Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Estrategia de cuentas múltiples
AWS recomienda utilizar una estrategia de cuentas múltiples y organizaciones de AWS para ayudar a aislar y administrar las aplicaciones y los datos empresariales. El uso de una estrategia de cuentas múltiples tiene muchas ventajas:
-
Aumento de las cuotas de servicios de API de AWS. Las cuotas se aplican a las cuentas de AWS y el uso de varias cuentas para sus cargas de trabajo aumenta la cuota total disponible para sus cargas de trabajo.
-
Políticas de Identity and Access Management (IAM) más sencillas. Conceder a las cargas de trabajo y a los operadores que las respaldan el acceso únicamente a sus propias cuentas de AWS significa menos tiempo para elaborar políticas de IAM detalladas para lograr el principio de privilegios mínimos.
-
Aislamiento mejorado de los recursos de AWS. Por diseño, todos los recursos aprovisionados en una cuenta están aislados de forma lógica de los recursos aprovisionados en otras cuentas. Este límite de aislamiento le permite limitar los riesgos de que se produzcan problemas relacionados con la aplicación, una configuración incorrecta o acciones malintencionadas. Si hay un problema en una cuenta, los impactos en las cargas de trabajo de otras cuentas se pueden reducir o eliminar.
-
Más ventajas, tal y como se describe en el documento técnico sobre la estrategia de cuentas múltiples de AWS
En las siguientes secciones se explica cómo implementar una estrategia de cuentas múltiples para sus cargas de trabajo de EKS mediante un enfoque de clúster de EKS centralizado o descentralizado.
Planeación de una estrategia de cuentas con múltiples cargas de trabajo para clústeres con varios inquilinos
En una estrategia de AWS con varias cuentas, los recursos que pertenecen a una carga de trabajo determinada, como los buckets de S3, ElastiCache los clústeres y las tablas de DynamoDB, se crean todos en una cuenta de AWS que contiene todos los recursos de esa carga de trabajo. Se denominan cuentas de carga de trabajo y el clúster EKS se implementa en una cuenta denominada cuenta de clúster. Las cuentas de clúster se analizarán en la siguiente sección. La implementación de recursos en una cuenta de carga de trabajo dedicada es similar a la implementación de recursos de Kubernetes en un espacio de nombres dedicado.
Luego, las cuentas de carga de trabajo se pueden desglosar aún más por ciclo de vida de desarrollo de software u otros requisitos, si corresponde. Por ejemplo, una carga de trabajo determinada puede tener una cuenta de producción, una cuenta de desarrollo o cuentas para alojar instancias de esa carga de trabajo en una región específica. Encontrará más información en este documento técnico de AWS.
Puede adoptar los siguientes enfoques al implementar la estrategia de cuentas múltiples de EKS:
Clúster EKS centralizado
En este enfoque, su clúster de EKS se implementará en una única cuenta de AWS llamadaCluster Account. Al utilizar las funciones de IAM para las cuentas de servicio (IRSA) o las identidades de los pods de EKS para ofrecer credenciales de AWS temporales y AWS Resource Access Manager (RAM)
En una estrategia de cuentas con varias cargas de trabajo para un clúster con varios inquilinos, las cuentas de AWS suelen alinearse con los espacios de nombres de Kubernetes
Es posible tener varios Cluster Accounts en su organización de AWS, y se recomienda tener varios Cluster Accounts que se ajusten a las necesidades del ciclo de vida del desarrollo de software. En el caso de las cargas de trabajo que funcionan a gran escala, es posible que necesite varias Cluster Accounts para garantizar que haya suficientes cuotas de servicios de Kubernetes y AWS disponibles para todas sus cargas de trabajo.
