Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso del escalado automático con una política personalizada para grupos de instancias en Amazon EMR
El escalado automático con una política personalizada en las versiones 4.0 y superiores de Amazon EMR le permite escalar programáticamente los nodos principales y los nodos de tareas en función de una CloudWatch métrica y otros parámetros que especifique en una política de escalado. El escalado automático con una política personalizada está disponible con la configuración de grupos de instancias, pero no con las flotas de instancias. Para obtener más información sobre los grupos de instancias y las flotas de instancias, consulte Creación de un clúster de Amazon EMR con flotas de instancias o grupos de instancias uniformes.
nota
Para utilizar la característica de escalado automático con una política personalizada en Amazon EMR, debe establecer en true el parámetro VisibleToAllUsers al crear un clúster. Para obtener más información, consulte SetVisibleToAllUsers.
La política de escalado forma parte de la configuración de un grupo de instancias. Puede especificar una política durante la configuración de un grupo de instancias o modificando un grupo de instancias en un clúster existente, incluso cuando dicho grupo de instancias está activo. Cada grupo de instancia de un clúster, excepto el grupo de instancias principales, puede tener su propia política de escalado, que se compone de reglas de escalado horizontal y reducción horizontal. Las reglas de escalado ascendente y descendente se pueden configurar de manera independiente, con distintos parámetros para cada regla.
Puede configurar políticas de escalado con la AWS Management Console AWS CLI, la o la API de Amazon EMR. Cuando utiliza la API AWS CLI o Amazon EMR, especifica la política de escalado en formato JSON. Además, si utiliza la API Amazon EMR AWS CLI o la API, puede especificar métricas personalizadas CloudWatch . Las métricas personalizadas no se pueden seleccionar con la AWS Management Console. Al crear inicialmente una política de escalado con la consola, se preconfigura una política predeterminada adecuada para muchas aplicaciones para ayudarle a comenzar. Puede eliminar o modificar las reglas predeterminadas.
Si bien el escalado automático te permite ajustar la capacidad del clúster de EMR on-the-fly, debes tener en cuenta los requisitos de carga de trabajo básicos y planificar las configuraciones de los nodos y grupos de instancias. Para obtener más información, consulte Directrices de configuración del clúster.
nota
Para la mayoría de las cargas de trabajo, es deseable la configuración de las reglas de escalado ascendente y descendente para optimizar el uso de los recursos. Definir una regla sin la otra significa que tendrá que cambiar manualmente el tamaño del recuento de instancias después de una actividad de escalado. En otras palabras, esto configura una política de escalado ascendente o descendente automática "unidireccional" con un restablecimiento manual.
Creación del rol de IAM; para el escalado automático
El escalado automático en Amazon EMR requiere un rol de IAM con permisos para agregar y terminar instancias cuando se activan las actividades de escalado. Para este fin se dispone de un rol predeterminado, EMR_AutoScaling_DefaultRole, configurado con la política de confianza y la política de roles adecuadas. Cuando crea un clúster con una política de escalado por primera vez con AWS Management Console, Amazon EMR crea el rol predeterminado y adjunta la política administrada predeterminada para los permisos,. AmazonElasticMapReduceforAutoScalingRole
Al crear un clúster con una política de escalado automático con el AWS CLI, primero debe asegurarse de que existe el rol de IAM predeterminado o de que tiene un rol de IAM personalizado con una política adjunta que proporcione los permisos adecuados. Para crear el rol predeterminado, puede ejecutar el comando create-default-roles antes de crear un clúster. A continuación, puede especificar la opción --auto-scaling-role
EMR_AutoScaling_DefaultRole al crear el clúster. También puede crear un rol de escalado automático personalizado y luego especificarlo al crear un clúster, por ejemplo, --auto-scaling-role
. Si crea un rol de escalado automático personalizado para Amazon EMR, le recomendamos que base las políticas de permisos de dicho rol en la política administrada. Para obtener más información, consulte Configuración de los roles de servicio de IAM de los permisos de Amazon EMR para los servicios y recursos de AWS.MyEMRAutoScalingRole
Descripción de las reglas de escalado automático
Cuando una regla de escalado horizontal desencadena una actividad de escalado para un grupo de instancias, EC2 las instancias de Amazon se añaden al grupo de instancias de acuerdo con tus reglas. Aplicaciones como Apache Spark, Apache Hive y Presto pueden usar los nodos nuevos tan pronto como la EC2 instancia de Amazon entre en el InService estado. También puede configurar una regla de escalado descendente que termina instancias y elimina nodos. Para obtener más información sobre el ciclo de vida de las EC2 instancias de Amazon que se escalan automáticamente, consulte el ciclo de vida de Auto Scaling en la Guía del usuario de Amazon EC2 Auto Scaling.
