Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Plano de control EKS
Amazon Elastic Kubernetes Service (EKS) es un servicio de Kubernetes administrado que le facilita la ejecución de Kubernetes en AWS sin necesidad de instalar, operar y mantener su propio plano de control de Kubernetes o nodos de trabajo. Funciona con Kubernetes en sentido ascendente y está certificado como compatible con Kubernetes. Esta conformidad garantiza que EKS sea compatible con Kubernetes, al igual que la versión comunitaria de código abierto que se puede instalar de forma APIs local o local. EC2 Las aplicaciones existentes que se ejecutan en Kubernetes upstream son compatibles con Amazon EKS.
EKS administra automáticamente la disponibilidad y la escalabilidad de los nodos del plano de control de Kubernetes y reemplaza automáticamente los nodos del plano de control en mal estado.
Arquitectura EKS
La arquitectura EKS está diseñada para eliminar cualquier punto único de fallo que pueda comprometer la disponibilidad y la durabilidad del plano de control de Kubernetes.
El plano de control de Kubernetes gestionado por EKS se ejecuta dentro de una VPC gestionada por EKS. El plano de control de EKS comprende la API de Kubernetes, los nodos del servidor, el clúster, etc. Nodos del servidor de API de Kubernetes que ejecutan componentes como el servidor de API o el programador y se ejecutan kube-controller-manager en un grupo de autoscalamiento. EKS ejecuta un mínimo de dos nodos de servidor de API en distintas zonas de disponibilidad (AZs) dentro de la región de AWS. Del mismo modo, para mayor durabilidad, los nodos del servidor etcd también se ejecutan en un grupo de autoscalamiento que abarca tres nodos. AZs EKS ejecuta una puerta de enlace NAT en cada zona de disponibilidad, y los servidores API y etcd se ejecutan en una subred privada. Esta arquitectura garantiza que un evento en una única zona de disponibilidad no afecte a la disponibilidad del clúster EKS.
Cuando crea un clúster nuevo, Amazon EKS crea un punto de enlace de alta disponibilidad para el servidor API de Kubernetes administrado que utiliza para comunicarse con el clúster (mediante herramientas como). kubectl El punto final administrado usa NLB para equilibrar la carga de los servidores de la API de Kubernetes. EKS también proporciona dos ENI diferentes AZs para facilitar la comunicación con sus nodos de trabajo.
Plano de datos EKS: conectividad de red
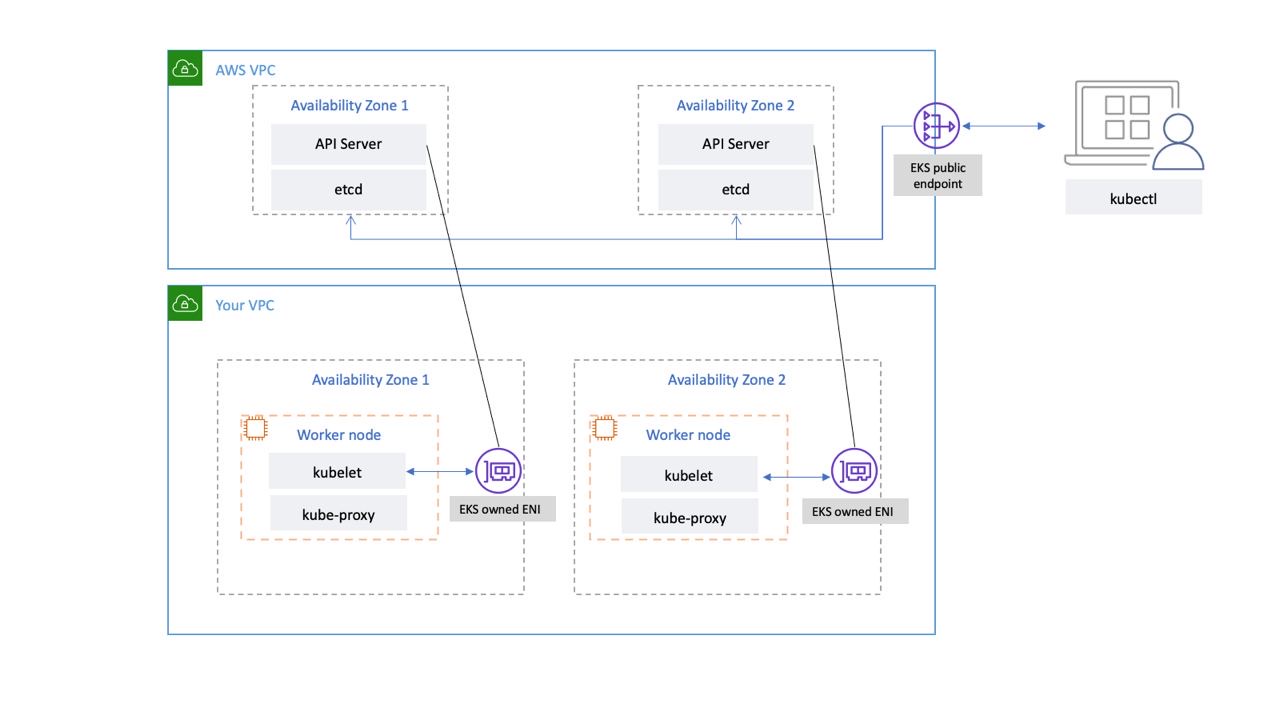
Puedes configurar si se puede acceder al servidor de API de tu clúster de Kubernetes desde la Internet pública (mediante el punto de conexión público) o a través de tu VPC (mediante el gestionado por EKS) o desde ambos. ENIs
Tanto si los usuarios como los nodos trabajadores se conectan al servidor de API mediante el punto final público o el ENI gestionado por EKS, existen rutas de conexión redundantes.