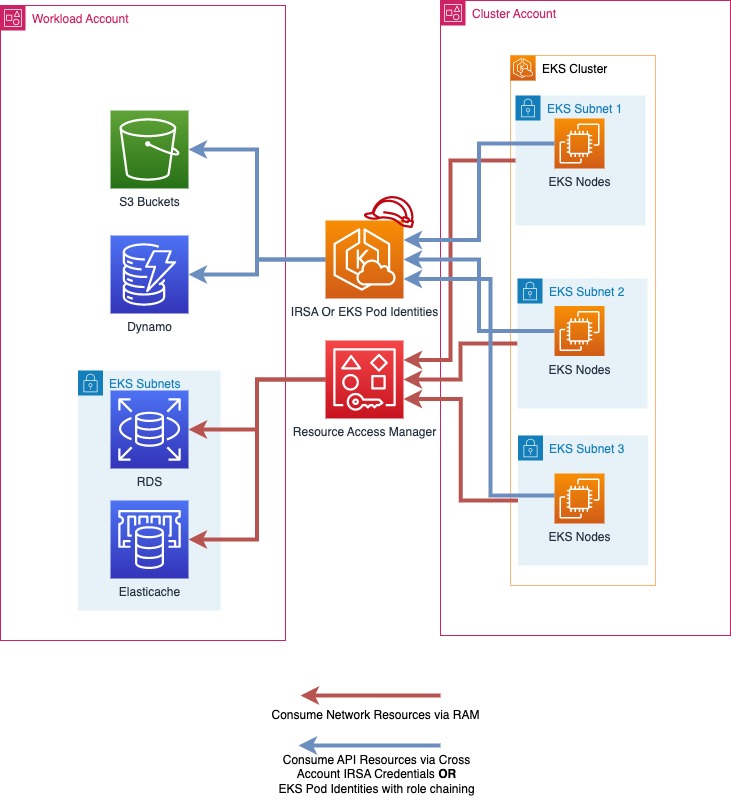
|En el diagrama anterior, la RAM de AWS se utiliza para compartir subredes de una cuenta de clúster en una cuenta de carga de trabajo. Luego, las cargas de trabajo que se ejecutan en los pods de EKS utilizan las identidades de los pods de IRSA o EKS y el encadenamiento de roles para asumir un rol en su cuenta de carga de trabajo y acceder a sus recursos de AWS.
Implementación de una estrategia de cuentas de múltiples cargas de trabajo para un clúster con varios inquilinos
Uso compartido de subredes con AWS Resource Access Manager
AWS Resource Access Manager
Si la RAM está habilitada para su organización de AWS, puede compartir las subredes de VPC de la cuenta del clúster con sus cuentas de carga de trabajo. Esto permitirá que los recursos de AWS que pertenecen a sus cuentas de carga de trabajo, como Amazon ElastiCache
Para compartir un recurso a través de la RAM, abra la RAM en la consola de AWS de la cuenta del clúster y seleccione «Recursos compartidos» y «Crear recurso compartido». Asigne un nombre a su recurso compartido y seleccione las subredes que desee compartir. Vuelva a seleccionar Siguiente e introduzca la cuenta de 12 dígitos IDs para las cuentas de carga de trabajo con las que desee compartir las subredes, vuelva a seleccionar Siguiente y, para finalizar, haga clic en Crear recurso compartido. Tras este paso, la cuenta de carga de trabajo puede implementar recursos en esas subredes.
Los recursos compartidos de RAM también se pueden crear mediante programación o con la infraestructura como código.
Elegir entre EKS Pod Identities e IRSA
En re:Invent 2023, AWS lanzó EKS Pod Identities como una forma más sencilla de entregar credenciales de AWS temporales a sus pods en EKS. Tanto las identidades de los pods de IRSA como las de EKS son métodos válidos para entregar credenciales de AWS temporales a los pods de EKS y seguirán siendo compatibles. Debe considerar qué método de entrega se adapta mejor a sus necesidades.
Al trabajar con un clúster de EKS y varias cuentas de AWS, IRSA puede asumir funciones directamente en las cuentas de AWS distintas de la cuenta en la que está alojado directamente el clúster de EKS, mientras que las identidades de los pods de EKS requieren que configure el encadenamiento de roles. Consulte la documentación de EKS para obtener una comparación detallada.
