Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Conexión a Amazon DocumentDB como conjunto de réplicas
Cuando desarrolle en Amazon DocumentDB (con compatibilidad con MongoDB), recomendamos que se conecte al clúster como conjunto de réplicas y distribuya las lecturas a las instancias de réplica mediante las funciones integradas de preferencias de lectura del controlador. En esta sección se profundiza en lo que esto significa y se describe cómo conectarse al clúster de Amazon DocumentDB como conjunto de réplicas con el SDK para Python como ejemplo.
Amazon DocumentDB tiene tres puntos de conexión que puede utilizar para conectarse al clúster:
-
Punto de conexión de clúster
-
Punto de conexión del lector
-
Puntos de conexión de instancia
En la mayoría de los casos, cuando se conecte a Amazon DocumentDB, recomendamos que utilice el punto de conexión de clúster. Se trata de un CNAME que apunta a la instancia principal del clúster, tal y como se muestra en el siguiente diagrama.
Cuando utilice un túnel SSH, es recomendable que se conecte al clúster utilizando el punto de conexión de dicho clúster y que no intente conectarse utilizando el modo de conjunto de réplicas (es decir, especificando replicaSet=rs0 en la cadena de conexión), ya que dará lugar a un error.
nota
Para obtener más información acerca de los puntos de conexión de sitio web de Amazon DocumentDB, consulte Puntos de conexión de Amazon DocumentDB.

Con el punto de conexión de clúster, puede conectarse al clúster en modo de conjunto de réplicas. A continuación, puede utilizar las funciones integradas del controlador de preferencias de lectura. En el siguiente ejemplo, al especificar /?replicaSet=rs0, el SDK entiende que desea conectarse como conjunto de réplicas. Si omite /?replicaSet=rs0', el cliente dirige todas las solicitudes al punto de conexión de clúster, es decir, la instancia principal.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0')
La ventaja de conectarse como conjunto de réplicas es que permite al SDK detectar automáticamente la topografía del clúster, lo que incluye cuándo se añaden o se eliminan instancias del clúster. Posteriormente, puede utilizar el clúster de forma más eficiente dirigiendo las solicitudes de lectura a las instancias de réplica.
Cuando se conecta como conjunto de réplicas, puede especificar la readPreference para la conexión. Si especifica una preferencia de lectura de secondaryPreferred, el cliente dirige las consultas de lectura a las réplicas y las consultas de escritura, a la instancia principal (como en el siguiente diagrama). Así, se aprovechan mejor los recursos del clúster. Para obtener más información, consulte Opciones de preferencia de lectura.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
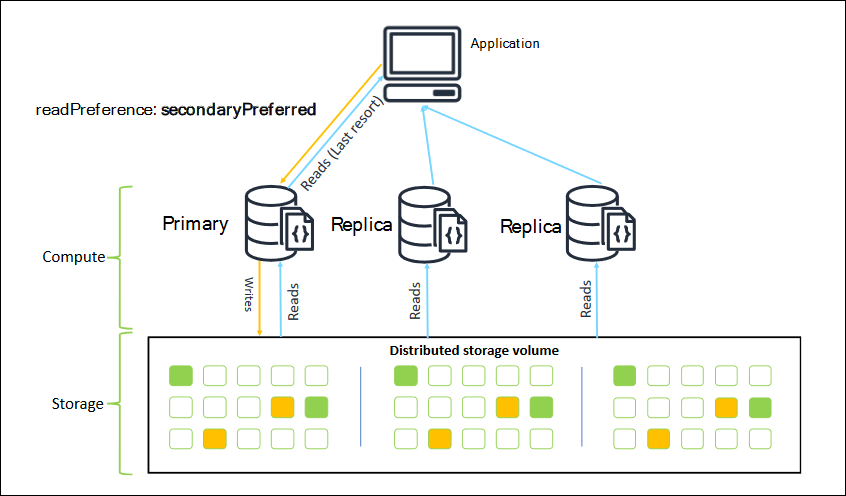
Las lecturas de las réplicas de Amazon DocumentDB presentan consistencia final. Devuelven los datos en el mismo orden en que se escribieron en la instancia principal y, a menudo, hay un retardo de replicación inferior a 50 ms. Puede supervisar el retraso de réplica de su clúster mediante las CloudWatch métricas de Amazon DBInstanceReplicaLag yDBClusterReplicaLagMaximum. Para obtener más información, consulte Supervisión de Amazon DocumentDB con CloudWatch.