Recomendaciones
Revise las siguientes recomendaciones.
Supervise las métricas del plano de control
La supervisión de las métricas de la API de Kubernetes puede proporcionarte información sobre el rendimiento del plano de control e identificar problemas. Un plano de control defectuoso puede comprometer la disponibilidad de las cargas de trabajo que se ejecutan dentro del clúster. Por ejemplo, los controladores mal escritos pueden sobrecargar los servidores de la API y afectar a la disponibilidad de la aplicación.
Kubernetes expone las métricas del plano de control en el punto final. /metrics
Puede ver las métricas expuestas mediante: kubectl
kubectl get --raw /metrics
Estas métricas se representan en formato de texto de Prometheus
Puedes usar Prometheus para recopilar y almacenar estas métricas. En mayo de 2020, CloudWatch se agregó soporte para monitorear las métricas CloudWatch de Prometheus en Container Insights. Por lo tanto, también puede usar Amazon CloudWatch para monitorear el plano de control del EKS. Puede utilizar el tutorial para añadir un nuevo Prometheus Scrape Target: Prometheus KPI Server Metrics para recopilar métricas CloudWatch y crear un panel de control para supervisar el plano de control de su clúster.
Puedes encontrar las métricas del servidor API de Kubernetes aquí.apiserver_request_duration_seconds puede indicar cuánto tardan en ejecutarse las solicitudes de API.
Considere la posibilidad de monitorizar estas métricas del plano de control:
Servidor de API
| Métrica | Descripción |
|---|---|
|
|
Contador de solicitudes de apiserver desglosadas por verbo, valor de ensayo, grupo, versión, recurso, ámbito, componente y código de respuesta HTTP. |
|
|
Histograma de latencia de respuesta en segundos para cada verbo, valor de simulacro, grupo, versión, recurso, subrecurso, ámbito y componente. |
|
|
Histograma de latencia del controlador de admisión en segundos, identificado por su nombre y desglosado para cada operación y recurso y tipo de API (validar o admitir). |
|
|
Recuento de rechazos de webhooks de admisión. Se identifica por nombre, operación, código de rechazo, tipo (validando o admitiendo), tipo de error (calling_webhook_error, apiserver_internal_error, no_error) |
|
|
Solicita el histograma de latencia en segundos. Desglosado por verbo y URL. |
|
|
Número de solicitudes HTTP, fragmentadas por código de estado, método y host. |
-
Las métricas del histograma incluyen los sufijos _bucket, _sum y _count.
etc.d.
| Métrica | Descripción |
|---|---|
|
|
Etcd solicita el histograma de latencia en segundos para cada operación y tipo de objeto. |
|
|
Tamaño de la base de datos Etcd. |
-
Las métricas del histograma incluyen los sufijos _bucket, _sum y _count.
