Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Optimización de costos: redes
Diseñar sistemas para una alta disponibilidad (HA) es una práctica recomendada para lograr la resiliencia y la tolerancia a los fallos. En la práctica, esto significa distribuir las cargas de trabajo y la infraestructura subyacente en varias zonas de disponibilidad (AZs) de una región de AWS determinada. Asegurarse de que estas características estén implementadas en su entorno Amazon EKS mejorará la confiabilidad general de su sistema. Además, es probable que sus entornos EKS también estén compuestos por una variedad de estructuras (es decir VPCs), componentes (es decir) e integraciones (es decir, el ECR y otros registros de contenedores ELBs).
La combinación de sistemas de alta disponibilidad y otros componentes específicos para cada caso de uso puede desempeñar un papel importante en la forma en que se transfieren y procesan los datos. Esto, a su vez, repercutirá en los costes incurridos por la transferencia y el procesamiento de los datos.
Las prácticas que se detallan a continuación le ayudarán a diseñar y optimizar sus entornos de EKS a fin de lograr la rentabilidad en diferentes dominios y casos de uso.
Comunicación de pod a pod
Según la configuración, la comunicación de red y la transferencia de datos entre los pods pueden tener un impacto significativo en el costo total de ejecutar las cargas de trabajo de Amazon EKS. En esta sección se tratarán diferentes conceptos y enfoques para mitigar los costos relacionados con la comunicación entre los módulos, teniendo en cuenta las arquitecturas de alta disponibilidad (HA), el rendimiento de las aplicaciones y la resiliencia.
Restringir el tráfico a una zona de disponibilidad
Desde el principio, el proyecto Kubernetes comenzó a desarrollar estructuras sensibles a la topología, incluidas etiquetas como kubernetes. io/hostname, topology.kubernetes.io/region, and topology.kubernetes.io/zonese asignan a los nodos para habilitar funciones como la distribución de la carga de trabajo entre los dominios de fallas y los aprovisionadores de volúmenes sensibles a la topología. Tras licenciarse en Kubernetes 1.17, las etiquetas también se utilizaron para habilitar capacidades de enrutamiento con reconocimiento de topología para la comunicación de un pod a otro.
A continuación, se muestran algunas estrategias sobre cómo controlar la cantidad de tráfico entre zonas de disponibilidad y disponibilidad entre los pods de su clúster de EKS para reducir los costes y minimizar la latencia.
Si quieres ver de forma pormenorizada la cantidad de tráfico entre zonas de disponibilidad (Cross-AZ) entre los pods de tu clúster (por ejemplo, la cantidad de datos transferidos en bytes), consulta esta publicación
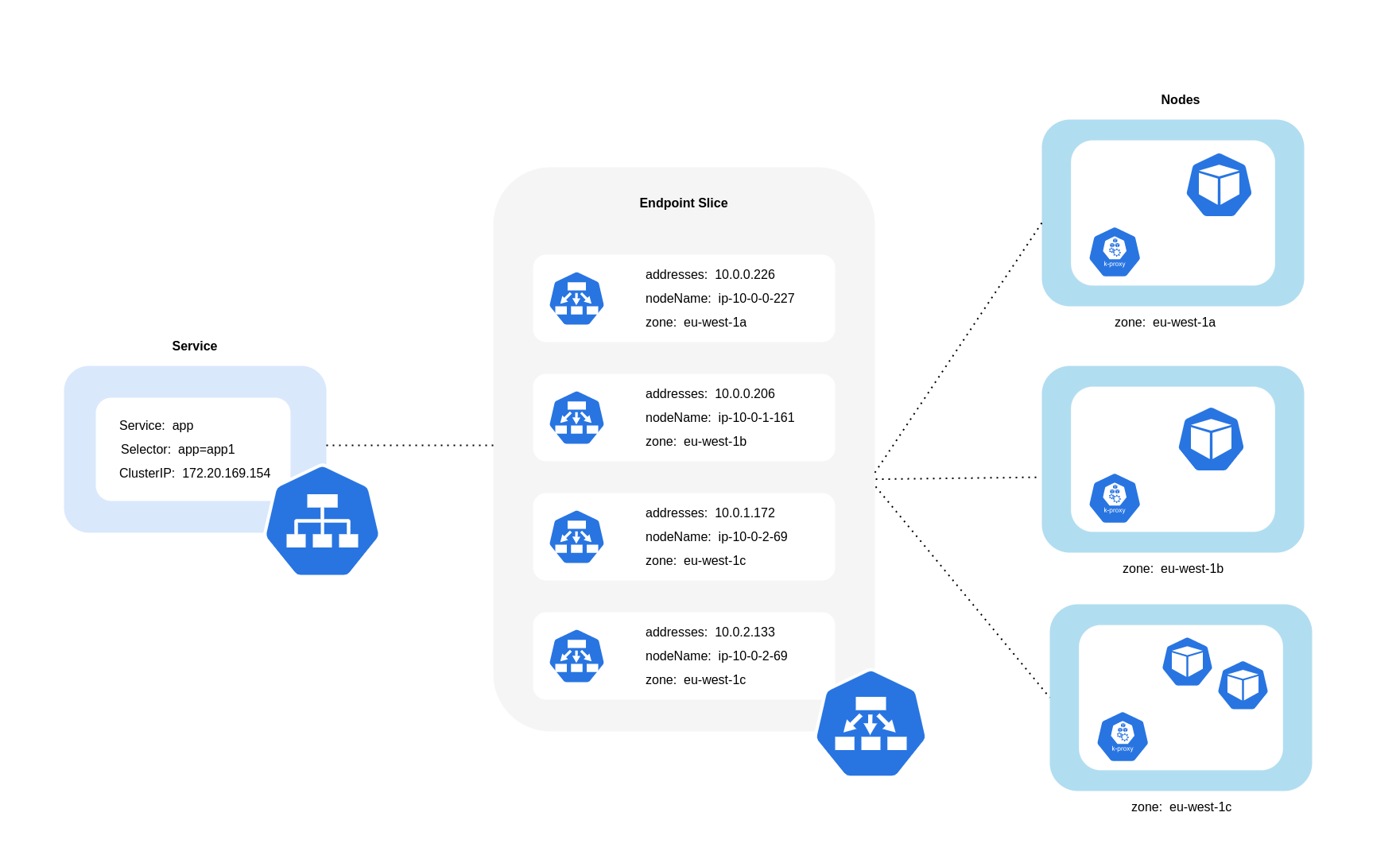
Como se muestra en el diagrama anterior, los servicios son la capa de abstracción de red estable que recibe el tráfico destinado a tus pods. Cuando se crea un servicio, EndpointSlices se crean varios. Cada uno EndpointSlice tiene una lista de puntos finales que contiene un subconjunto de direcciones de pod junto con los nodos en los que se ejecutan y cualquier información adicional sobre la topología. Cuando se utiliza la CNI de Amazon VPC, kube-proxy, un daemonset que se ejecuta en todos los nodos, mantiene las reglas de red para permitir la comunicación entre los pods y la detección de servicios (las alternativas basadas en EBPF pueden no utilizar kube-proxy pero ofrecer un comportamiento equivalente CNIs ). Cumple la función de enrutamiento interno, pero lo hace en función de lo que consume de lo creado. EndpointSlices
En EKS, kube-proxy utiliza principalmente las reglas NAT de iptables (o IPVS, NFTables
Uso del enrutamiento compatible con la topología (anteriormente denominado Topology Aware Hints)
Cuando el enrutamiento con reconocimiento de topologíakube-proxya continuación, enrutará el tráfico de una zona a un punto final en función de las sugerencias que se apliquen.
En el siguiente diagrama se muestra cómo EndpointSlices las sugerencias están organizadas de tal forma que kube-proxy permiten saber a qué destino deben dirigirse en función de su punto de origen zonal. Sin pistas, no existe tal asignación u organización y el tráfico se redirigirá a diferentes destinos zonales, independientemente de su procedencia.

En algunos casos, el EndpointSlice controlador puede aplicar una sugerencia para una zona diferente, lo que significa que el punto final podría terminar sirviendo tráfico que se origina en una zona diferente. El motivo es intentar mantener una distribución uniforme del tráfico entre los puntos finales de distintas zonas.
A continuación, se muestra un fragmento de código sobre cómo habilitar el enrutamiento con reconocimiento de topología para un servicio.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
La siguiente captura de pantalla muestra el resultado de que el EndpointSlice controlador haya aplicado correctamente una sugerencia a un punto final para una réplica de un pod que se ejecuta en la zona de disponibilidad. eu-west-1a

nota
Es importante tener en cuenta que el enrutamiento compatible con la topología aún se encuentra en versión beta. Esta función funciona de forma más predecible con cargas de trabajo distribuidas uniformemente en toda la topología del clúster, ya que el controlador asigna los puntos finales de forma proporcional entre las zonas, pero puede omitir las asignaciones de sugerencias cuando los recursos de los nodos de una zona están demasiado desequilibrados como para evitar una sobrecarga excesiva. Por lo tanto, se recomienda encarecidamente utilizarla junto con las restricciones de programación que aumenten la disponibilidad de una aplicación, como las restricciones de dispersión de la topología de los módulos.
Uso de la distribución del tráfico
Introducido en Kubernetes 1.30 y puesto a disposición del público en general en 1.33, Traffic Distribution ofrece una alternativa más sencilla al enrutamiento compatible con la topología para preferir el tráfico
A continuación se muestra un fragmento de código sobre cómo habilitar la distribución del tráfico para un servicio.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
Al habilitar la distribución del tráfico, surge un desafío común: los puntos finales dentro de una única zona de disponibilidad pueden sobrecargarse si la mayor parte del tráfico se origina en esa misma zona. Esta sobrecarga puede crear problemas importantes:
-
Un escalador automático de pods horizontal (HPA) único que gestione una implementación en zonas de disponibilidad múltiples puede responder escalando los pods en diferentes áreas de disponibilidad. AZs Sin embargo, esta acción no aborda de manera eficaz el aumento de la carga en la zona afectada.
-
Esta situación, a su vez, puede provocar una ineficiencia de los recursos. Cuando los escaladores automáticos de clústeres, como Karpenter, detectan que el módulo se amplía de forma horizontal, pueden aprovisionar nodos adicionales en los que no estén afectados AZs, lo que se traduce en una asignación de recursos AZs innecesaria.
Para superar este desafío:
-
Cree despliegues separados por zona que tengan los suyos propios HPAs para escalar de forma independiente unos de otros.
-
Aproveche las restricciones de distribución de la topología para garantizar la distribución de la carga de trabajo en todo el clúster, lo que ayuda a evitar la sobrecarga de los puntos finales en las zonas de alto tráfico.
Uso de escaladores automáticos: aprovisione nodos a una zona de disponibilidad específica
Recomendamos encarecidamente ejecutar las cargas de trabajo en varios entornos de alta disponibilidad. AZs Esto mejora la confiabilidad de sus aplicaciones, especialmente cuando se produce un incidente o un problema con una zona de disponibilidad. En caso de que esté dispuesto a sacrificar la confiabilidad para reducir los costos relacionados con la red, puede restringir sus nodos a una única zona de disponibilidad.
