Uso de un metastore de Hive externo
Puede utilizar el conector de datos de Amazon Athena para metaalmacén externo de Hive para consultar conjuntos de datos en Amazon S3 que utilicen un metaalmacén de Apache Hive. No es necesaria la migración de los metadatos a AWS Glue Data Catalog. En la consola de administración de Athena, configure una función de Lambda para comunicarse con el metaalmacén de Hive en su VPC privada y, a continuación, conéctela al metaalmacén. La conexión desde Lambda a su metaalmacén de Hive está asegurada por un canal de Amazon VPC privado y no utiliza Internet público. Puede proporcionar su propio código de función de Lambda, o puede usar la implementación predeterminada del conector de datos de Athena para metaalmacén externo de Hive.
Temas
Conexión de Athena a un metastore de Hive mediante un rol de ejecución de IAM existente
Configuración de Athena para utilizar un conector de almacén de metadatos de Hive implementado
Omisión del nombre del catálogo en consultas de metastores externos de Hive
Modificación del conector del metastore externo de Hive de Athena
Información general de las características
Con el conector de datos de Athena para metaalmacén externo de Hive, puede realizar las siguientes tareas:
-
Utilice la consola de Athena para registrar catálogos personalizados y ejecutar consultas con ellos.
-
Defina funciones de Lambda para diferentes metaalmacenes externos de Hive y únalas en consultas de Athena.
-
Utilice el AWS Glue Data Catalog y sus metaalmacenes externos de Hive en la misma consulta de Athena.
-
Especifique un catálogo en el contexto de ejecución de la consulta como el catálogo predeterminado actual. Esto elimina el requisito de prefijo de nombres de catálogo a nombres de base de datos en las consultas. En lugar de usar la sintaxis
catalog.database.tabledatabase.table -
Utilice una variedad de herramientas para ejecutar consultas que hagan referencia a metaalmacenes externos de Hive. Puede utilizar la consola de Athena, la AWS CLI, el SDK de AWS, las API de Athena y los controladores JDBC y ODBC de Athena actualizados. Los controladores actualizados son compatibles con catálogos personalizados.
Compatibilidad con API
Athena Data Connector para metaalmacenes externos de Hive incluye soporte para operaciones de API de registro de catálogos y operaciones de API de metadatos.
-
Registro de catálogos: registre catálogos personalizados para metaalmacenes externos de Hive y orígenes de datos federados.
-
Metadatos: utilice las API de metadatos para proporcionar información de bases de datos y tablas para AWS Glue y cualquier catálogo que registre con Athena.
-
Cliente Athena JAVA SDK: utilice las API de registro de catálogos, las API de metadatos y la compatibilidad con catálogos de la operación
StartQueryExecutionen el cliente Athena Java SDK actualizado.
Implementación de referencia
Athena proporciona una implementación de referencia para la función de Lambda que se conecta a metaalmacenes externos de Hive. La implementación de referencia se proporciona en GitHub como un proyecto de código abierto en el almacén de metadatos de Athena Hive
La implementación de referencia está disponible como las dos siguientes aplicaciones de AWS SAM en el AWS Serverless Application Repository (SAR). Puede utilizar cualquiera de estas aplicaciones en el SAR para crear sus propias funciones de Lambda.
-
AthenaHiveMetastoreFunction: archivo.jarde la función de Lambda Uber. Un “uber” JAR (también conocido como fat JAR o JAR con dependencias) es un archivo.jarque contiene un programa Java y sus dependencias en un solo archivo. -
AthenaHiveMetastoreFunctionWithLayer: capa de Lambda y archivo.jarde función delgada de Lambda.
Flujo de trabajo
En el siguiente diagrama, se muestra cómo interactúa Athena con su metaalmacén externo de Hive.
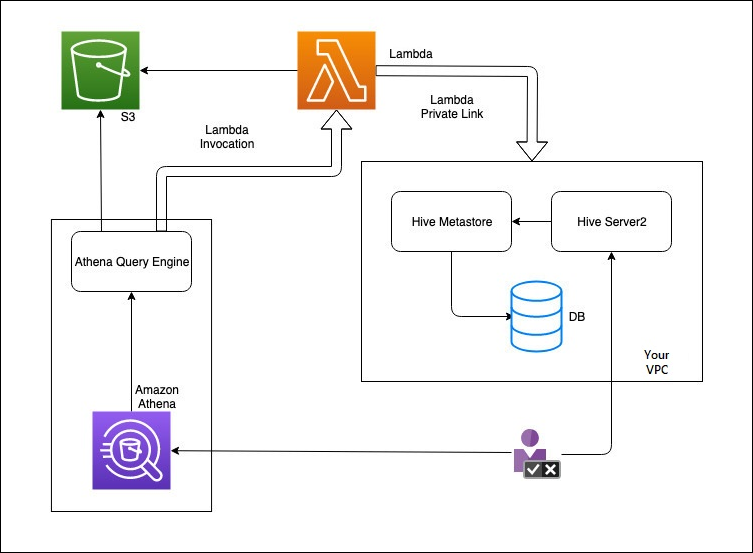
En este flujo de trabajo, el metaalmacén de Hive conectado a la base de datos está dentro de su VPC. Utilice Hive Server2 para administrar su metaalmacén de Hive mediante la CLI de Hive.