Acceso a los recursos de API de AWS con funciones de IAM para cuentas de servicio
Las funciones de IAM para cuentas de servicio (IRSA) le permiten entregar credenciales de AWS temporales a sus cargas de trabajo que se ejecutan en EKS. El IRSA se puede utilizar para obtener credenciales temporales para las funciones de IAM en las cuentas de carga de trabajo desde la cuenta del clúster. Esto permite que las cargas de trabajo que se ejecutan en los clústeres de EKS de la cuenta del clúster consuman sin problemas los recursos de la API de AWS, como los buckets de S3 alojados en la cuenta de carga de trabajo, y utilicen la autenticación de IAM para recursos como Amazon RDS Databases o Amazon EFS. FileSystems
Solo se puede acceder a los recursos de la API de AWS y a otros recursos que utilizan la autenticación de IAM en una cuenta de carga de trabajo mediante las credenciales de las funciones de IAM en esa misma cuenta de carga de trabajo, excepto cuando el acceso entre cuentas es posible y se ha habilitado de forma explícita.
Habilitar IRSA para el acceso entre cuentas
Para permitir que el IRSA para las cargas de trabajo de su cuenta de clúster acceda a los recursos de sus cuentas de carga de trabajo, primero debe crear un proveedor de identidades OIDC de IAM en su cuenta de carga de trabajo. Esto se puede hacer con el mismo procedimiento que para configurar el IRSA, con la salvedad de que el proveedor de identidad se creará en la cuenta de carga de trabajo.
A continuación, al configurar IRSA para sus cargas de trabajo en EKS, puede seguir los mismos pasos que en la documentación, pero utilizar el identificador de cuenta de 12 dígitos de la cuenta de carga de trabajo, tal y como se indica en la sección «Ejemplo de creación de un proveedor de identidades a partir del clúster de otra cuenta».
Una vez configurado, la aplicación que se ejecute en EKS podrá usar directamente su cuenta de servicio para asumir una función en la cuenta de carga de trabajo y utilizar los recursos que contiene.
Acceso a los recursos de la API de AWS con las identidades de los pods de EKS
EKS Pod Identities es una nueva forma de entregar credenciales de AWS a las cargas de trabajo que se ejecutan en EKS. Las identidades de los pods de EKS simplifican la configuración de los recursos de AWS, ya que ya no es necesario gestionar las configuraciones de OIDC para entregar las credenciales de AWS a los pods de EKS.
Habilitar las identidades de los pods de EKS para el acceso entre cuentas
A diferencia de IRSA, las identidades de los pods de EKS solo se pueden usar para conceder acceso directo a un rol en la misma cuenta que el clúster de EKS. Para acceder a un rol en otra cuenta de AWS, los pods que usan identidades de pods de EKS deben realizar el encadenamiento de roles.
El encadenamiento de roles se puede configurar en el perfil de una aplicación con su archivo de configuración de AWS mediante el proveedor de credenciales de proceso disponible en varios AWS SDKs. credential_processse puede utilizar como fuente de credenciales al configurar un perfil, por ejemplo:
# Content of the AWS Config file [profile account_b_role] source_profile = account_a_role role_arn = arn:aws:iam::444455556666:role/account-b-role [profile account_a_role] credential_process = /eks-credential-processrole.sh
La fuente del script llamado por credential_process:
#!/bin/bash # Content of the eks-credential-processrole.sh # This will retreive the credential from the pod identities agent, # and return it to the AWS SDK when referenced in a profile curl -H "Authorization: $(cat $AWS_CONTAINER_AUTHORIZATION_TOKEN_FILE)" $AWS_CONTAINER_CREDENTIALS_FULL_URI | jq -c '{AccessKeyId: .AccessKeyId, SecretAccessKey: .SecretAccessKey, SessionToken: .Token, Expiration: .Expiration, Version: 1}'
Puede crear un archivo de configuración de AWS, como se muestra arriba, con las funciones de cuenta A y B y especificar las variables AWS_CONFIG_FILE y AWS_PROFILE env en las especificaciones de su pod. El webhook de identidad de EKS Pod no se anula si las variables de entorno ya existen en la especificación del pod.