Para ejecutar todos los pods en la misma zona de disponibilidad, aprovisione los nodos de trabajo en la misma zona de disponibilidad o programe los pods de los nodos de trabajo para que se ejecuten en la misma zona de disponibilidad. Para aprovisionar nodos dentro de una única AZ, defina un grupo de nodos con subredes que pertenezcan a la misma AZ con Cluster Autoscaler (CA)topology.kubernetes.io/zone y especifique la AZ en la que desea crear los nodos de trabajo. Por ejemplo, el siguiente fragmento de código de aprovisionamiento de Karpenter aprovisiona los nodos de la zona de distribución us-west-2a.
Karpenter
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
Escalador automático de clústeres (CA)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
Uso de la asignación de pods y la afinidad de nodos
Como alternativa, si tienes nodos de trabajo que se ejecutan en varios nodos AZs, cada nodo tendría la etiqueta topology.kubernetes.io/zone con el valor de su zonanodeSelector nodeAffinity Por ejemplo, el siguiente archivo de manifiesto programará el pod dentro de un nodo que se ejecute en la AZ us-west-2a.
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
Restringir el tráfico a un nodo
Hay casos en los que restringir el tráfico a nivel zonal no es suficiente. Además de reducir los costes, es posible que tengas el requisito adicional de reducir la latencia de la red entre determinadas aplicaciones que tienen una intercomunicación frecuente. Para lograr un rendimiento de red óptimo y reducir los costos, necesita una forma de restringir el tráfico a un nodo específico. Por ejemplo, el microservicio A siempre debe comunicarse con el microservicio B en el nodo 1, incluso en configuraciones de alta disponibilidad (HA). Hacer que el microservicio A en el nodo 1 se comunique con el microservicio B en el nodo 2 puede tener un impacto negativo en el rendimiento deseado para aplicaciones de esta naturaleza, especialmente si el nodo 2 está completamente en una zona de disponibilidad separada.
Uso de la política de tráfico interna del servicio
Para restringir el tráfico de la red del Pod a un nodo, puedes utilizar la política de tráfico interna del ServicioLocal, el tráfico se restringirá a los puntos finales del nodo desde el que se originó el tráfico. Esta política dicta el uso exclusivo de los puntos finales locales de los nodos. Por lo tanto, los costos relacionados con el tráfico de red para esa carga de trabajo serán más bajos que si la distribución se realizara en todo el clúster. Además, la latencia será menor, lo que aumentará el rendimiento de la aplicación.
nota
Es importante tener en cuenta que esta función no se puede combinar con el enrutamiento compatible con la topología en Kubernetes.
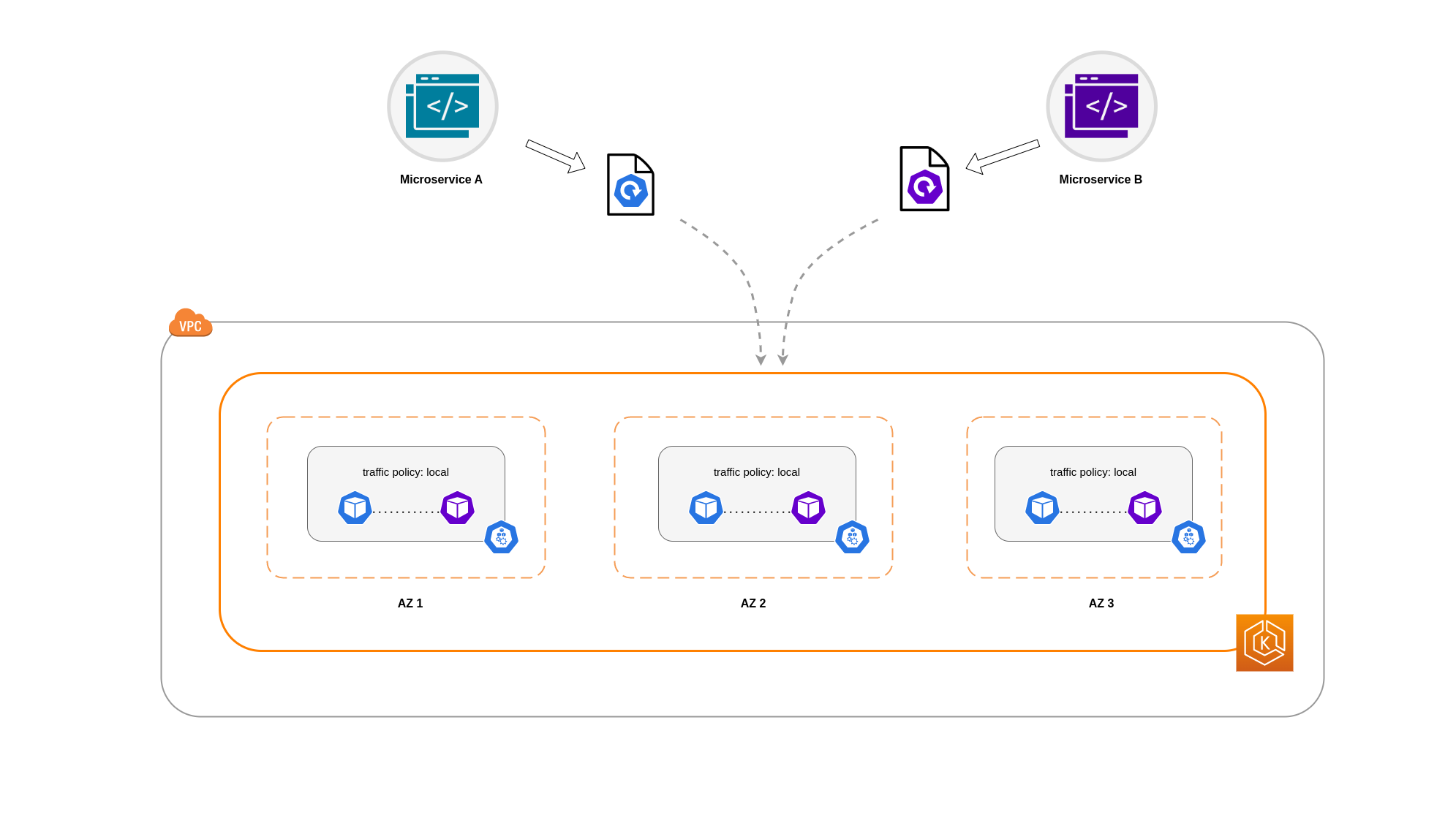
A continuación se muestra un fragmento de código sobre cómo configurar la política de tráfico interno de un servicio.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
Para evitar que tu aplicación se comporte de forma inesperada debido a las caídas de tráfico, debes considerar los siguientes enfoques:
-
Ejecuta suficientes réplicas para cada uno de los pods que se comunican
-
Tenga una distribución relativamente uniforme de los pods utilizando restricciones de dispersión topológica
-
Utiliza las reglas de afinidad entre los pods para la
ubicación conjunta de los pods que se comunican
En este ejemplo, tiene 2 réplicas del microservicio A y 3 réplicas del microservicio B. Si el microservicio A tiene sus réplicas distribuidas entre los nodos 1 y 2, y el microservicio B tiene las 3 réplicas en el nodo 3, no podrán comunicarse debido a la política de tráfico interna. Local Cuando no hay puntos de enlace locales disponibles en los nodos, se interrumpe el tráfico.
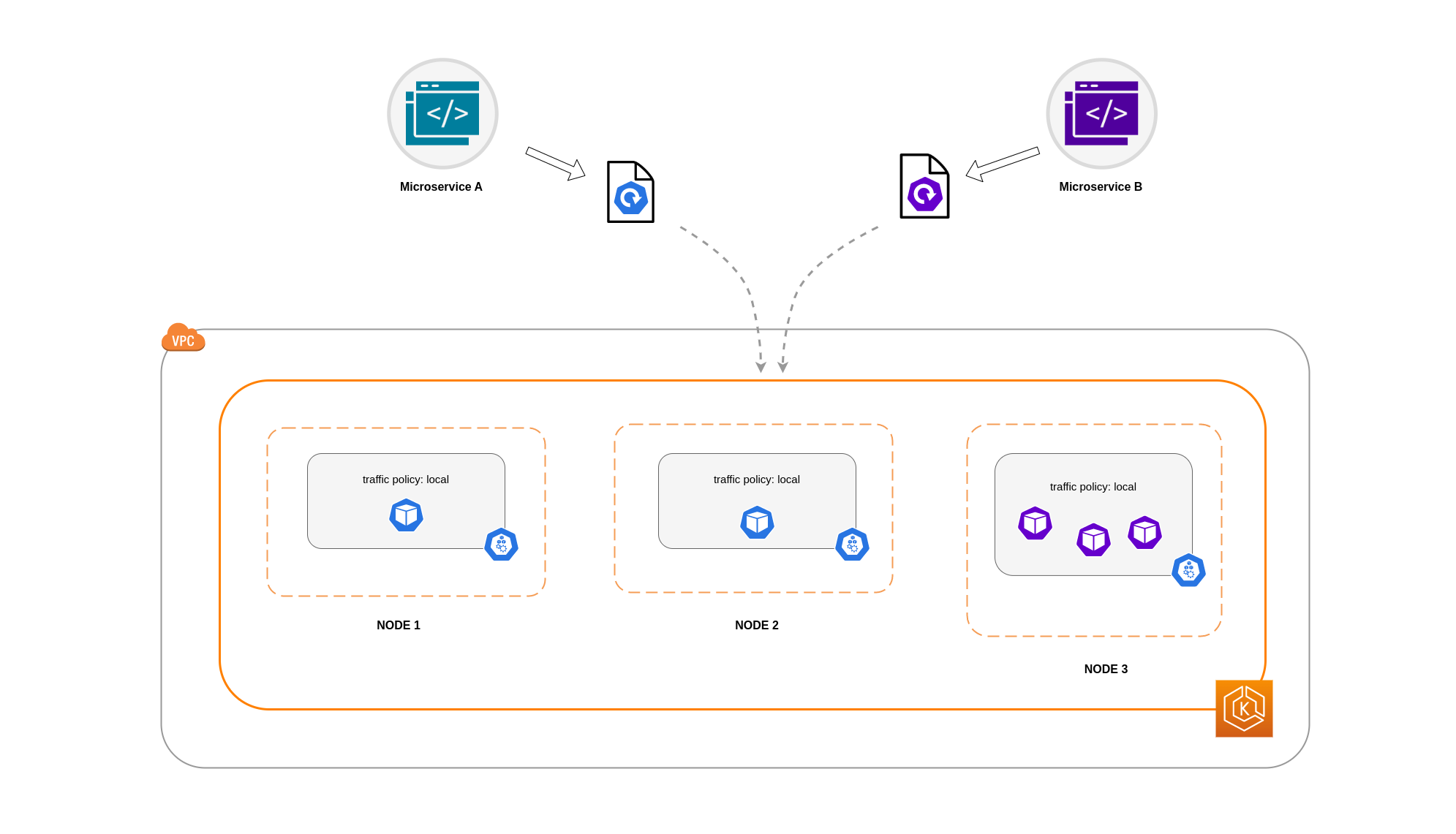
Si el microservicio B tiene 2 de sus 3 réplicas en los nodos 1 y 2, habrá comunicación entre las aplicaciones homólogas. Sin embargo, seguiría teniendo una réplica aislada del microservicio B sin ninguna réplica homóloga con la que comunicarse.