Considere la posibilidad de utilizar el panel de información general sobre la supervisión de Kubernetes para visualizar y supervisar
importante
Cuando se supera el límite de tamaño de la base de datos, etcd emite una alarma de falta de espacio y deja de recibir más solicitudes de escritura. En otras palabras, el clúster pasa a ser de solo lectura y el servidor de API del clúster rechazará todas las solicitudes para mutar objetos, como la creación de nuevos pods, el escalado de las implementaciones, etc.
Autenticación de
Actualmente, EKS admite dos tipos de autenticación: los tokens de cuentas portadoras/de servicio
El usuario o rol de IAM que crea el clúster de EKS obtiene automáticamente acceso total al clúster. Puede administrar el acceso al clúster de EKS editando el mapa de configuración de aws-auth.
Si configura mal el aws-auth mapa de configuración y pierde el acceso al clúster, puede seguir utilizando el usuario o el rol del creador del clúster para acceder a su clúster de EKS.
En el improbable caso de que no pueda usar el servicio de IAM en la región de AWS, también puede usar el token portador de la cuenta de servicio de Kubernetes para administrar el clúster.
Cree una super-admin cuenta que pueda realizar todas las acciones del clúster:
kubectl -n kube-system create serviceaccount super-admin
Cree un enlace de roles que asigne al superadministrador el rol de administrador del clúster:
kubectl create clusterrolebinding super-admin-rb --clusterrole=cluster-admin --serviceaccount=kube-system:super-admin
Obtén el secreto de la cuenta de servicio:
SECRET_NAME=`kubectl -n kube-system get serviceaccount/super-admin -o jsonpath='{.secrets[0].name}'`
Obtenga el token asociado al secreto:
TOKEN=`kubectl -n kube-system get secret $SECRET_NAME -o jsonpath='{.data.token}'| base64 --decode`
Agrega la cuenta de servicio y el token akubeconfig:
kubectl config set-credentials super-admin --token=$TOKEN
Defina el contexto actual para usar la cuenta kubeconfig de superadministrador:
kubectl config set-context --current --user=super-admin
La versión final kubeconfig debería tener este aspecto:
apiVersion: v1 clusters: - cluster: certificate-authority-data:<REDACTED> server: https://<CLUSTER>.gr7.us-west-2.eks.amazonaws.com name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> contexts: - context: cluster: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> user: super-admin name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> current-context: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> kind: Config preferences: {} users: #- name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> # user: # exec: # apiVersion: client.authentication.k8s.io/v1beta1 # args: # - --region # - us-west-2 # - eks # - get-token # - --cluster-name # - <<cluster name>> # command: aws # env: null - name: super-admin user: token: <<super-admin sa's secret>>
Webhooks de admisión
Kubernetes tiene dos tipos de webhooks de admisión: los webhooks de admisión validan y los webhooks de admisión mutantes
Para evitar afectar a las operaciones críticas del clúster, evite configurar webhooks «generales» como los siguientes:
- name: "pod-policy.example.com" rules: - apiGroups: ["*"] apiVersions: ["*"] operations: ["*"] resources: ["*"] scope: "*"
O bien, asegúrate de que el webhook tenga una política de apertura por error con un tiempo de espera inferior a 30 segundos para asegurarte de que, si tu webhook no está disponible, no afectará a las cargas de trabajo críticas del clúster.
Bloquee los pods con unsafe sysctls
Sysctles una utilidad de Linux que permite a los usuarios modificar los parámetros del núcleo durante el tiempo de ejecución. Estos parámetros del núcleo controlan varios aspectos del comportamiento del sistema operativo, como la red, el sistema de archivos, la memoria virtual y la administración de procesos.
Kubernetes permite asignar sysctl perfiles a los pods. Kubernetes se clasifica como seguro e inseguro. systcls Los espacios de nombres del contenedor o del pod sysctls son seguros, y configurarlos no afecta a los demás pods del nodo ni al nodo en sí. Por el contrario, los sysctls no seguros están deshabilitados de forma predeterminada, ya que pueden interrumpir otros pods o hacer que el nodo sea inestable.