# Snippet of the PodSpec containers: - name: container-name image: container-image:version env: - name: AWS_CONFIG_FILE value: path-to-customer-provided-aws-config-file - name: AWS_PROFILE value: account_b_role
Al configurar políticas de confianza de roles para encadenar roles con las identidades de los pods de EKS, puedes hacer referencia a los atributos específicos de EKS como etiquetas de sesión y usar el control de acceso basado en atributos (ABAC) para limitar el acceso a tus roles de IAM únicamente a sesiones de identidad específicas del pod de EKS, como la cuenta de servicio de Kubernetes a la que pertenece un pod.
Tenga en cuenta que algunos de estos atributos pueden no ser universalmente únicos, por ejemplo, dos clústeres de EKS pueden tener espacios de nombres idénticos y un clúster puede tener cuentas de servicio con nombres idénticos en todos los espacios de nombres. Por lo tanto, al conceder el acceso a través de EKS Pod Identities y ABAC, se recomienda tener siempre en cuenta el arn y el espacio de nombres del clúster al conceder el acceso a una cuenta de servicio.
Identidades de ABAC y EKS Pod para el acceso entre cuentas
Al utilizar EKS Pod Identities para asumir funciones (encadenamiento de funciones) en otras cuentas como parte de una estrategia de cuentas múltiples, tiene la opción de asignar una función de IAM única a cada cuenta de servicio que necesite acceder a otra cuenta, o utilizar una función de IAM común en varias cuentas de servicio y usar ABAC para controlar a qué cuentas puede acceder.
Para usar ABAC para controlar qué cuentas de servicio pueden asumir un rol en otra cuenta mediante el encadenamiento de roles, debe crear una declaración de política de confianza de roles que solo permita que una sesión de rol asuma un rol cuando estén presentes los valores esperados. La siguiente política de confianza de roles solo permitirá que un rol de la cuenta del clúster de EKS (ID de cuenta 111122223333) asuma un rol si todas las kubernetes-service-account kubernetes-namespace etiquetas eks-cluster-arn y etiquetas tienen el valor esperado.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:root" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "aws:PrincipalTag/kubernetes-service-account": "PayrollApplication", "aws:PrincipalTag/eks-cluster-arn": "arn:aws:eks:us-east-1:111122223333:cluster/ProductionCluster", "aws:PrincipalTag/kubernetes-namespace": "PayrollNamespace" } } } ] }
Al utilizar esta estrategia, se recomienda garantizar que el rol común de IAM solo tenga sts:AssumeRole permisos y ningún otro acceso de AWS.
Al utilizar ABAC, es importante controlar quién puede asignar funciones y usuarios de IAM únicamente a aquellos que tengan una necesidad estricta de hacerlo. Una persona con la capacidad de etiquetar un rol o un usuario de IAM podría establecer etiquetas roles/users idénticas a las que configuraría EKS Pod Identities y podría aumentar sus privilegios. Puede restringir quién tiene acceso para establecer etiquetas, etiquetas y etiquetas para el rol kubernetes- y eks- los usuarios de IAM mediante la política de IAM o la Política de control de servicios (SCP).