Puede configurar la forma en que un clúster termina las EC2 instancias de Amazon. Puedes elegir entre finalizar la facturación en el límite de EC2 horas de instancia de Amazon o al finalizar la tarea. Esta configuración se aplica tanto al escalado automático como a las operaciones manuales de cambio de tamaño. Para obtener más información acerca de esta configuración, consulte Opciones de reducción vertical de clústeres para clústeres de Amazon EMR.
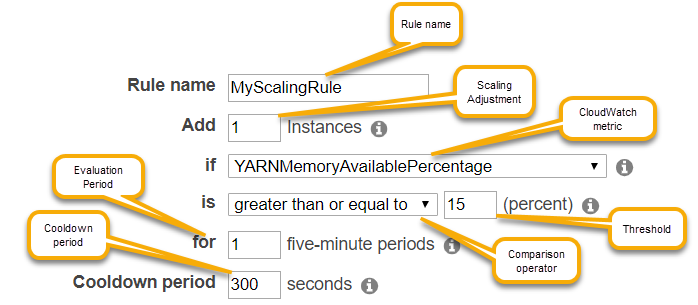
Los siguientes parámetros para cada regla de una política determinan el comportamiento de escalado automático.
nota
Los parámetros que se muestran aquí se basan en los AWS Management Console de Amazon EMR. Al utilizar la API AWS CLI o Amazon EMR, hay disponibles opciones de configuración avanzada adicionales. Para obtener más información sobre las opciones avanzadas, consulte SimpleScalingPolicyConfigurationla referencia de la API de Amazon EMR.
-
Número máximo de instancias y número mínimo de instancias. La restricción Máximo de instancias especifica el número máximo de EC2 instancias de Amazon que pueden estar en el grupo de instancias y se aplica a todas las reglas de escalado horizontal. Del mismo modo, la restricción de instancias mínimas especifica el número mínimo de EC2 instancias de Amazon y se aplica a todas las reglas de escalado interno.
-
El Rule name (Nombre de la regla), que debe ser único en la política.
-
El ajuste de escalado, que determina el número de EC2 instancias que se deben añadir (en el caso de las reglas de escalamiento horizontal) o finalizar (en el caso de las reglas de escalado interno) durante la actividad de escalado que desencadena la regla.
-
La CloudWatch métrica, que se vigila en busca de una condición de alarma.
-
Un operador de comparación, que se utiliza para comparar la CloudWatch métrica con el valor umbral y determinar una condición de activación.
-
Un período de evaluación, en incrementos de cinco minutos, durante el cual la CloudWatch métrica debe estar en una condición de activación antes de que se active la actividad de escalado.
-
Un Cooldown period (período de recuperación) en segundos, que determina la cantidad de tiempo que debe transcurrir entre una actividad de escalado iniciada por una regla y el inicio de la próxima actividad de escalado, con independencia de la regla que la activa. Cuando un grupo de instancias finaliza una actividad de escalado y alcanza su estado posterior a la escalabilidad, el período de enfriamiento brinda una oportunidad para que las CloudWatch métricas que podrían desencadenar actividades de escalado posteriores se estabilicen. Para obtener más información, consulte los tiempos de reutilización de Auto Scaling en la Guía del usuario de Amazon EC2 Auto Scaling.
