capacidad mínimo, máximo y medio de cada instancia de base de datos. Las mediciones se toman una vez por hora durante un período de tres horas. Estos ejemplos utilizan la métrica ACUUtilization, la cual representa un porcentaje del límite superior en las ACU, en lugar de ServerlessDatabaseCapacity, que representa un número fijo de ACU. De esta forma, no necesita conocer los números reales de los valores de ACU mínima y máxima en el rango de capacidad. Puede ver porcentajes que oscilan entre 0 y 100.
aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_writer_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_reader_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
En el siguiente ejemplo de Linux se hacen mediciones similares a las anteriores. En este caso, las medidas corresponden a la métrica CPUUtilization. Las mediciones se toman cada 10 minutos durante un período de 1 hora. Los números representan el porcentaje de CPU disponible utilizada, en función de los recursos de CPU disponibles para la configuración de capacidad máxima de la instancia de base de datos.
aws cloudwatch get-metric-statistics --metric-name "CPUUtilization" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
En el siguiente ejemplo de Linux se hacen mediciones similares a las anteriores. En este caso, las medidas corresponden a la métrica FreeableMemory. Las mediciones se toman cada 10 minutos durante un período de 1 hora.
aws cloudwatch get-metric-statistics --metric-name "FreeableMemory" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Supervisión del rendimiento de Aurora Serverless v2 con la información de rendimiento
Puede utilizar Performance Insights (Información de rendimiento) para supervisar el rendimiento de las instancias de base de datos Aurora Serverless v2 Para conocer los procedimientos de información del rendimiento, consulte Monitoreo de la carga de base de datos con Performance Insights en Amazon Aurora.
Los siguientes son contadores de información del rendimiento nuevos aplicables a instancias de base de datos Aurora Serverless v2
-
os.general.serverlessDatabaseCapacity: la capacidad actual de la instancia de base de datos en ACU. El valor corresponde a la métrica de CloudWatchServerlessDatabaseCapacitypara la instancia de base de datos. -
os.general.acuUtilization: porcentaje de la capacidad actual fuera de la capacidad máxima configurada. El valor corresponde a la métrica de CloudWatchACUUtilizationpara la instancia de base de datos. -
os.general.maxConfiguredAcu: la capacidad máxima que ha configurado para esta instancia de base de datos Aurora Serverless v2. Se mide en ACU. -
os.general.minConfiguredAcu: la capacidad máxima que ha configurado para esta instancia de base de datos Aurora Serverless v2. Se mide en ACU.
Para ver la lista completa de contadores de información de rendimiento, consulte Métricas de contador de Información de rendimiento.
Cuando se muestran los valores de vCPU para una instancia de base de datos Aurora Serverless v2 en la información de rendimiento, estos valores representan estimaciones basadas en el valor de ACU de la instancia de base de datos. En el intervalo predeterminado de un minuto, los valores fraccionarios de vCPU se redondean al número entero más cercano. En intervalos más largos, el valor de vCPU que se muestra es el promedio de los valores de vCPU enteros de cada minuto.
Solución de problemas de capacidad de Aurora Serverless v2
En algunos casos, Aurora Serverless v2 no se reduce verticalmente a la capacidad mínima, incluso sin carga en la base de datos. Esto puede suceder por una de las siguientes razones:
-
Algunas características pueden aumentar el uso de los recursos e impedir que la base de datos se reduzca verticalmente a su capacidad mínima. Estas son algunas de ellas:
-
Bases de datos globales de Aurora
-
Exportación de registros de CloudWatch
-
Habilitación de
pg_auditen clústeres de base de datos compatibles con Aurora PostgreSQL -
Supervisión mejorada
-
Información de rendimiento
Para obtener más información, consulte Elegir la configuración de capacidad de Aurora Serverless v2 mínima para un clúster.
-
-
Si una instancia de lector no se reduce verticalmente al mínimo y permanece en la misma capacidad o más que la instancia de escritor, compruebe el nivel de prioridad de la instancia de lector. Las instancias de base de datos de lector de Aurora Serverless v2 en los niveles 0 o 1 se mantienen a una capacidad mínima al menos tan alta como la instancia de base de datos de escritor. Cambie el nivel de prioridad del lector a 2 o más para que se escale y se reduzca verticalmente independientemente del escritor. Para obtener más información, consulte Elegir el nivel de promoción para un lector Aurora Serverless v2.
-
Defina los parámetros de la base de datos que afecten al tamaño de la memoria compartida en sus valores predeterminados. Si se establece un valor superior al predeterminado, se aumenta el requisito de memoria compartida y se evita que la base de datos se reduzca verticalmente a la capacidad mínima. Algunos ejemplos son
max_connectionsymax_locks_per_transaction.nota
La actualización de los parámetros de memoria compartida requiere reiniciar la base de datos para que los cambios surtan efecto.
-
Las cargas de trabajo pesadas de las bases de datos pueden aumentar el uso de recursos.
-
Los grandes volúmenes de bases de datos pueden aumentar el uso de recursos.
Amazon Aurora utiliza recursos de memoria y CPU para la administración de clústeres de bases de datos. Aurora requiere más CPU y memoria para administrar los clústeres de bases de datos con volúmenes de bases de datos más grandes. Si la capacidad mínima del clúster es inferior al mínimo requerido para la administración del clúster, el clúster no se reducirá verticalmente a la capacidad mínima.
-
Los procesos en segundo plano, como la purga, también pueden aumentar el uso de los recursos.
Si la base de datos sigue sin reducir verticalmente la capacidad mínima configurada, deténgala y reiníciela para recuperar los fragmentos de memoria que se hayan acumulado con el tiempo. Al detener e iniciar una base de datos, se produce un tiempo de inactividad, por lo que recomendamos hacerlo con moderación.