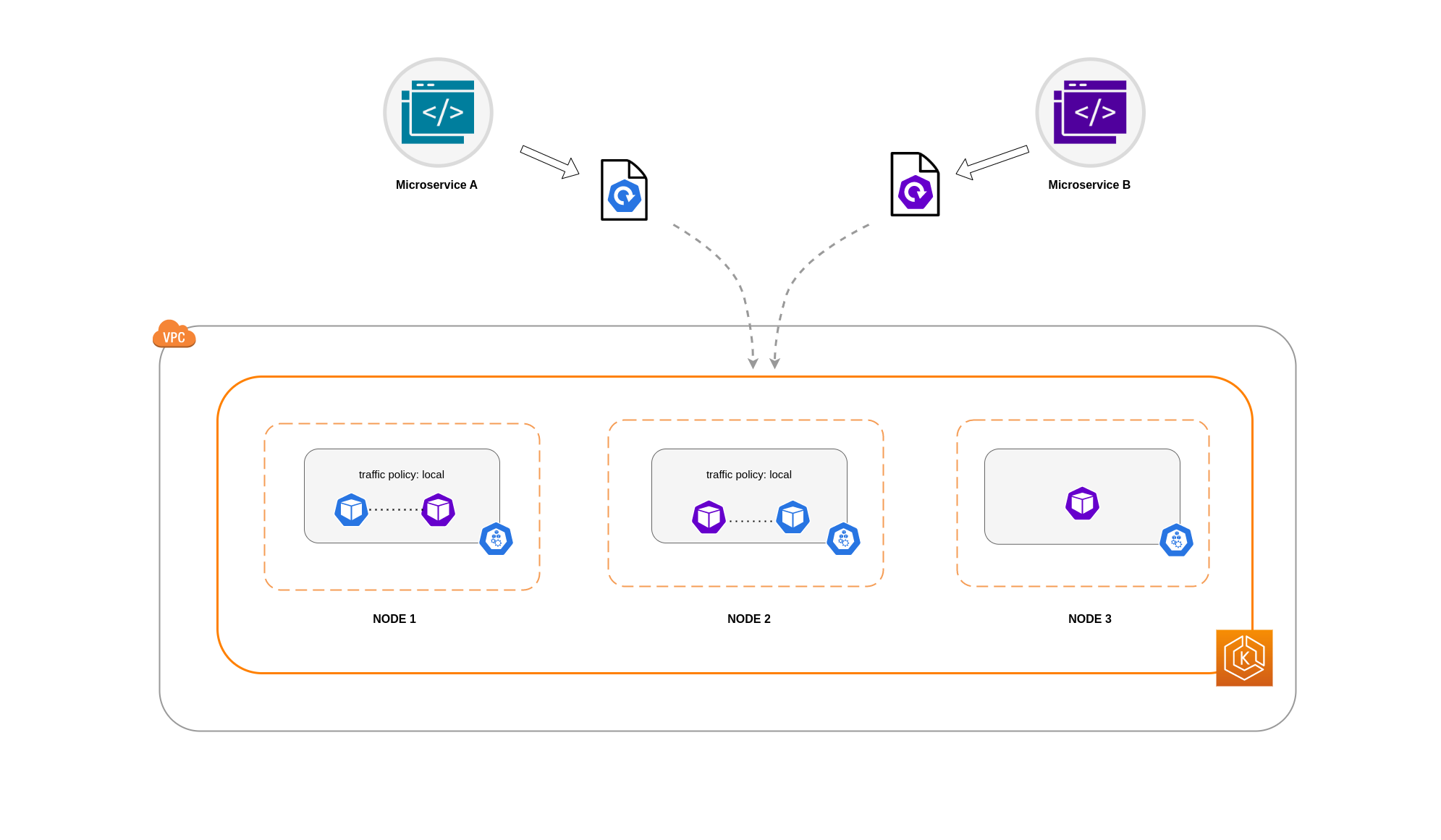
nota
En algunos escenarios, una réplica aislada como la que se muestra en el diagrama anterior puede no ser motivo de preocupación si sigue cumpliendo un propósito (por ejemplo, atender solicitudes del tráfico entrante externo).
Uso de la política de tráfico interno del servicio con restricciones de dispersión topológica
El uso de la política de tráfico interna junto con las restricciones de dispersión de la topología puede resultar útil para garantizar que se dispone del número correcto de réplicas para comunicar los microservicios en los distintos nodos.
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
Uso de la política de tráfico interno del servicio con las reglas de afinidad de los pods
Otro enfoque consiste en utilizar las reglas de afinidad de los pods al utilizar la política de tráfico interna del Servicio. Gracias a la afinidad por los pods, puedes influir en el programador para que ubique determinados pods en un mismo lugar, ya que se comunican con frecuencia. Si aplicas restricciones de programación estrictas (requiredDuringSchedulingIgnoredDuringExecution) a determinados pods, obtendrás mejores resultados en cuanto a la ubicación conjunta de los pods cuando el programador coloque los pods en nodos.
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Comunicación entre Load Balancer y Pod
Las cargas de trabajo de EKS suelen estar respaldadas por un balanceador de cargas que distribuye el tráfico a los pods correspondientes del clúster de EKS. Su arquitectura puede incluir balanceadores de carga internos y and/or externos. Según la arquitectura y las configuraciones del tráfico de la red, la comunicación entre los balanceadores de carga y los pods puede contribuir en gran medida a los gastos de transferencia de datos.
Puede utilizar el controlador Load Balancer de AWS
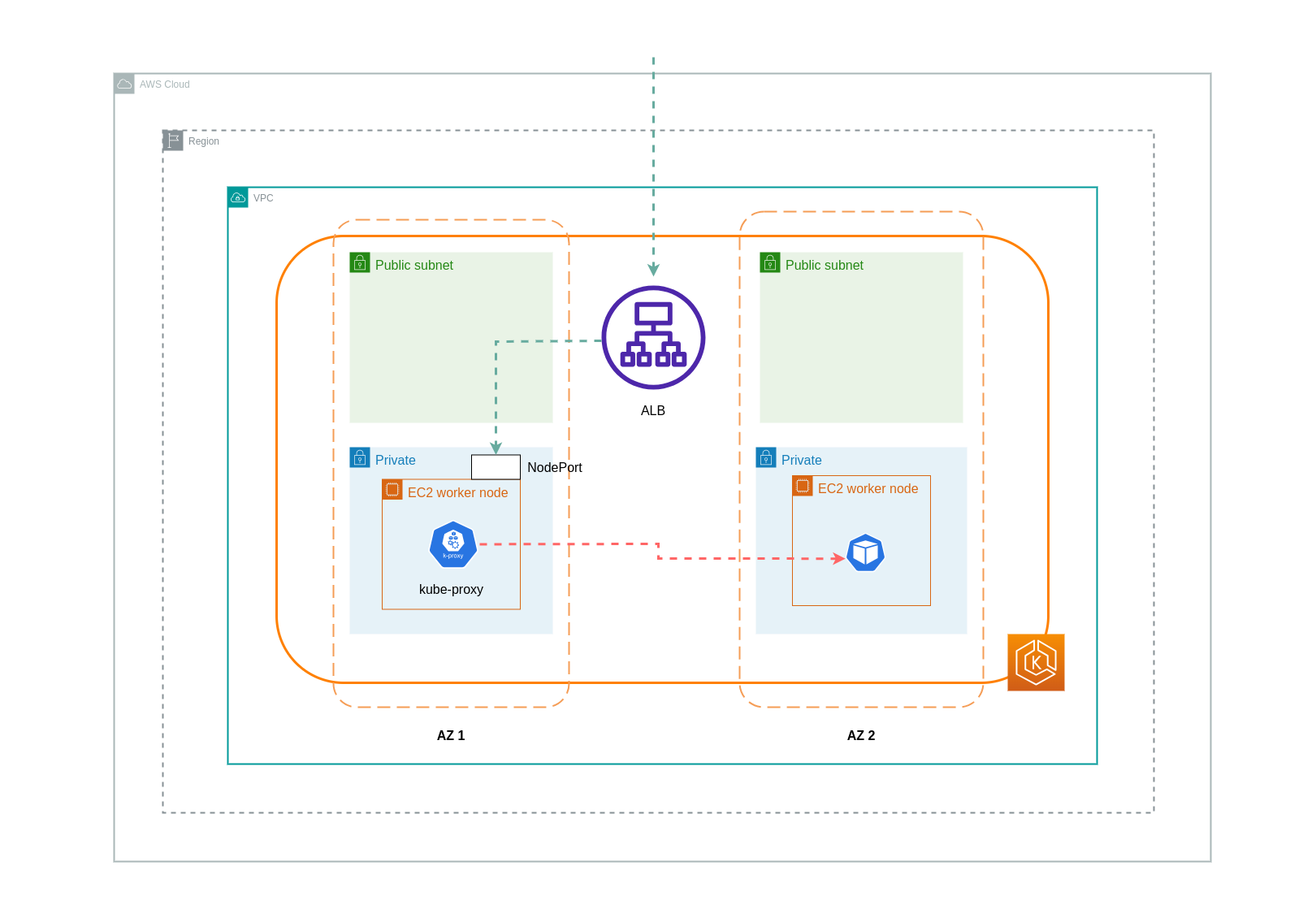
Cuando utilice el modo instancia, se NodePort abrirá una en cada nodo del clúster de EKS. A continuación, el balanceador de cargas distribuirá el tráfico de manera uniforme entre los nodos. Si un nodo tiene el pod de destino en ejecución, no se incurrirá en costes de transferencia de datos. Sin embargo, si el pod de destino está en un nodo independiente y en una zona de disponibilidad diferente a la que NodePort recibe el tráfico, habrá un salto de red adicional desde el kube-proxy al pod de destino. En tal escenario, se cobrarán cargos por la transferencia de datos entre zonas de disponibilidad. Debido a la distribución uniforme del tráfico entre los nodos, es muy probable que los saltos de tráfico de red entre zonas desde los proxies de Kube a los pods de destino correspondientes conlleven gastos adicionales por la transferencia de datos.
En el siguiente diagrama, se muestra una ruta de red para el tráfico que va del balanceador de cargas al pod de destino y NodePort, posteriormente, al pod de destino en un kube-proxy nodo independiente de una zona de disponibilidad diferente. Este es un ejemplo de la configuración del modo de instancia.