Consideraciones y limitaciones
-
CloudWatch Las métricas de Amazon son fundamentales para que funcione el escalado automático de Amazon EMR. Te recomendamos que supervises de cerca CloudWatch las estadísticas de Amazon para asegurarte de que no falten datos. Para obtener más información sobre cómo configurar CloudWatch las alarmas de Amazon para detectar las métricas faltantes, consulta Uso de CloudWatch las alarmas de Amazon.
-
La sobreutilización de los volúmenes de EBS puede provocar problemas de Escalado administrado. Le recomendamos que supervise de cerca el uso de los volúmenes de EBS para asegurarse de que el volumen de EBS esté por debajo del 90 % de utilización. Consulte Almacenamiento de instancias para obtener información sobre cómo especificar volúmenes de EBS adicionales.
-
El escalado automático con una política personalizada en las versiones 5.18 a 5.28 de Amazon EMR puede experimentar un error de escalado debido a la ausencia intermitente de datos en las métricas de Amazon. CloudWatch Para mejorar el escalado automático, le recomendamos que utilice las versiones más recientes de Amazon EMR. También puede ponerse en contacto con AWS Support
para solicitar un parche si tiene que utilizar una versión de Amazon EMR que esté entre la 5.18 y la 5.28.
Utilizándolo para configurar el escalado automático AWS Management Console
Al crear un clúster, se configura una política de escalado para grupos de instancias con las opciones avanzadas de configuración de clúster. También puede crear o modificar una política de escalado para un grupo de instancias en servicio modificando los grupos de instancias en la configuración de Hardware de un clúster existente.
Vaya hasta la nueva consola de Amazon EMR y seleccione Ir a la consola antigua en el panel de navegación lateral. Para más información sobre lo que puede esperar al cambiar a la consola antigua, consulte Uso de la consola antigua.
-
Si está creando un clúster, en la consola de Amazon EMR, seleccione Crear clúster, seleccione Ir a las opciones avanzadas, seleccione las opciones en Paso 1: Software y pasos y, a continuación, acceda a Paso 2: Configuración de hardware.
- o bien -
Si está modificando un grupo de instancias en un clúster en ejecución, seleccione el clúster en la lista de clústeres y, a continuación, expanda la sección Hardware.
-
En la sección Opción de escalado y aprovisionamiento del clúster, seleccione Habilitar el escalado del clúster. A continuación, seleccione Crear una política de escalado automático personalizada.
En la tabla Políticas de escalado automático personalizadas, haga clic en el icono de lápiz que aparece en la fila del grupo de instancias que desea configurar. Se abre la pantalla de reglas de Auto Scaling.
-
Escriba el valor de Maximum instances (Número máximo de instancias) que desea que contenga el grupo de instancias después del escalado ascendente y el valor de Minimum instances (Número mínimo de instancias) que desea que contenga el grupo de instancias después del escalado descendente.
-
Haga clic en el icono de lápiz para editar los parámetros de regla, haga clic en la X para eliminar una regla de la política y, a continuación, haga clic en Add rule (Añadir regla) para añadir reglas adicionales.
-
Elija los parámetros de la configuración, tal como se describió anteriormente en este tema. Para obtener descripciones de las CloudWatch métricas disponibles para Amazon EMR, consulte las métricas y dimensiones de Amazon EMR en la Guía del usuario de Amazon. CloudWatch
Utilizándolo AWS CLI para configurar el escalado automático
Puede usar AWS CLI los comandos de Amazon EMR para configurar el escalado automático al crear un clúster y al crear un grupo de instancias. Puede utilizar una sintaxis abreviada, especificando la configuración JSON insertada dentro de los comandos pertinentes o puede hacer referencia a un archivo que contenga la configuración JSON. También puede aplicar una política de escalado automático a un grupo de instancias existente y eliminar la política de escalado automático que se aplicó anteriormente. Además, puede recuperar detalles de una configuración de política de escalado desde un clúster en ejecución.
importante
Al crear un clúster con una política de escalado automático, es necesario utilizar el comando --auto-scaling-role
para especificar el rol de IAM para el escalado automático. El rol predeterminado es MyAutoScalingRoleEMR_AutoScaling_DefaultRolecreate-default-roles. El rol solo se puede añadir cuando se crea el clúster y no se puede añadir a un clúster existente.