Clústeres EKS descentralizados
Con este enfoque, los clústeres de EKS se implementan en las cuentas de AWS de carga de trabajo respectivas y conviven con otros recursos de AWS, como depósitos de Amazon S3 VPCs, tablas de Amazon DynamoDB, etc. Cada cuenta de carga de trabajo es independiente, autosuficiente y está gestionada por el clúster Unit/Application teams. This model allows the creation of reusuable
blueprints for various cluster capabilities — AI/ML empresarial correspondiente, procesamiento por lotes, uso general, etc., y venden los clústeres en función de los requisitos del equipo de aplicación. Tanto los equipos de aplicaciones como los de plataformas operan desde sus GitOps
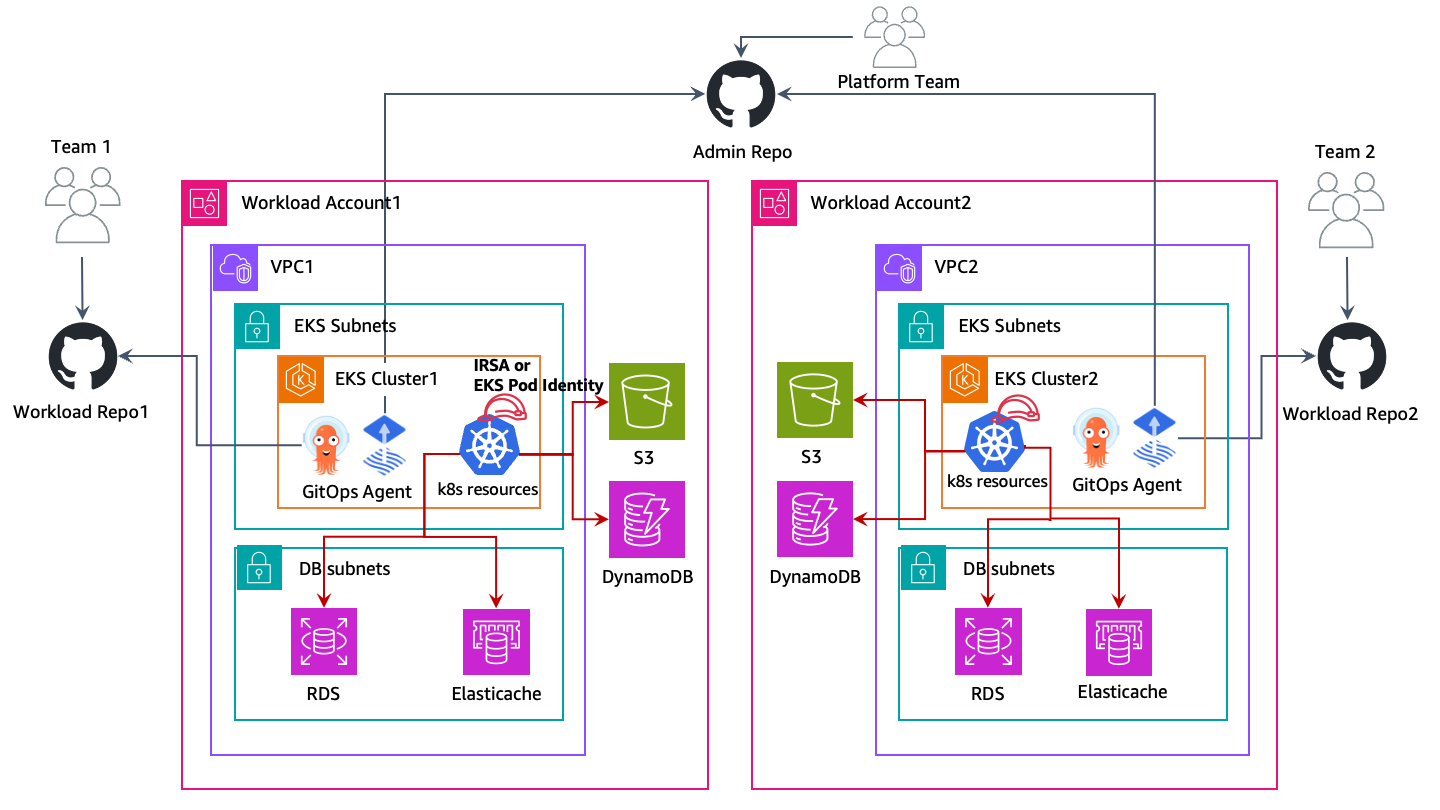
En el diagrama anterior, los clústeres de Amazon EKS y otros recursos de AWS se implementan en las cuentas de carga de trabajo respectivas. Luego, las cargas de trabajo que se ejecutan en los pods de EKS utilizan las identidades de los pods de IRSA o EKS para acceder a sus recursos de AWS.
GitOps es una forma de gestionar el despliegue de aplicaciones e infraestructuras de forma que todo el sistema se describa de forma declarativa en un repositorio de Git. Se trata de un modelo operativo que permite gestionar el estado de varios clústeres de Kubernetes mediante las mejores prácticas de control de versiones, artefactos inmutables y automatización. En este modelo de varios clústeres, cada clúster de carga de trabajo se inicia con varios repositorios de Git, lo que permite a cada equipo (aplicación, plataforma, seguridad, etc.) implementar sus cambios respectivos en el clúster.