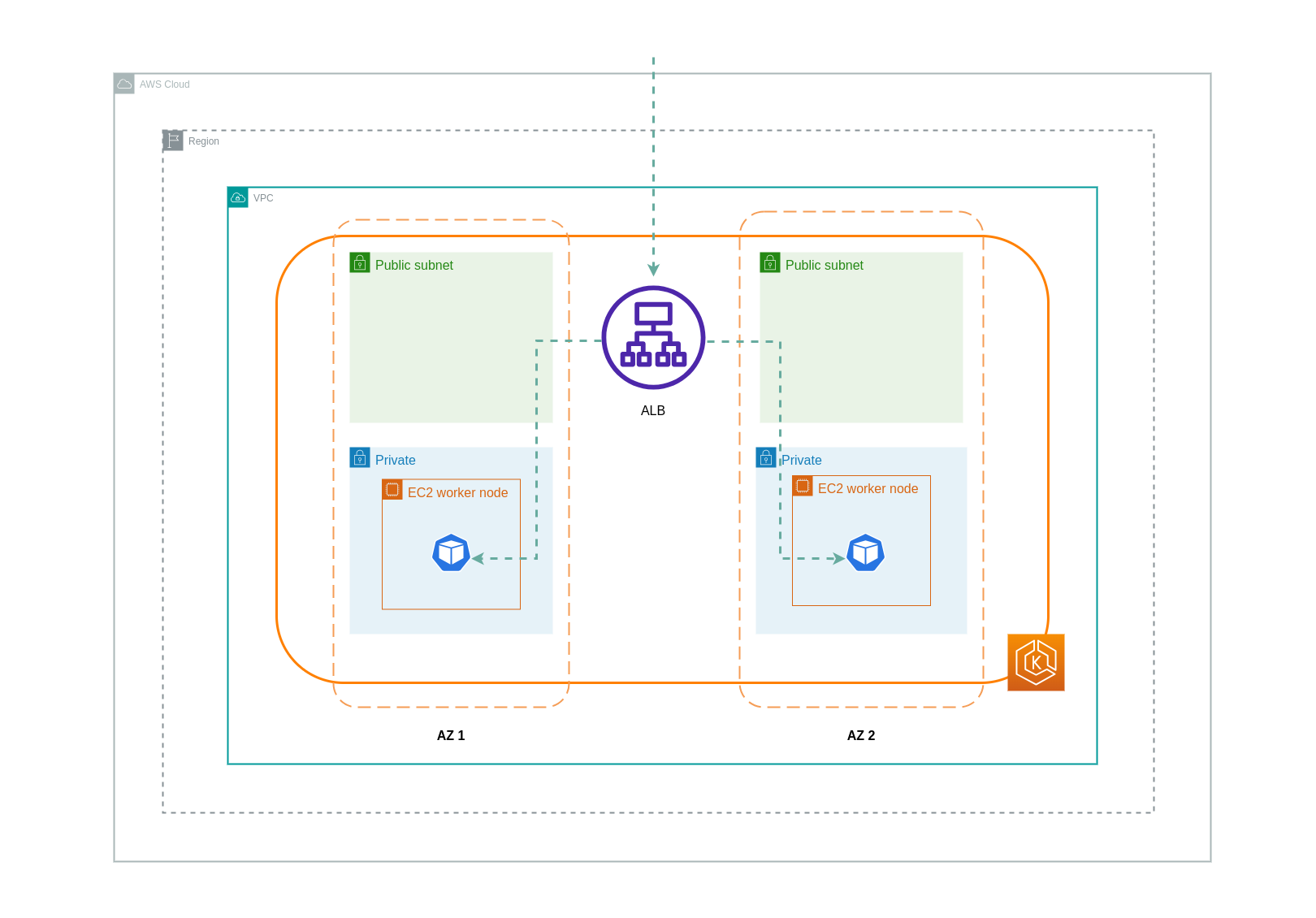
Cuando se utiliza el modo ip, el tráfico de red se envía por proxy desde el balanceador de cargas directamente al pod de destino. Como resultado, este enfoque no implica gastos de transferencia de datos.
nota
Se recomienda configurar el balanceador de carga en modo de tráfico IP para reducir los cargos por transferencia de datos. Para esta configuración, también es importante asegurarse de que el balanceador de carga esté implementado en todas las subredes de la VPC.
En el siguiente diagrama, se muestran las rutas de red del tráfico que fluye desde el balanceador de cargas a los pods en el modo IP de la red.
Transferencia de datos desde el registro de contenedores
Amazon ECR
La transferencia de datos al registro privado de Amazon ECR es gratuita. La transferencia de datos dentro de una región es gratuita, pero la transferencia de datos a Internet y entre regiones se cobrará según las tarifas de transferencia de datos por Internet en ambos lados de la transferencia.
Debe utilizar la función de replicación de imágenes ECRs integrada para replicar las imágenes del contenedor pertinentes en la misma región que sus cargas de trabajo. De esta forma, la replicación se cobraría una sola vez y todas las extracciones de imágenes de una misma región (intrarregión) serían gratuitas.
Puede reducir aún más los costos de transferencia de datos asociados con la extracción de imágenes de la ECR (transferencia de datos saliente) mediante el uso de puntos finales de VPC de interfaz para conectarse a los repositorios de ECR de la región. El enfoque alternativo de conectarse al punto final público de AWS del ECR (a través de una puerta de enlace NAT y una puerta de enlace de Internet) generará mayores costos de procesamiento y transferencia de datos. En la siguiente sección, se analizará con más detalle la reducción de los costes de transferencia de datos entre sus cargas de trabajo y los servicios de AWS.
Si ejecuta cargas de trabajo con imágenes especialmente grandes, puede crear sus propias Amazon Machine Images (AMIs) personalizadas con imágenes de contenedores prealmacenadas en caché. Esto puede reducir el tiempo inicial de extracción de la imagen y los posibles costes de transferencia de datos desde un registro de contenedores a los nodos de trabajo de EKS.
Transferencia de datos a Internet y a los servicios de AWS
Es una práctica habitual integrar las cargas de trabajo de Kubernetes con otros servicios de AWS o herramientas y plataformas de terceros a través de Internet. La infraestructura de red subyacente utilizada para enrutar el tráfico hacia y desde el destino correspondiente puede afectar a los costos incurridos en el proceso de transferencia de datos.
Uso de pasarelas NAT
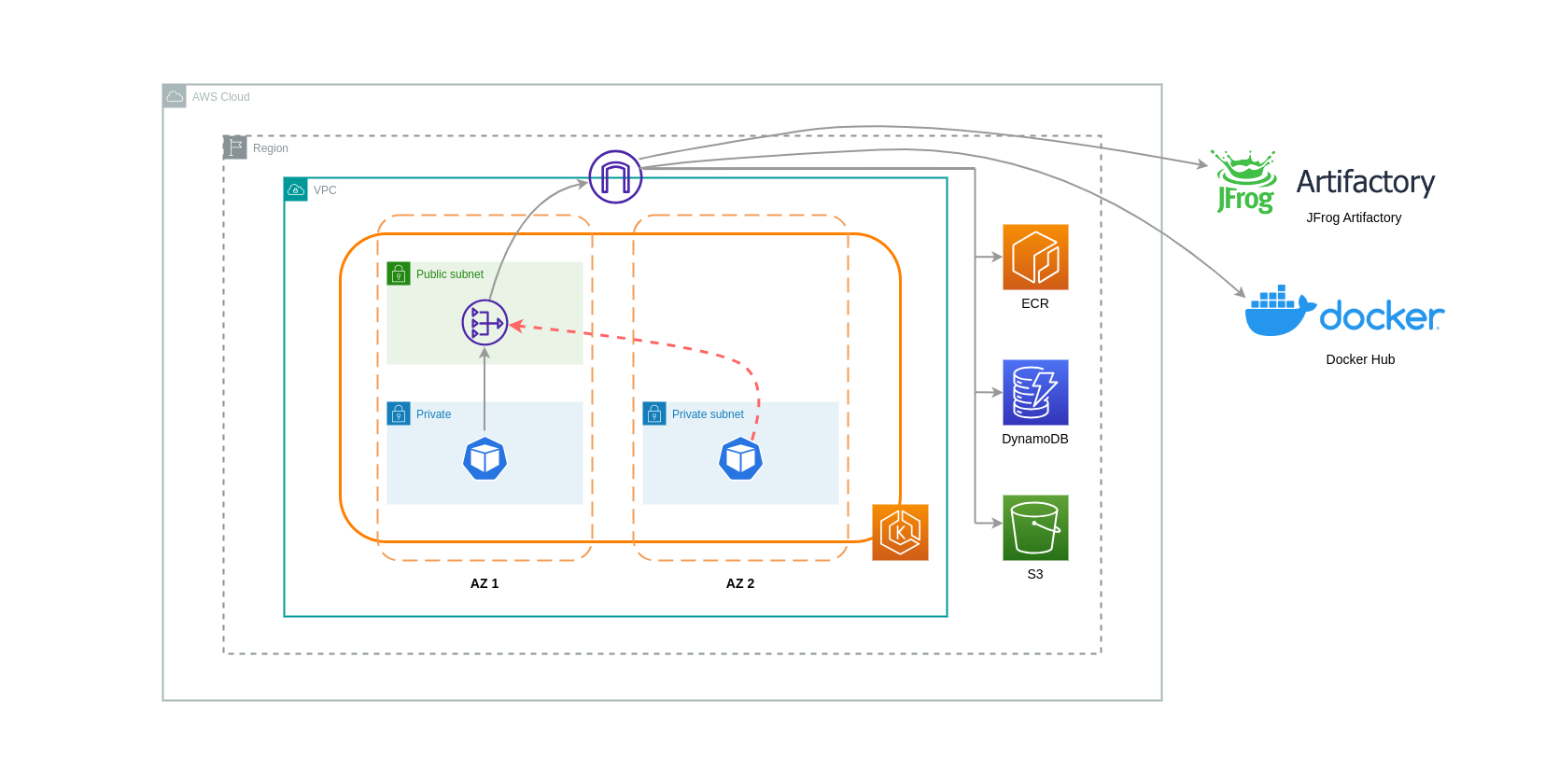
Las puertas de enlace NAT son componentes de red que realizan la traducción de direcciones de red (NAT). El siguiente diagrama muestra los pods de un clúster de EKS que se comunican con otros servicios de AWS (Amazon ECR, DynamoDB y S3) y plataformas de terceros. En este ejemplo, los pods se ejecutan en subredes privadas separadas. AZs Para enviar y recibir tráfico de Internet, se implementa una puerta de enlace NAT en la subred pública de una zona de disponibilidad, lo que permite que cualquier recurso con direcciones IP privadas comparta una única dirección IP pública para acceder a Internet. Esta puerta de enlace NAT, a su vez, se comunica con el componente de puerta de enlace de Internet, lo que permite enviar los paquetes a su destino final.