A diferencia de la arquitectura monolítica tradicional de las bases de datos, Amazon DocumentDB separa el almacenamiento y la computación. Dada esta arquitectura moderna, le animamos a escalar la lectura en las instancias de réplica. Las lecturas en las instancias de réplica no bloquean la replicación de las escrituras desde la instancia principal. Puede añadir hasta 15 instancias de réplica de lectura en un clúster y escalar a millones de lecturas por segundo.
La ventaja principal de conectarse como conjunto de réplicas y distribuir las lecturas a las réplicas es que aumenta los recursos generales del clúster disponibles para utilizar la aplicación. Recomendamos que se conecte como conjunto de réplicas como práctica recomendada. Además, lo recomendamos con más frecuencia en las siguientes situaciones:
-
Si utiliza casi el 100 % de la CPU en la instancia principal.
-
Si la proporción de aciertos de la caché del búfer es casi cero.
-
Si alcanza los límites de conexión o cursor de una instancia.
Escalar el tamaño de una instancia de clúster es una opción y, en algunos casos, puede ser la mejor manera de escalar el clúster. Sin embargo, también deberá plantearse cómo aprovechar mejor las réplicas que ya tiene en el clúster. Esto le permite aumentar la escala sin el mayor coste de utilizar un tipo de instancia mayor. También le recomendamos que supervise estos límites y alerte al respecto (es decir CPUUtilizationDatabaseConnections, queBufferCacheHitRatio) utilice CloudWatch alarmas para saber cuándo se está haciendo un uso intensivo de un recurso.
Para obtener más información, consulte los temas siguientes:
Uso de las conexiones del clúster
Plantéese la posibilidad de utilizar todas las conexiones del clúster. Por ejemplo, una instancia r5.2xlarge tiene un límite de 4500 conexiones (y 450 cursores abiertos). Si crea un clúster de Amazon DocumentDB de tres instancias y se conecta únicamente a la instancia principal mediante el punto de conexión de clúster, los límites de conexiones y cursores abiertos del clúster son de 4500 y 450 respectivamente. Podría alcanzar estos límites al crear aplicaciones que utilizan muchos procesos de trabajo que se ponen en marcha en contenedores. Los contenedores abren una serie de conexiones a la vez y saturan el clúster.
En su lugar, podría conectarse al clúster de Amazon DocumentDB como conjunto de réplicas y distribuir las lecturas a las instancias de réplica. A continuación, podría triplicar de forma eficaz el número de conexiones y cursores disponibles en el clúster a 13 500 y 1350 respectivamente. Añadir más instancias al clúster solo aumenta el número de conexiones y cursores para las cargas de trabajo de lectura. Si necesita aumentar el número de conexiones para las escrituras en el clúster, recomendamos que aumente el tamaño de la instancia.
nota
El número de conexiones para las instancias large, xlarge y 2xlarge aumenta con el tamaño de instancia hasta 4500. El número máximo de conexiones por instancia para instancias 4xlarge o superiores es 4500. Para obtener más información sobre los límites por tipos de instancia, consulte Límites de instancias.
Normalmente, no recomendamos que se conecte al clúster con la preferencia de lectura de secondary. Esto se debe a que, si no hay instancias de réplica en el clúster, las lecturas generarán un error. Por ejemplo, suponga que tiene un clúster de Amazon DocumentDB de dos instancias con una instancia principal y una réplica. Si la réplica tiene un problema, se generará un error en las solicitudes de lectura de un grupo de conexiones establecido como secondary. La ventaja de secondaryPreferred es que, si el cliente no encuentra una instancia de réplica adecuada a la que conectarse, recurre a la instancia principal para las lecturas.
Varios grupos de conexiones
En algunos casos, las lecturas de una aplicación deben ser read-after-write coherentes, lo que solo se puede ofrecer desde la instancia principal de Amazon DocumentDB. En estos escenarios, puede crear dos grupos de conexiones de clientes: uno para escrituras y otro para lecturas que requieren read-after-write coherencia. Para ello, el código tendría un aspecto similar al siguiente.
## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as primary clientPrimary = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=primary') ## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as secondaryPreferred secondaryPreferred = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
Otra opción consiste en crear un único grupo de conexiones y sobrescribir la preferencia de lectura en una colección determinada.
##Specify the collection and set the read preference level for that collection col = db.review.with_options(read_preference=ReadPreference.SECONDARY_PREFERRED)
Resumen
Para aprovechar mejor los recursos del clúster, recomendamos que se conecte al clúster mediante el modo de conjunto de réplicas. Si es adecuado para la aplicación, puede escalar la lectura de la aplicación distribuyendo las lecturas a las instancias de réplica.