El flujo de trabajo para utilizar metaalmacenes externos de Hive de Athena incluye los siguientes pasos.
-
Cree una función de Lambda que conecte Athena al metaalmacén de Hive que está dentro de su VPC.
-
Usted registra un nombre de catálogo único para su metaalmacén de Hive y un nombre de función correspondiente en su cuenta.
-
Cuando ejecuta una consulta DML o DDL de Athena que utiliza el nombre del catálogo, el motor de consulta de Athena llama al nombre de la función de Lambda que asoció con el nombre del catálogo.
-
Con AWS PrivateLink, la función de Lambda se comunica con el metaalmacén externo de Hive en su VPC y recibe respuestas a solicitudes de metadatos. Athena utiliza los metadatos del metaalmacén externo de Hive al igual que usa los metadatos del AWS Glue Data Catalog predeterminado.
Consideraciones y limitaciones
Cuando utilice el conector de datos de Athena para metaalmacén externo de Hive, tenga en cuenta los siguientes puntos:
-
Puede utilizar CTAS para crear una tabla en un metaalmacén externo de Hive.
-
Puede utilizar INSERT INTO para insertar datos en un metaalmacén externo de Hive.
-
El soporte de DDL para el metaalmacén externo de Hive está limitado a las siguientes instrucciones.
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
ALTER TABLE REPLACE COLUMNS
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
CREATE DATABASE
-
CREATE TABLE
-
CREATE TABLE AS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DROP TABLE
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
MOSTRAR ESQUEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
El número máximo de catálogos registrados que puede tener es de 1000.
-
No se admite la autenticación Kerberos para el metaalmacén de Hive.
-
Para utilizar el controlador JDBC con un metaalmacén externo de Hive o las consultas federadas, incluya
MetadataRetrievalMethod=ProxyAPIen la cadena de conexión JDBC. Para obtener información acerca del controlador JDBC, consulte Conexión a Amazon Athena con JDBC. -
Las columnas ocultas de Hive
$path,$bucket,$file_size,$file_modified_time,$partitiony$row_idno se pueden utilizar para un filtrado de control de acceso detallado. -
Las tablas ocultas del sistema de Hive como
example_table$partitionsexample_table$properties
Permisos
Los conectores de datos prediseñados y personalizados pueden requerir acceso a los siguientes recursos para funcionar correctamente. Compruebe la información del conector que utiliza para asegurarse de que ha configurado correctamente la VPC. Para obtener información sobre los permisos de IAM necesarios para ejecutar consultas y crear un conector de origen de datos en Athena, consulte Permiso de acceso al conector de datos de Athena para el metastore externo de Hive y Permitir a la función de Lambda el acceso a los almacenes de metadatos externos de Hive.
-
Amazon S3: además de escribir los resultados de la consulta en la ubicación de resultados de la consulta de Athena en Amazon S3, los conectores de datos también escriben en un bucket de desbordamiento en Amazon S3. Se requiere conectividad y permisos para esta ubicación de Amazon S3. Para obtener más información, consulte Ubicación de desbordamiento en Simple Storage Service (Amazon S3) más adelante en este tema.
-
Athena: se requiere acceso para verificar el estado de la consulta y evitar el sobreescaneo.
-
AWS Glue: se requiere acceso si el conector utiliza AWS Glue para metadatos complementarios o principales.
-
AWS Key Management Service
-
Políticas: el metaalmacén de Hive, la Athena Query Federation y las UDF requieren políticas además de Política administrada de AWS: AmazonAthenaFullAccess. Para obtener más información, consulte Identity and Access Management en Athena.
Ubicación de desbordamiento en Simple Storage Service (Amazon S3)
Debido al límite en los tamaños de respuesta de la función de Lambda, las respuestas mayores que el umbral se desbordan en una ubicación de Amazon S3 que especifique al crear la función de Lambda. Athena lee estas respuestas de Amazon S3 directamente.
nota
Athena no elimina los archivos de respuesta en Amazon S3. Se recomienda configurar una política de retención para eliminar automáticamente los archivos de respuesta.