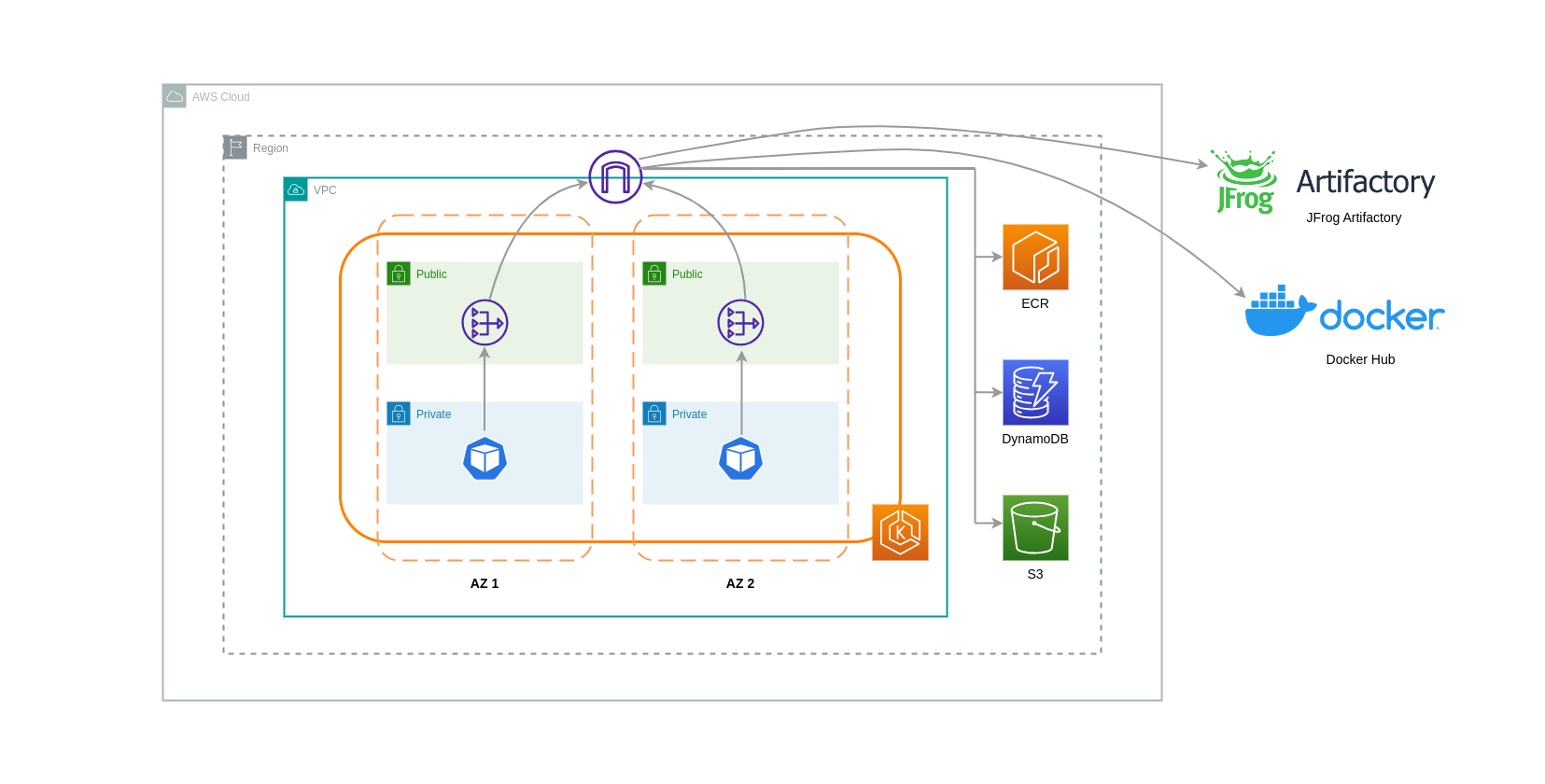
Al utilizar pasarelas NAT para estos casos de uso, puede minimizar los costes de transferencia de datos mediante la implementación de una pasarela NAT en cada zona de disponibilidad. De esta forma, el tráfico dirigido a Internet pasará por la puerta de enlace NAT en la misma zona de disponibilidad, lo que evitará la transferencia de datos entre zonas de disponibilidad. Sin embargo, aunque ahorrará en el costo de la transferencia de datos entre zonas de disponibilidad, esta configuración implica que incurrirá en el costo de una puerta de enlace NAT adicional en su arquitectura.
Este enfoque recomendado se muestra en el siguiente diagrama.
Usar un punto de enlace de la VPC
Para reducir aún más los costos en dichas arquitecturas, debe usar los puntos de enlace de VPC para establecer la conectividad entre sus cargas de trabajo y los servicios de AWS. Los puntos de enlace de la VPC le permiten acceder a los servicios de AWS desde una VPC sin data/network que los paquetes atraviesen Internet. Todo el tráfico es interno y permanece dentro de la red de AWS. Hay dos tipos de puntos de enlace de VPC: puntos de enlace de VPC de interfaz (compatibles con muchos servicios de AWS) y puntos de enlace de VPC de puerta de enlace (solo compatibles con S3 y DynamoDB).
Puntos finales de VPC de Gateway
No hay costes por hora ni de transferencia de datos asociados a los puntos finales de VPC de Gateway. Al utilizar los puntos de enlace de VPC de Gateway, es importante tener en cuenta que no se pueden extender más allá de los límites de la VPC. No se pueden usar en la interconexión de VPC, en redes VPN ni a través de Direct Connect.
Puntos finales de VPC de interfaz
Los puntos finales de VPC tienen un cargo por hora y un cargo
En el siguiente diagrama, se muestran los pods que se comunican con los servicios de AWS a través de puntos de enlace de VPC.
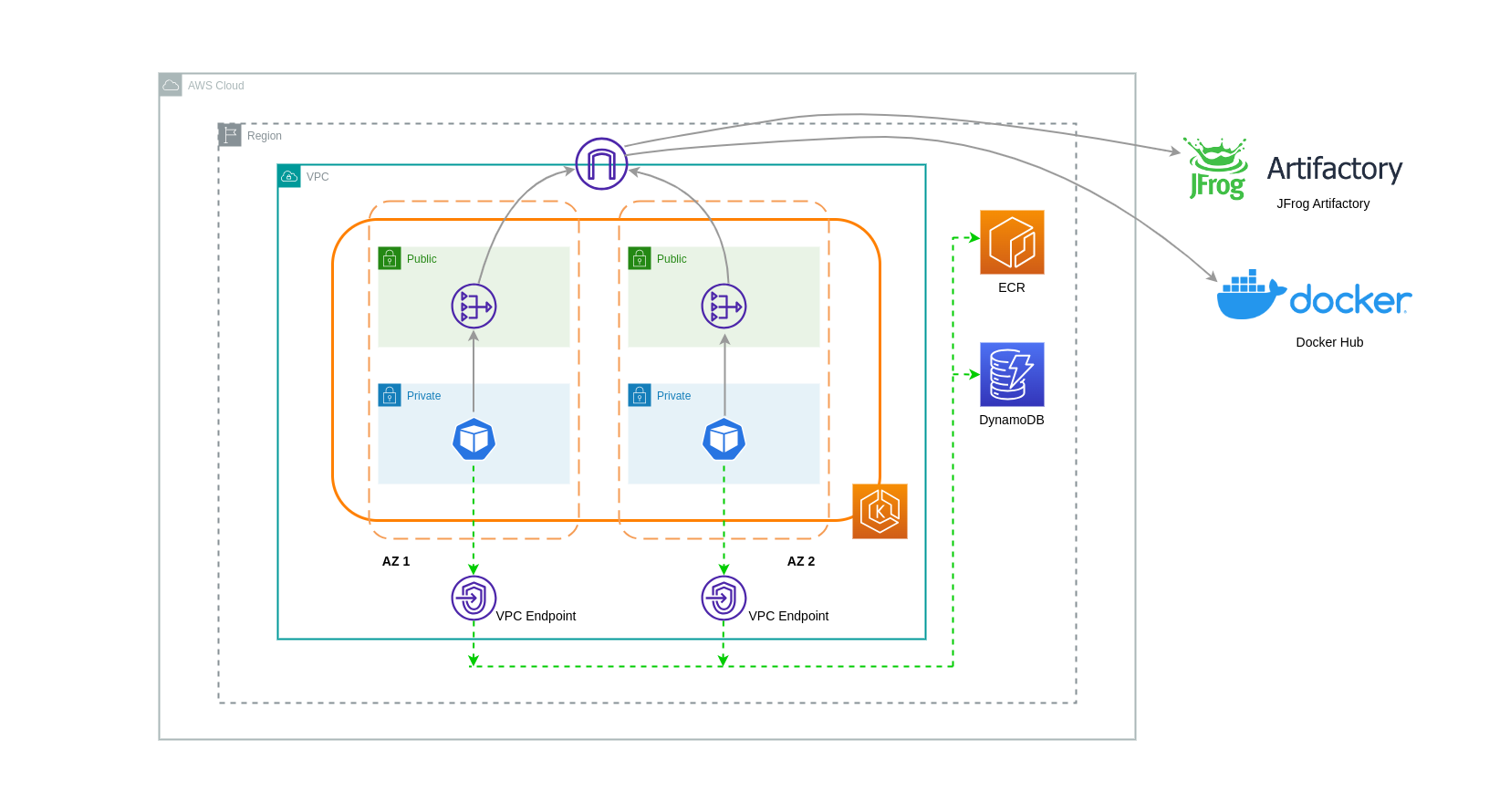
Transferencia de datos entre VPCs
En algunos casos, es posible que tenga cargas de trabajo distintas VPCs (dentro de la misma región de AWS) que necesiten comunicarse entre sí. Esto se puede lograr permitiendo que el tráfico atraviese la Internet pública a través de las pasarelas de Internet conectadas a las respectivas. VPCs Esta comunicación se puede habilitar mediante la implementación de componentes de infraestructura como EC2 instancias, pasarelas NAT o instancias NAT en subredes públicas. Sin embargo, una configuración que incluya estos componentes generará cargos por la entrada y salida de processing/transferring los datos. VPCs Si el tráfico hacia y desde la unidad VPCs es transversal AZs, se cobrará un cargo adicional por la transferencia de datos. El siguiente diagrama muestra una configuración que utiliza puertas de enlace NAT y puertas de enlace de Internet para establecer la comunicación entre cargas de trabajo de diferentes tipos. VPCs
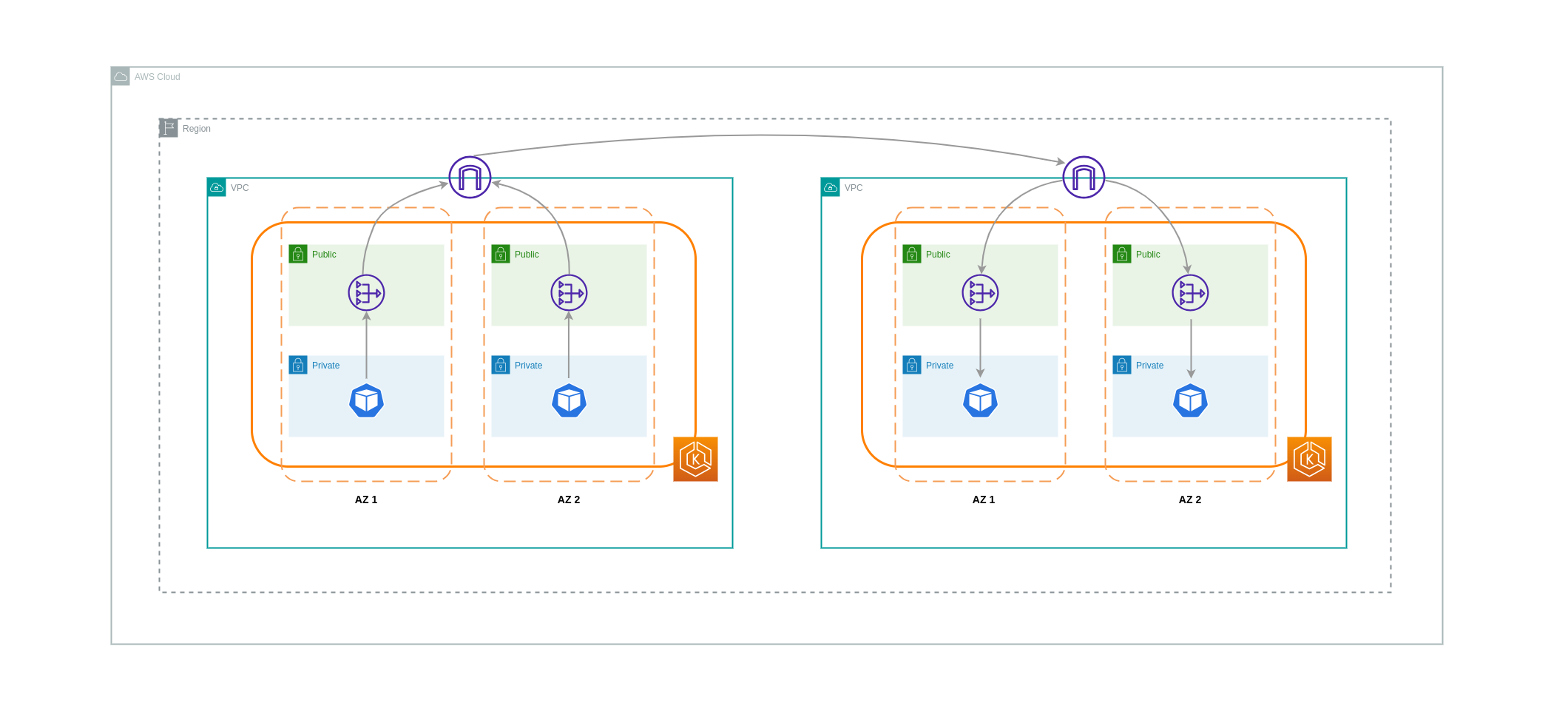
Interconexiones de VPC
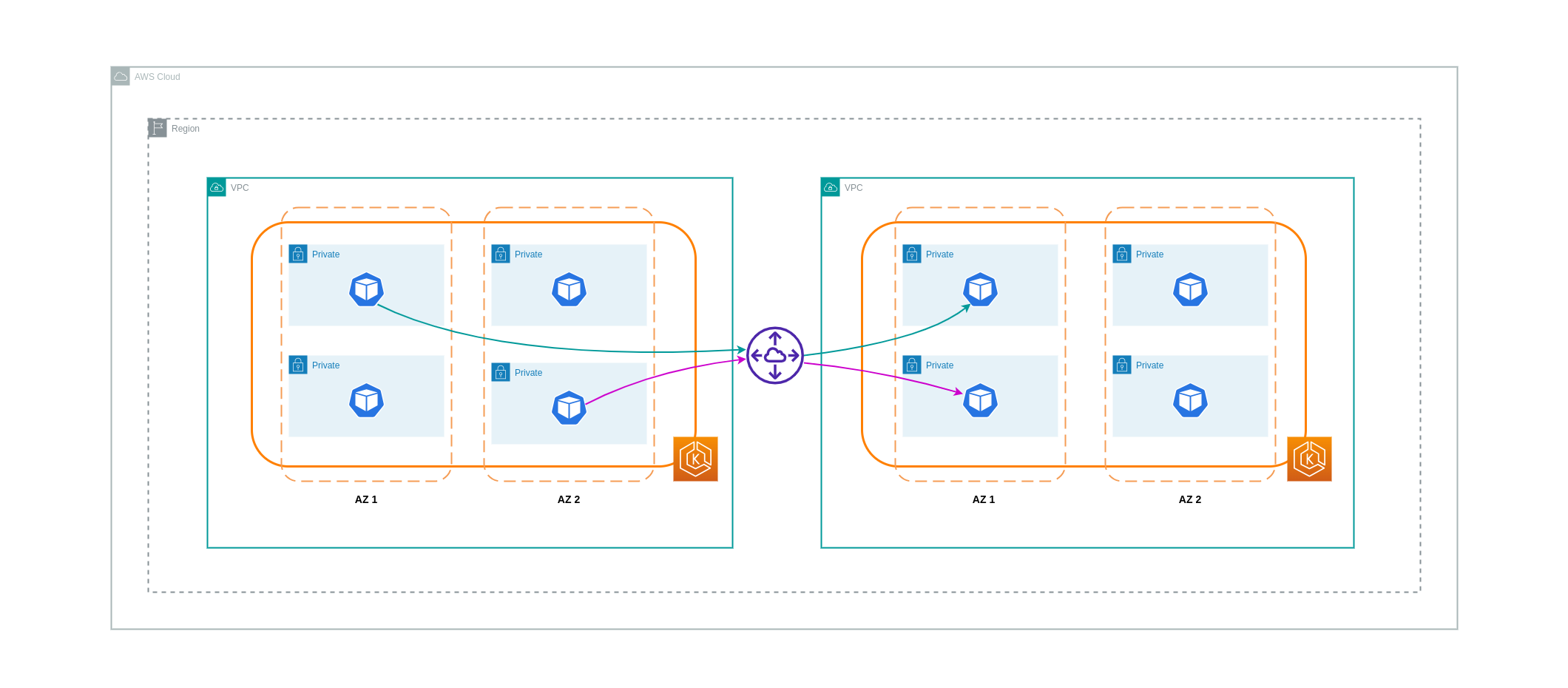
Para reducir los costes de estos casos de uso, puede utilizar el emparejamiento de VPC. Con una conexión de interconexión de VPC, no se cobran cargos por transferencia de datos para el tráfico de red que permanece dentro de la misma zona de disponibilidad. Si el tráfico se cruza AZs, se incurrirá en un coste. No obstante, se recomienda el enfoque de emparejamiento de VPC para una comunicación rentable entre cargas de trabajo independientes dentro de VPCs la misma región de AWS. Sin embargo, es importante tener en cuenta que la interconexión de VPC es principalmente eficaz para la conectividad de VPC 1:1 porque no permite la creación de redes transitivas.
El siguiente diagrama es una representación de alto nivel de la comunicación de las cargas de trabajo a través de una conexión de emparejamiento de VPC.
Conexiones de red transitivas
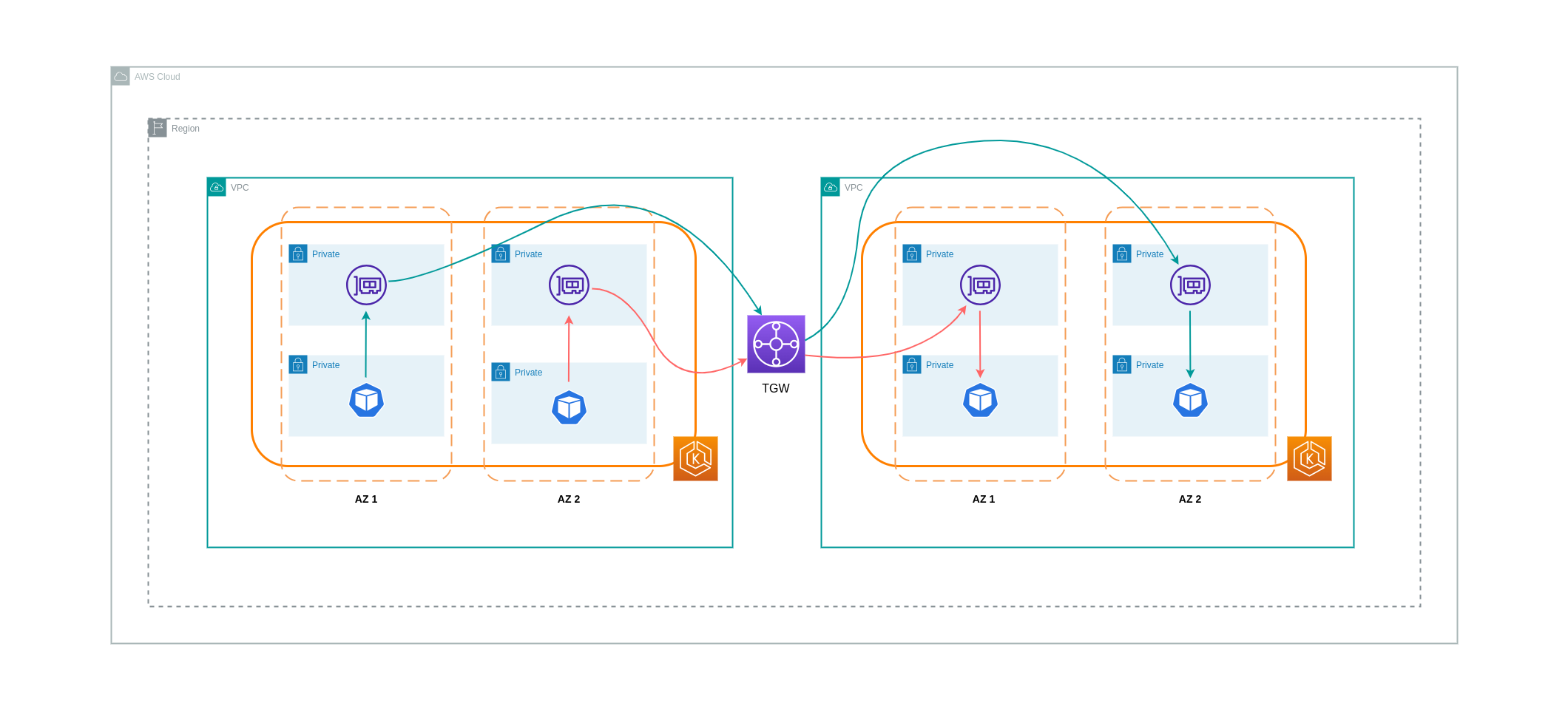
Como se señaló en la sección anterior, las conexiones de interconexión de VPC no permiten la conectividad de red transitiva. Si desea conectar 3 o más VPCs con requisitos de red transitiva, debe utilizar una Transit Gateway (TGW). Esto le permitirá superar los límites del emparejamiento de VPC o cualquier sobrecarga operativa asociada a tener varias conexiones de emparejamiento de VPC entre varias. VPCs Se le facturará por hora y por los datos que se envíen
El siguiente diagrama muestra el tráfico entre zonas de disponibilidad que fluye a través de un TGW entre cargas de trabajo de distintas regiones de AWS VPCs , pero dentro de la misma.
Uso de una malla de servicios
Las mallas de servicio ofrecen potentes capacidades de red que se pueden utilizar para reducir los costes relacionados con la red en los entornos de clústeres de EKS. Sin embargo, debe considerar detenidamente las tareas operativas y la complejidad que una malla de servicios introducirá en su entorno si la adopta.
Restringir el tráfico a las zonas de disponibilidad
Uso de la distribución ponderada por localidad de Istio
Istio le permite aplicar políticas de red al tráfico después de que se produzca el enrutamiento. Esto se hace mediante reglas de destino
nota
Antes de implementar la distribución ponderada por localidad, debe empezar por comprender los patrones de tráfico de su red y las implicaciones que la política de reglas de destino puede tener en el comportamiento de su aplicación. Por ello, es importante contar con mecanismos de rastreo distribuidos con herramientas como AWS X-Ray
Las reglas de destino de Istio detalladas anteriormente también se pueden aplicar para administrar el tráfico desde un balanceador de cargas a los pods de tu clúster de EKS. Las reglas de distribución ponderadas por localidad se pueden aplicar a un servicio que recibe tráfico de un balanceador de cargas de alta disponibilidad (específicamente, la puerta de enlace de entrada). Estas reglas te permiten controlar la cantidad de tráfico que va a cada lugar en función de su origen zonal (en este caso, el balanceador de carga). Si se configura correctamente, se generará menos tráfico de salida entre zonas en comparación con un balanceador de cargas que distribuya el tráfico de manera uniforme o aleatoria entre las réplicas de Pod de distintas zonas. AZs
A continuación, se muestra un ejemplo de bloque de código de un recurso de regla de destino en Istio. Como se puede ver a continuación, este recurso especifica las configuraciones ponderadas para el tráfico entrante de 3 países diferentes AZs de la eu-west-1 región. Estas configuraciones declaran que la mayoría del tráfico entrante (el 70% en este caso) de una zona de disponibilidad determinada debe enviarse mediante proxy a un destino de la misma zona de origen.
