AWS Data Pipeline ya no está disponible para nuevos clientes. Los clientes actuales de AWS Data Pipeline pueden seguir utilizando el servicio con normalidad. Más información
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
¿Qué es AWS Data Pipeline?
nota
AWS Data Pipeline El servicio de está en modo de mantenimiento y no se prevén nuevas funciones ni ampliaciones regionales. Para obtener más información y saber cómo migrar las cargas de trabajo existentes, consulte Migración de cargas de trabajo de AWS Data Pipeline.
AWS Data Pipeline es un servicio web que se puede utilizar para automatizar el movimiento y la transformación de los datos. Con AWS Data Pipelineél, puede definir flujos de trabajo basados en datos, de modo que las tareas dependan de la finalización satisfactoria de las tareas anteriores. Usted define los parámetros de las transformaciones de datos AWS Data Pipeline y aplica la lógica que ha configurado.
Los siguientes componentes AWS Data Pipeline funcionan en conjunto para administrar los datos:
-
Una definición de canalización especifica la lógica de negocio de la administración de datos. Para obtener más información, consulte Sintaxis de los archivos de definición de la canalización.
-
Una canalización programa y ejecuta tareas mediante la creación de EC2 instancias Amazon que llevan a cabo las actividades de trabajo definidas. Solo tiene que cargar la definición de canalización en la canalización y, a continuación, activar la canalización. Puede editar la definición de la canalización de una canalización en ejecución y activar de nuevo la canalización para que surta efecto. Puede desactivar la canalización, modificar una fuente de datos y, a continuación, activar la canalización de nuevo. Cuando haya terminado con la canalización, puede eliminarla.
-
Task Runner realiza un sondeo para comprobar si hay tareas y, a continuación, realiza esas tareas. Por ejemplo, Task Runner podría copiar archivos de registro en Amazon S3 y lanzar clústeres de Amazon EMR. Task Runner se instala y se ejecuta automáticamente en los recursos creados por las definiciones de la canalización. Puede escribir una aplicación de ejecución de tareas personalizada o puede usar la aplicación Task Runner que se incluye en AWS Data Pipeline. Para obtener más información, consulte Aplicaciones de ejecución de tareas.
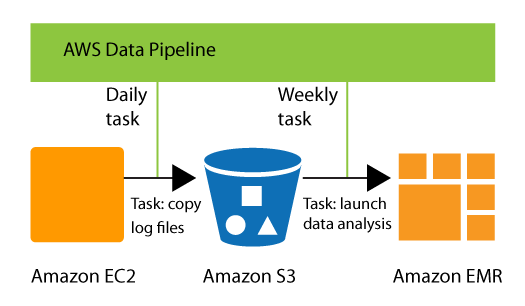
Por ejemplo, puede utilizar para AWS Data Pipeline archivar los registros de su servidor web en Amazon Simple Storage Service (Amazon S3) todos los días y, a continuación, ejecutar un clúster Amazon EMR (Amazon EMR) semanal sobre esos registros para generar informes de tráfico. AWS Data Pipeline programa las tareas diarias para copiar datos y la tarea semanal para lanzar el clúster de Amazon EMR. AWS Data Pipeline también garantiza que Amazon EMR espere a que se carguen los datos del último día en Amazon S3 antes de comenzar su análisis, incluso si se produce un retraso imprevisto en la carga de los registros.
Contenido
Acceder AWS Data Pipeline
Puede crear, acceder y administrar las canalizaciones desde cualquiera de las siguientes interfaces:
-
AWS Management Console: proporciona una interfaz web que se puede utilizar para obtener acceso a AWS Data Pipeline.
-
AWS Command Line Interface (AWS CLI): proporciona comandos para numerosos servicios de AWS, incluido AWS Data Pipeline, y es compatible con Windows, macOS y Linux. Para obtener más información sobre la instalación de AWS CLI, consulte AWS Command Line Interface
. Para obtener una lista de los comandos de AWS Data Pipeline, consulte datapipeline. -
AWS SDKs: proporciona información específica de cada lenguaje APIs y se encargan de muchos de los detalles de conexión, tales como el cálculo de firmas, el control de reintentos de solicitud y el control de errores. Para obtener más información, consulte AWS SDKs
. -
API de consulta: proporciona información de nivel bajo a la APIs que se llama mediante solicitudes HTTPS. Utilizar la API de consulta es la forma más directa de obtener acceso a AWS Data Pipeline, pero requiere que la aplicación controle niveles de detalle de bajo nivel, tales como la generación del código hash para firmar la solicitud y el control de errores. Para obtener más información, consulte la Referencia de la API de AWS Data Pipeline.
Precios
Con los servicios de Amazon Web Services, solo se paga por lo que se usa. Por ejemplo AWS Data Pipeline, pagas por tu canalización en función de la frecuencia con la que estén programadas tus actividades y condiciones previas y del lugar en el que se ejecuten. Para obtener más información, consulte AWS Data Pipeline Precios
Si su cuenta de AWS tiene menos de 12 meses, puede utilizar la capa gratuita. La capa gratuita incluye tres condiciones previas de baja frecuencia y cinco actividades de baja frecuencia al mes sin ningún tipo de costo. Para obtener más información, consulte Capa gratuita de AWS