Debería utilizar las funciones de IAM para las cuentas de servicio (IRSA) o las identidades de los pods de EKS en cada cuenta para permitir que sus cargas de trabajo de EKS obtengan credenciales de AWS temporales para acceder de forma segura a otros recursos de AWS. Las funciones de IAM se crean en las respectivas cuentas de AWS de carga de trabajo y se asignan a las cuentas de servicio de k8s para proporcionar acceso temporal a IAM. Por lo tanto, en este enfoque no se requiere el acceso entre cuentas. Siga la documentación sobre las funciones de IAM para las cuentas de servicio sobre cómo configurar cada carga de trabajo para IRSA y la documentación sobre las identidades de los pods de EKS sobre cómo configurar las identidades de los pods de EKS en cada cuenta.
Redes centralizadas
También puede utilizar la RAM de AWS para compartir las subredes de la VPC con las cuentas de carga de trabajo y lanzar clústeres de Amazon EKS y otros recursos de AWS en ellas. Esto permite una gestión/administración de la red centralizada, una conectividad de red simplificada y clústeres EKS descentralizados. Consulte este blog de AWS
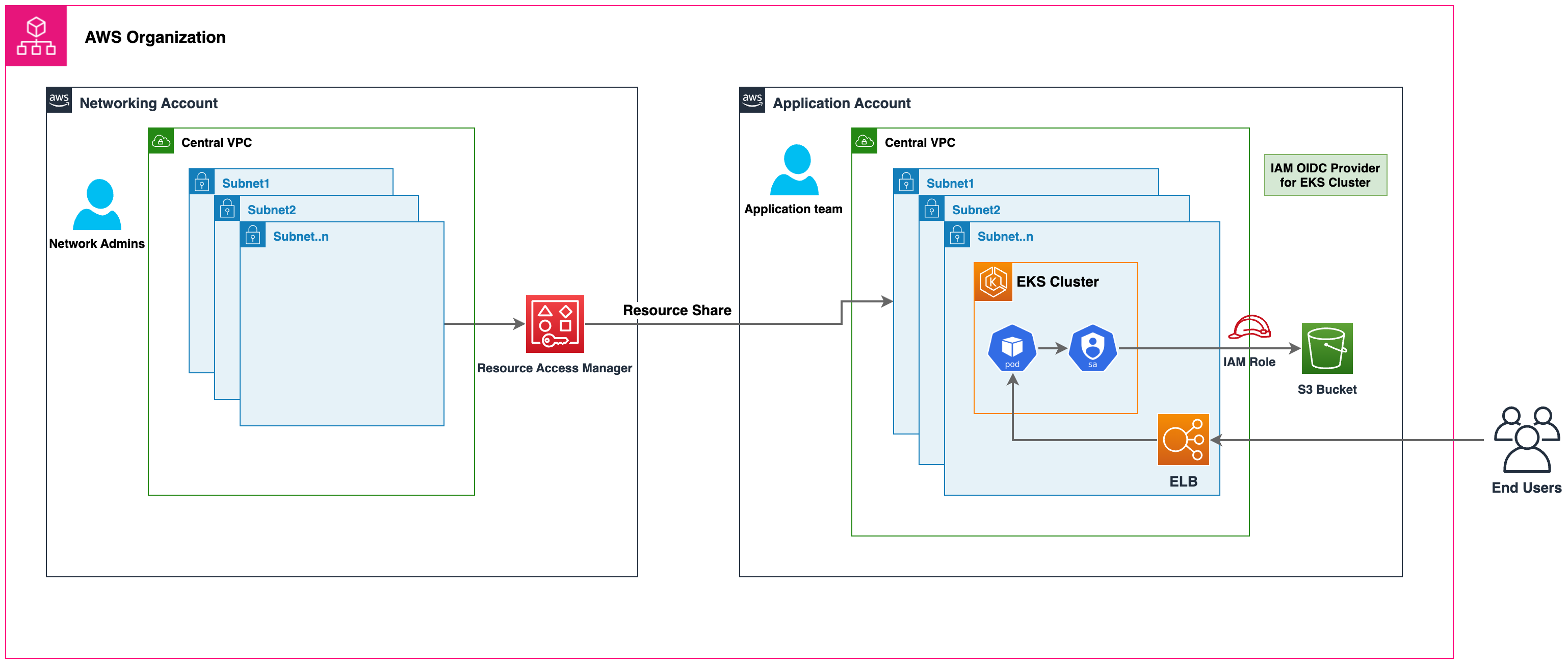
En el diagrama anterior, la RAM de AWS se utiliza para compartir subredes de una cuenta de red central en una cuenta de carga de trabajo. Luego, el clúster EKS y otros recursos de AWS se lanzan en esas subredes en las cuentas de carga de trabajo respectivas. Los pods de EKS utilizan las identidades de los pods de IRSA o EKS para acceder a sus recursos de AWS.