Como sysctls los inseguros están deshabilitados de forma predeterminada, el kubelet no creará un pod con un perfil inseguro. sysctl Si creas un pod de este tipo, el programador los asignará repetidamente a los nodos, mientras que el nodo no podrá lanzarlo. En última instancia, este bucle infinito sobrecarga el plano de control del clúster, lo que hace que el clúster sea inestable.
Considera usar OPA Gatekeepersysctls
Gestión de las actualizaciones de clústeres
Desde abril de 2021, el ciclo de lanzamiento de Kubernetes ha cambiado de cuatro versiones al año (una vez por trimestre) a tres versiones al año. Una nueva versión secundaria (como la 1. 21 o 1. 22) se publica aproximadamente cada quince semanas
Conectividad de terminales de clúster
Al trabajar con Amazon EKS (Elastic Kubernetes Service), es posible que se produzcan errores o tiempos de espera de conexión durante eventos como el escalado del plano de control de Kubernetes o la aplicación de parches. Estos eventos pueden provocar el reemplazo de las instancias de kube-apiserver, lo que podría provocar que se devuelvan direcciones IP diferentes al resolver el FQDN. Este documento describe las mejores prácticas para que los consumidores de las API de Kubernetes mantengan una conectividad fiable.
nota
La implementación de estas mejores prácticas puede requerir actualizaciones en las configuraciones o los scripts de los clientes para gestionar las nuevas estrategias de reresolución y reintento del DNS de forma eficaz.
El principal problema se debe al almacenamiento en caché del DNS en el lado del cliente y a la posibilidad de que las direcciones IP de los terminales EKS queden obsoletas: NLB público para los terminales públicos o X-ENI para los terminales privados. Cuando se sustituyen las instancias de kube-apiserver, el nombre de dominio completo (FQDN) puede convertirse en nuevas direcciones IP. Sin embargo, debido a la configuración del tiempo de vida (TTL) del DNS, que se establece en 60 segundos en la zona Route 53 gestionada por AWS, los clientes pueden seguir utilizando direcciones IP anticuadas durante un breve período de tiempo.
Para mitigar estos problemas, los usuarios de las API de Kubernetes (como kubectl, CI/CD pipelines y aplicaciones personalizadas) deberían implementar las siguientes prácticas recomendadas:
-
Implemente la reresolución de DNS
-
Implemente los reintentos con Backoff y Jitter. Por ejemplo, consulte este artículo
titulado Los fallos ocurren -
Implemente los tiempos de espera de los clientes. Establezca los tiempos de espera adecuados para evitar que las solicitudes de larga duración bloqueen su aplicación. Tenga en cuenta que es posible que algunas bibliotecas cliente de Kubernetes, especialmente las generadas por los generadores de OpenAPI, no permitan configurar fácilmente los tiempos de espera personalizados.
-
Ejemplo 1 con kubectl:
kubectl get pods --request-timeout 10s # default: no timeout
-
Ejemplo 2 con Python: el cliente de Kubernetes proporciona
un parámetro _request_timeout
-
Al implementar estas mejores prácticas, puede mejorar significativamente la confiabilidad y la resiliencia de sus aplicaciones al interactuar con la API de Kubernetes. Recuerda probar estas implementaciones exhaustivamente, especialmente en condiciones de fallo simuladas, para asegurarte de que se comportan como se espera durante los eventos reales de escalado o aplicación de parches.
Ejecutar clústeres de gran tamaño
EKS monitorea activamente la carga en las instancias del plano de control y las escala automáticamente para garantizar un alto rendimiento. Sin embargo, debe tener en cuenta los posibles problemas y límites de rendimiento en Kubernetes y las cuotas en los servicios de AWS cuando ejecute clústeres grandes.
-
Según las pruebas realizadas
por el equipo, los clústeres con más de 1000 servicios pueden experimentar una latencia de red si se utilizan kube-proxyeniptablesmodo in. ProjectCalico La solución consiste en cambiar al ipvsmodo kube-proxy de ejecución. -
También es posible que se limiten las solicitudes de EC2 API si el CNI necesita solicitar direcciones IP para los pods o si necesitas crear nuevas EC2 instancias con frecuencia. Puedes reducir la EC2 API de llamadas configurando el CNI para que almacene en caché las direcciones IP. Puede usar tipos de EC2 instancias más grandes para reducir los eventos de EC2 escalado.
Recursos adicionales:
