Trabajo con réplicas de lectura de instancias de base de datos
Una réplica de lectura es una copia de solo lectura de una instancia de base de datos. Puede reducir la carga de la instancia de la base de datos principal enrutando las consultas de sus aplicaciones a la réplica de lectura. De este modo, puede ajustar la escala horizontalmente y de manera elástica por encima de las restricciones de capacidad de una instancia de base de datos para las cargas de trabajo de las bases de datos con operaciones intensivas de lectura.
Para crear una réplica de lectura a partir de una instancia de base de datos de origen, Amazon RDS usa las características de replicación integradas del motor de base de datos. Para obtener información sobre la utilización de las réplicas de lectura con un motor específico, consulte las secciones siguientes:
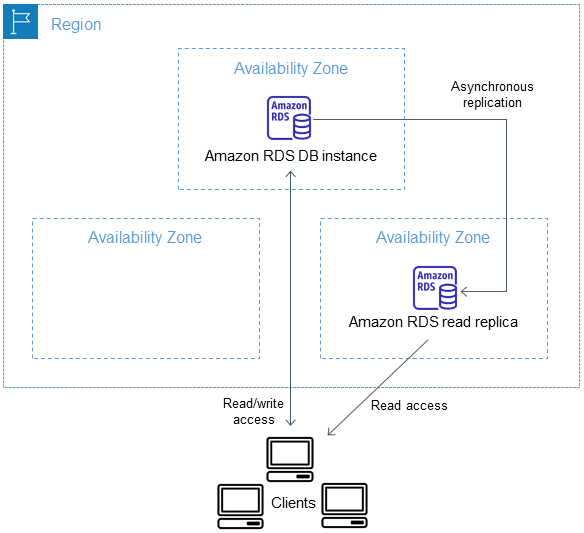
Tras crear una réplica de lectura a partir de una instancia de base de datos de origen, el origen se convierte en la instancia de base de datos principal. Al realizar actualizaciones en la instancia de base de datos principal, Amazon RDS las copia de forma asíncrona en la réplica de lectura. El siguiente diagrama muestra una instancia de base de datos de origen que se replica en una réplica de lectura en una zona de disponibilidad (AZ) diferente. Los clientes tienen acceso de lectura/escritura a la instancia de base de datos principal y acceso de solo lectura a la réplica.
Las réplicas de lectura se facturan como instancias de base de datos estándar con las mismas tarifas que la clase de instancia de base de datos utilizada para la réplica. No se le cobrará por los gastos de transferencia de datos en los que se incurra al replicar datos entre la instancia de base de datos de origen y la réplica de lectura de la misma Región de AWS. Para obtener más información, consulte Costos de la replicación entre regiones y Facturación de instancia de base de datos para Amazon RDS .
Temas
Información general de las réplicas de lectura de Amazon RDS
En las siguientes secciones se describen las réplicas de lectura de instancia de base de datos. Para obtener más información acerca de las réplicas de lectura de clúster de base de datos multi-AZ, consulte Uso de réplicas de lectura de clústeres de base de datos multi-AZ para Amazon RDS.
Casos de uso de réplicas de lectura
La implementación de una o varias réplicas de lectura para una instancia de base de datos de origen puede tener sentido en diversas situaciones, como las siguientes:
-
Aumentar la escala por encima de la capacidad de E/S o de computación de una instancia de base de datos para las cargas de trabajo de las bases de datos con operaciones intensivas de lectura. Puede dirigir este exceso del tráfico de lectura a una o varias réplicas de lectura.
-
Servir tráfico de lectura cuando la instancia de base de datos de origen no está disponible. En algunos casos, es posible que su instancia de base de datos de origen no pueda aceptar solicitudes de E/S, por ejemplo, debido a la suspensión de E/S para las copias de seguridad o el mantenimiento programado. En estos casos, puede dirigir el tráfico de lectura a sus réplicas de lectura. En este caso de uso, recuerde que los datos de la réplica de lectura pueden estar "obsoletos" porque la instancia de base de datos de origen no está disponible.
-
Las situaciones de informes de negocios o de almacenamiento de datos en las que se desea que las consultas de informes de negocios se ejecuten en una réplica de lectura y no en la instancia de base de datos de producción.
-
Implementación de recuperación de desastres Puede promocionar una réplica de lectura en la instancia independiente como solución de recuperación de desastres si la instancia de base de datos principal produce un error.
Cómo funcionan las réplicas de lectura
Cuando se crea una réplica de lectura, se especifica una instancia de base de datos existente como origen. A continuación, Amazon RDS realiza una instantánea de la instancia de origen y crea una instancia de solo lectura a partir de la instantánea. Luego, Amazon RDS utiliza el método de reproducción asíncrono para que el motor de base de datos actualice la réplica de lectura cuando se produzca un cambio en la instancia de base de datos primaria.
La réplica de lectura funciona como una instancia de base de datos que permite únicamente conexiones de solo lectura. Las excepciones son los motores de base de datos RDS para Db2 y RDS para Oracle, que admiten bases de datos de réplica en modo de espera y en modo montado, respectivamente. Una réplica en espera y una réplica montada no aceptan conexiones de usuario, por lo que no pueden servir cargas de trabajo de solo lectura. El uso principal de las réplicas en espera y las réplicas montadas es la recuperación ante desastres entre regiones. Para obtener más información, consulte Trabajo con las réplicas de Amazon RDS para Db2 y Trabajo con las réplicas de lectura para Amazon RDS para Oracle.