Clústeres de EKS centralizados o descentralizados
La decisión de utilizar un sistema centralizado o descentralizado dependerá de sus requisitos. En esta tabla se muestran las principales diferencias con cada estrategia.
| # | Clúster EKS centralizado | Clústeres EKS descentralizados |
|---|---|---|
|
Administración de clústeres: |
Administrar un único clúster de EKS es más fácil que administrar varios clústeres |
Es necesaria una automatización eficiente de la administración de clústeres para reducir la sobrecarga operativa que implica la administración de varios clústeres de EKS |
|
Rentabilidad: |
Permite la reutilización de los recursos de clúster y red de EKS, lo que promueve la rentabilidad |
Requiere configuraciones de redes y clústeres por carga de trabajo, lo que requiere recursos adicionales |
|
Resiliencia: |
Si un clúster se deteriora, es posible que varias cargas de trabajo del clúster centralizado se vean afectadas |
Si un clúster se deteriora, los daños se limitan únicamente a las cargas de trabajo que se ejecutan en ese clúster. El resto de las cargas de trabajo no se ven afectadas |
|
Aislamiento y seguridad: |
El aislamiento y la multitenencia suave se logran utilizando construcciones nativas de k8s, como. |
Mayor aislamiento de los recursos informáticos, ya que las cargas de trabajo se ejecutan en clústeres y nodos individuales que no comparten ningún recurso. Los recursos de AWS están aislados en sus propias cuentas de carga de trabajo a las que, de forma predeterminada, no se puede acceder desde otras cuentas de AWS. |
|
Rendimiento y escalabilidad: |
A medida que las cargas de trabajo crecen a escalas muy grandes, es posible que encuentre cuotas de servicio de Kubernetes y AWS en la cuenta del clúster. Puede implementar cuentas de clúster adicionales para escalar aún más |
A medida que VPCs hay más clústeres, cada carga de trabajo tiene más k8 disponibles y una cuota de servicio de AWS |
|
Networking: |
Se utiliza una sola VPC por clúster, lo que permite una conectividad más sencilla para las aplicaciones de ese clúster |
El enrutamiento debe establecerse entre el clúster EKS descentralizado VPCs |
|
Administración de acceso a Kubernetes: |
Es necesario mantener muchos roles y usuarios diferentes en el clúster para proporcionar acceso a todos los equipos de carga de trabajo y garantizar que los recursos de Kubernetes estén debidamente segregados |
Gestión del acceso simplificada, ya que cada clúster está dedicado a una carga de trabajo o un equipo |
|
Administración de acceso a AWS: |
Los recursos de AWS se implementan en su propia cuenta, a la que solo se puede acceder de forma predeterminada con las funciones de IAM en la cuenta de carga de trabajo. Las funciones de IAM en las cuentas de carga de trabajo se asumen de forma cruzada con las identidades de IRSA o EKS Pod. |
Los recursos de AWS se implementan en su propia cuenta, a la que solo se puede acceder de forma predeterminada con las funciones de IAM en la cuenta de carga de trabajo. Las funciones de IAM en las cuentas de carga de trabajo se asignan directamente a los pods con identidades de pod IRSA o EKS |