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
nota
El peso mínimo que se puede distribuir a un destino es del 1%. El motivo es mantener las regiones y zonas de conmutación por error en caso de que los puntos finales del destino principal dejen de funcionar o no estén disponibles.
El siguiente diagrama muestra un escenario en el que hay un balanceador de carga de alta disponibilidad en la región eu-west-1 y se aplica una distribución ponderada por localidad. La política de reglas de destino de este diagrama está configurada para enviar el 60% del tráfico procedente de eu-west-1a a los pods de la misma zona de disponibilidad, mientras que el 40% del tráfico de eu-west-1a debe dirigirse a los pods de eu-west-1b.
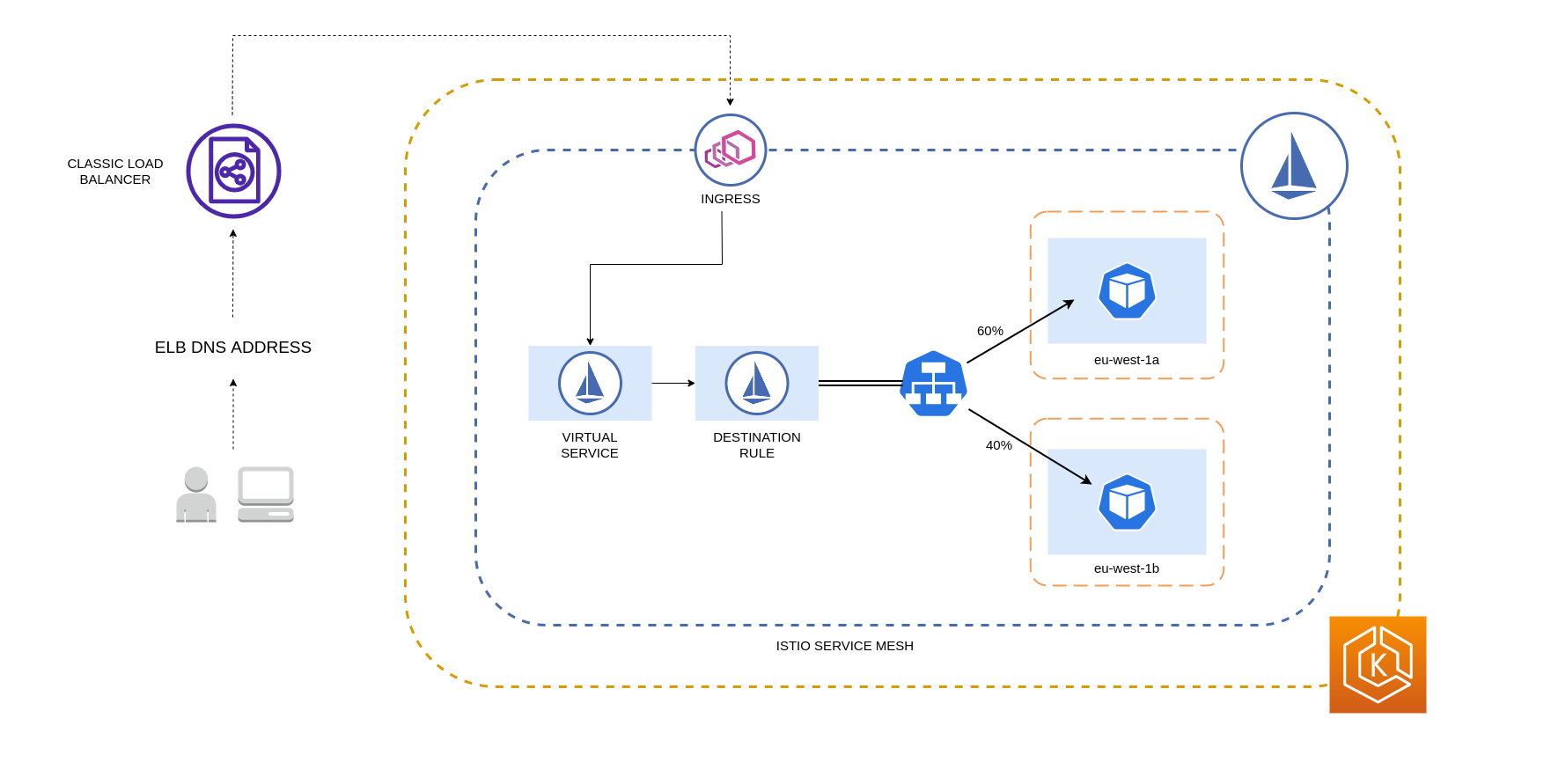
Restringir el tráfico a las zonas y nodos de disponibilidad
Uso de la política de tráfico interno del servicio con Istio
Para reducir los costes de red asociados al tráfico entrante externo y al tráfico interno entre los pods, puedes combinar las reglas de destino de Istio y la política de tráfico interna del Servicio Kubernetes. La forma de combinar las reglas de destino de Istio con la política de tráfico interna del servicio dependerá en gran medida de tres factores:
-
El papel de los microservicios
-
Patrones de tráfico de red en los microservicios
-
Cómo deben implementarse los microservicios en la topología de clústeres de Kubernetes
El siguiente diagrama muestra cómo sería el flujo de red en el caso de una solicitud anidada y cómo las políticas antes mencionadas controlarían el tráfico.

-
El usuario final realiza una solicitud a la APLICACIÓN A, que a su vez realiza una solicitud anidada a la APLICACIÓN C. Esta solicitud se envía primero a un balanceador de cargas de alta disponibilidad, que tiene instancias en la AZ 1 y la AZ 2, como se muestra en el diagrama anterior.
-
A continuación, el servicio virtual de Istio enruta la solicitud entrante externa al destino correcto.
-
Una vez enrutada la solicitud, la regla de destino de Istio controla la cantidad de tráfico que se dirige al respectivo país en AZs función del lugar de origen (AZ 1 o AZ 2).
-
A continuación, el tráfico se dirige al servicio de la APLICACIÓN A y, a continuación, se envía mediante proxy a los puntos finales del pod correspondientes. Como se muestra en el diagrama, el 80% del tráfico entrante se envía a los puntos finales del pod en la AZ 1 y el 20% del tráfico entrante se envía a la AZ 2.
-
A continuación, la APLICACIÓN A hace una solicitud interna a la APLICACIÓN C. El servicio de APP C tiene habilitada una política de tráfico interna (
internalTrafficPolicy`: Local`). -
La solicitud interna de la APLICACIÓN A (en el NODO 1) a la APLICACIÓN C se ha realizado correctamente debido al punto final local del nodo disponible para la APLICACIÓN C.