Las aplicaciones se conectan a una réplica de lectura de la misma forma que a cualquier instancia de base de datos. Amazon RDS replica todas las bases de datos de la instancia de base de datos de origen.
Debe crear réplicas de lectura manualmente. RDS no admite el escalado automático de réplicas de lectura, que es la acción de agregar o eliminar automáticamente réplicas de lectura a medida que cambia la demanda de lectura.
Lectura de réplicas en una implementación multi-AZ
Se puede configurar una réplica de lectura para una instancia de base de datos que también tenga una réplica en espera configurada para alta disponibilidad en una implementación Multi-AZ. Una replicación con la réplica en espera es sincrónica. A diferencia de una réplica de lectura, una réplica en espera no puede servir tráfico de lectura.
En el siguiente escenario, los clientes tienen acceso de lectura/escritura a una instancia de base de datos principal en una AZ. La instancia principal copia las actualizaciones de forma asincrónica en una réplica de lectura en una segunda AZ y también las copia de forma sincrónica en una réplica en espera en una tercera AZ. Los clientes solo tienen acceso de lectura a la réplica de lectura.

Para obtener más información acerca de las réplicas de alta disponibilidad y en espera, consulte Configuración y administración de una implementación multi-AZ para Amazon RDS.
Réplicas de lectura entre regiones
En algunos casos, una réplica de lectura reside en una Región de AWS distinta de la de su instancia de base de datos principal. En esos casos, Amazon RDS configura un canal de comunicaciones seguro entre la instancia de base de datos primaria y la réplica de lectura. Amazon RDS establece cualquier configuración de seguridad de AWS necesarias para habilitar el canal seguro, por ejemplo agregar entradas de grupo de seguridad. Para obtener información sobre las réplicas de lectura entre regiones, consulte Creación de una réplica de lectura en una distinta Región de AWS.
La información de este capítulo hace referencia a la creación de réplicas de lectura de Amazon RDS, ya sea en la misma Región de AWS que la instancia de base de datos de origen o en una Región de AWS diferente. La siguiente información no es válida para configurar la replicación con una instancia que se ejecute en una instancia de Amazon EC2 o que esté instalada localmente.
Tipos de almacenamiento de las réplicas de lectura
De forma predeterminada, una réplica de lectura se crea con el mismo tipo de almacenamiento que la instancia de base de datos de origen. Sin embargo, puede crear una réplica de lectura que tenga un tipo de almacenamiento distinto del de la instancia de base de datos de origen en función de las opciones que se muestran en la siguiente tabla.
| Tipo de almacenamiento de la instancia de base de datos de origen | Asignación de almacenamiento de la instancia de base de datos de origen | Opciones del tipo de almacenamiento de las réplicas de lectura |
|---|---|---|
| IOPS provisionadas | 100 GiB–64 TiB | IOPS aprovisionadas, uso general, magnético |
| Uso general | 100 GiB–64 TiB | IOPS aprovisionadas, uso general, magnético |
| Uso general | <100 GiB | Uso general, magnético |
| Magnético | 100 GiB–6 TiB | IOPS aprovisionadas, uso general, magnético |
| Magnético | <100 GiB | Uso general, magnético |
nota
Cuando aumenta el almacenamiento asignado de una réplica de lectura, debe ser de al menos un 10 por ciento. Si intenta aumentar el valor en menos del 10 por ciento, obtendrá un error.
Restricciones para crear una réplica a partir de una réplica
Amazon RDS no admite la replicación circular. No puede configurar una instancia de base de datos para que sirva como origen de replicación para una instancia de base de datos existente. Solo puede crear una nueva réplica de lectura desde una instancia de base de datos existente. Por ejemplo, si MySourceDBInstance se replica en ReadReplica1, no puede configurar ReadReplica1 para volverse a replicar en MySourceDBInstance.
Para RDS para MariaDB y RDS para MySQL, y en determinadas versiones de RDS para PostgreSQL, puede crear una réplica de lectura a partir de una réplica de lectura existente. Por ejemplo, puede crear una réplica de lectura nueva ReadReplica2 a partir de una réplica ReadReplica1 existente. En RDS para Db2, RDS para Oracle y RDS para SQL Server, no puede crear una réplica de lectura a partir de una réplica de lectura existente.
Consideraciones a la hora de borrar réplicas
RDS no admite el escalado automático de réplicas de lectura. Por lo tanto, RDS no aumentará el número de réplicas cuando la demanda aumente ni disminuirá el número de réplicas cuando la demanda disminuya. Si ya no necesita réplicas de lectura, elimínelas manualmente con los mismos mecanismos que emplea para eliminar una instancia de base de datos. Si elimina una instancia de base de datos de origen sin eliminar las réplicas de lectura en la misma Región de AWS, cada réplica se convertirá en una instancia de base de datos independiente.
Para obtener más información sobre la eliminación de instancias de base de datos, consulte Eliminación de una instancia de base de datos. Para obtener información sobre la promoción de réplicas de lectura, consulte Promoción de una réplica de lectura para convertirla en una instancia de base de datos independiente. Para obtener información relacionada con la eliminación de la instancia de base de datos de origen para una réplica de lectura entre regiones, consulte Consideraciones relativas a la replicación entre regiones.