-
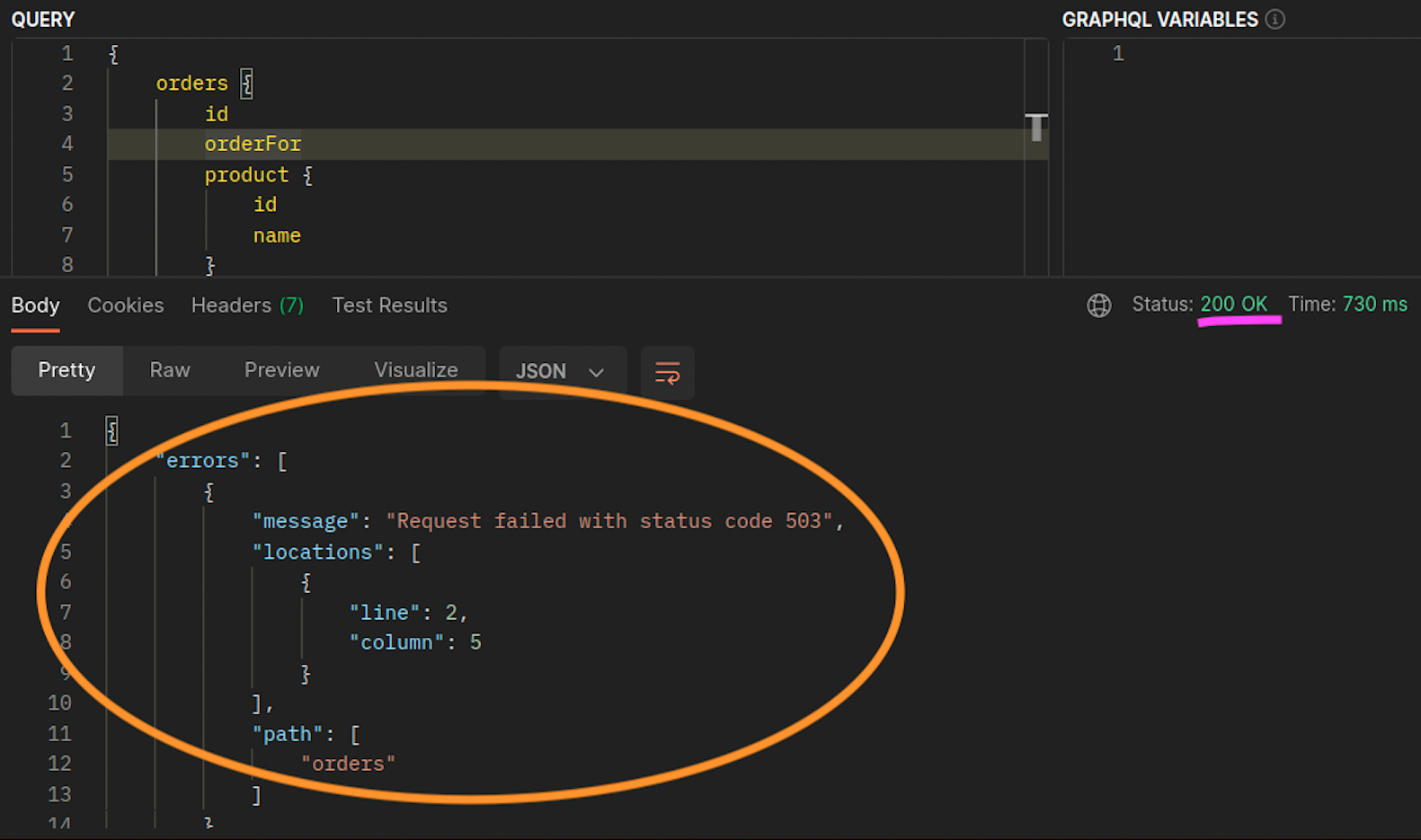
La solicitud interna de la APLICACIÓN A (en el NODO 3) a la APLICACIÓN C falla porque no hay puntos de enlace locales de nodo disponibles para la APLICACIÓN C. Como se muestra en el diagrama, la APLICACIÓN C no tiene réplicas en el NODO 3. *
Las siguientes capturas de pantalla están capturadas a partir de un ejemplo en vivo de este enfoque. El primer conjunto de capturas de pantalla muestra una solicitud externa correcta a una graphql y una solicitud anidada correcta desde una orders réplica ubicada en el graphql mismo nodo. ip-10-0-0-151.af-south-1.compute.internal
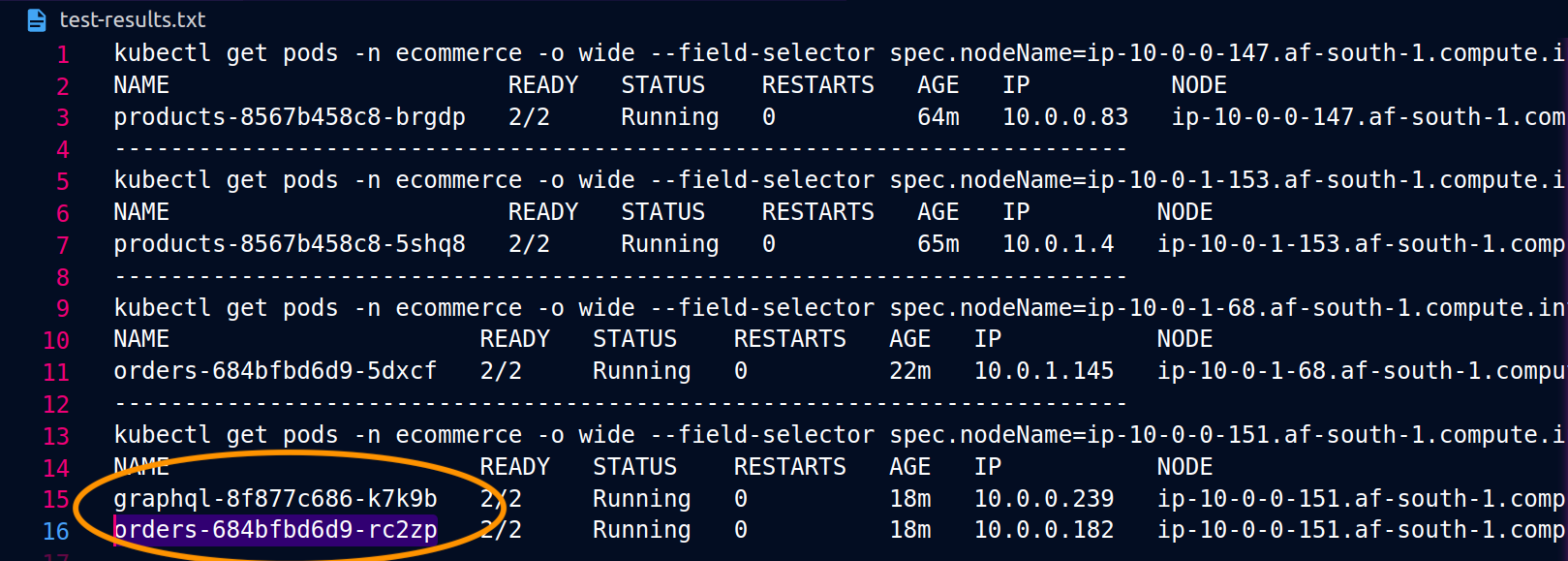
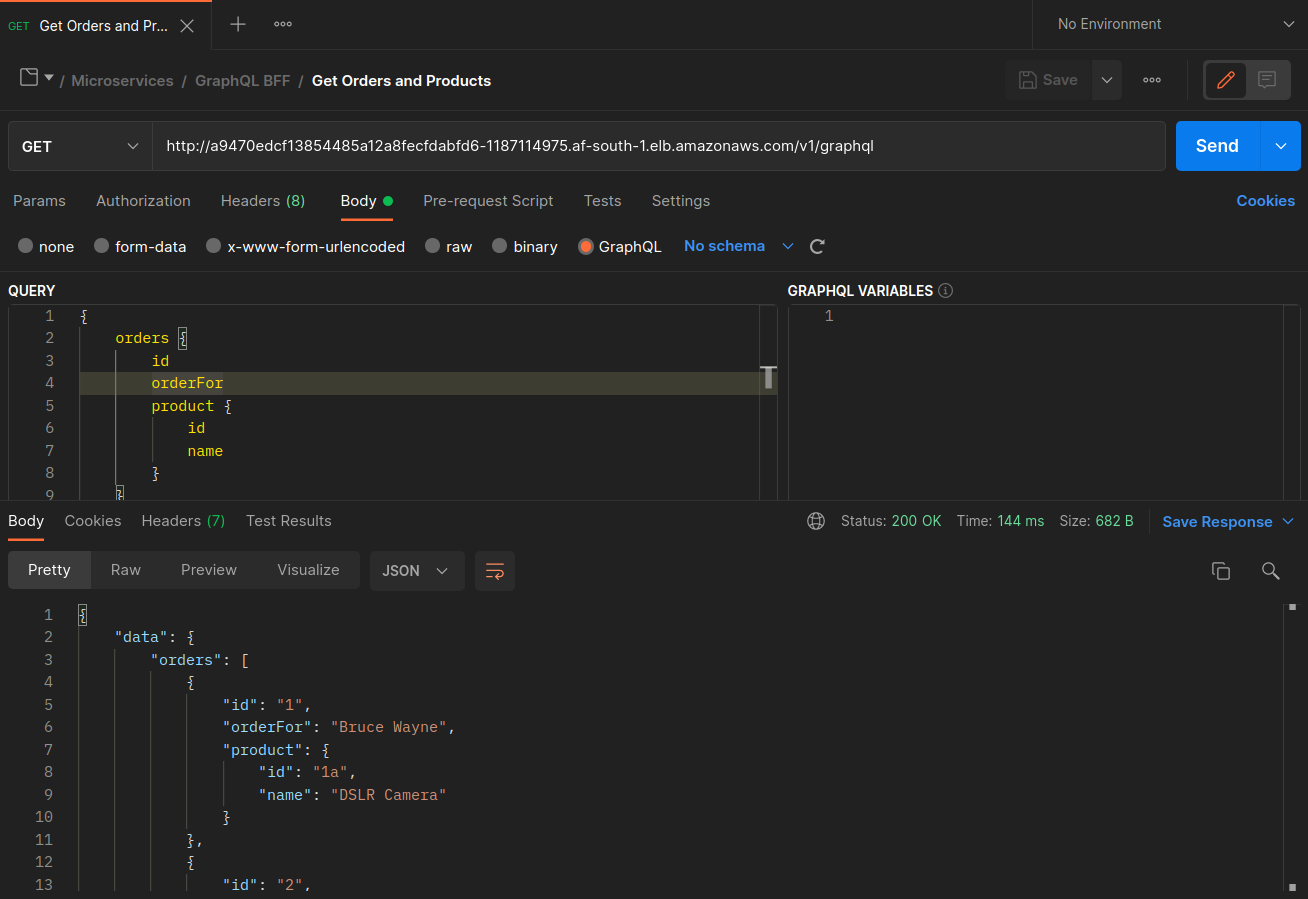
Con Istio, puede verificar y exportar las estadísticas de cualquier [clúster upstream] (https://www.envoyproxy). io/docs/envoy/latest/intro/arch_overview/intro/terminologyorders puntos finales que conoce el graphql proxy se pueden obtener mediante el siguiente comando:
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
En este caso, el graphql proxy solo conoce el orders punto final de la réplica con el que comparte un nodo. Si eliminas la internalTrafficPolicy: Local configuración del servicio de pedidos y vuelves a ejecutar un comando como el anterior, los resultados devolverán todos los puntos finales de las réplicas repartidos por los distintos nodos. Además, al examinar los rq_total puntos finales respectivos, observará una participación relativamente uniforme en la distribución de la red. En consecuencia, si los puntos finales están asociados a servicios ascendentes que se ejecutan en diferentes zonas AZs, esta distribución de la red entre zonas generará costes más altos.
Como se mencionó anteriormente en la sección anterior, puedes ubicar en un mismo lugar los pods que se comunican con frecuencia si utilizas la afinidad con los pods.
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
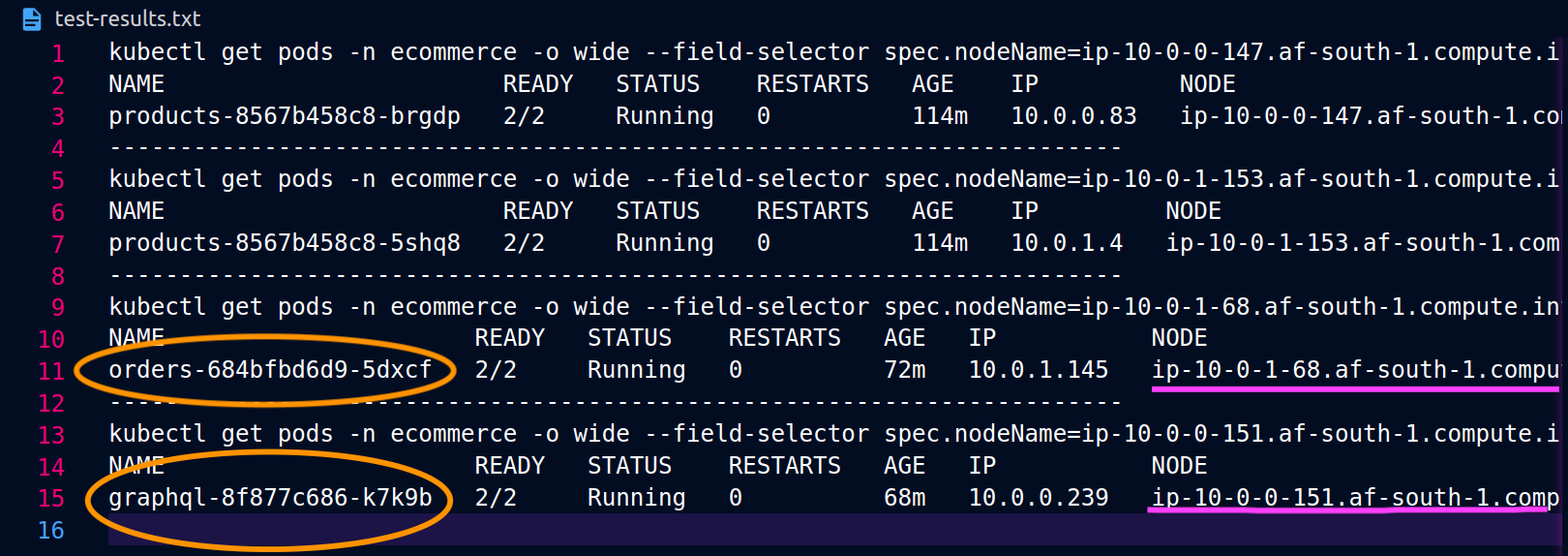
Cuando las orders réplicas graphql y las réplicas no coexisten en el mismo nodo (ip-10-0-0-151.af-south-1.compute.internal), la primera solicitud a graphql se realiza correctamente, como se muestra 200 response code en la siguiente captura de pantalla de Postman, mientras que la segunda solicitud anidada de to falla con a. graphql orders 503 response code
Recursos adicionales
-
Abordar los costos de latencia y transferencia de datos en EKS con Istio
-
Obtener visibilidad de los bytes de red de pod a pod de Amazon EKS Cross-AZ
-
Optimice el tráfico AZ con un enrutamiento compatible con la topología
-
Optimice el costo y el rendimiento de Kubernetes con la política de tráfico interno del servicio
-
Descripción de los costos de transferencia de datos de los servicios de contenedores de AWS