Para obtener una descripción detallada de los parámetros disponibles al configurar una política de escalado automático, consulte la referencia PutAutoScalingPolicyde la API de Amazon EMR.
Creación de un clúster con una política de escalado automático aplicada a un grupo de instancias
Puede especificar una configuración de escalado automático dentro de la opción --instance-groups del comando aws emr
create-cluster. El siguiente ejemplo ilustra un comando create-cluster donde se proporciona una política insertada de escalado automático para el grupo de instancias secundarias. El comando crea una configuración de escalado equivalente a la política de escalado horizontal predeterminada que aparece al crear una política de escalado automático con AWS Management Console Amazon EMR. Por razones de brevedad, no se muestra una política de escalado descendente. No recomendamos la creación de una regla de escalado ascendente sin una regla de escalado descendente.
aws emr create-cluster --release-labelemr-5.2.0--service-role EMR_DefaultRole --ec2-attributes InstanceProfile=EMR_EC2_DefaultRole --auto-scaling-role EMR_AutoScaling_DefaultRole --instance-groups Name=MyMasterIG,InstanceGroupType=MASTER,InstanceType=m5.xlarge,InstanceCount=1 'Name=MyCoreIG,InstanceGroupType=CORE,InstanceType=m5.xlarge,InstanceCount=2,AutoScalingPolicy={Constraints={MinCapacity=2,MaxCapacity=10},Rules=[{Name=Default-scale-out,Description=Replicates the default scale-out rule in the console.,Action={SimpleScalingPolicyConfiguration={AdjustmentType=CHANGE_IN_CAPACITY,ScalingAdjustment=1,CoolDown=300}},Trigger={CloudWatchAlarmDefinition={ComparisonOperator=LESS_THAN,EvaluationPeriods=1,MetricName=YARNMemoryAvailablePercentage,Namespace=AWS/ElasticMapReduce,Period=300,Statistic=AVERAGE,Threshold=15,Unit=PERCENT,Dimensions=[{Key=JobFlowId,Value="${emr.clusterId}"}]}}}]}'
El siguiente comando ilustra el uso de la línea de comandos para proporcionar la definición de política de escalado automático como parte de un archivo de configuración de grupo de instancias denominado instancegroupconfig.json
aws emr create-cluster --release-labelemr-5.2.0--service-role EMR_DefaultRole --ec2-attributes InstanceProfile=EMR_EC2_DefaultRole --instance-groups file://your/path/to/instancegroupconfig.json--auto-scaling-role EMR_AutoScaling_DefaultRole
Con el contenido del archivo de configuración siguiente:
[ { "InstanceCount": 1, "Name": "MyMasterIG", "InstanceGroupType": "MASTER", "InstanceType": "m5.xlarge" }, { "InstanceCount": 2, "Name": "MyCoreIG", "InstanceGroupType": "CORE", "InstanceType": "m5.xlarge", "AutoScalingPolicy": { "Constraints": { "MinCapacity": 2, "MaxCapacity": 10 }, "Rules": [ { "Name": "Default-scale-out", "Description": "Replicates the default scale-out rule in the console for YARN memory.", "Action":{ "SimpleScalingPolicyConfiguration":{ "AdjustmentType": "CHANGE_IN_CAPACITY", "ScalingAdjustment": 1, "CoolDown": 300 } }, "Trigger":{ "CloudWatchAlarmDefinition":{ "ComparisonOperator": "LESS_THAN", "EvaluationPeriods": 1, "MetricName": "YARNMemoryAvailablePercentage", "Namespace": "AWS/ElasticMapReduce", "Period": 300, "Threshold": 15, "Statistic": "AVERAGE", "Unit": "PERCENT", "Dimensions":[ { "Key" : "JobFlowId", "Value" : "${emr.clusterId}" } ] } } } ] } } ]
Agregar un grupo de instancias con una política de escalado automático a un clúster
Puede especificar una configuración de política de escalado con la opción --instance-groups con el comando add-instance-groups de la misma forma que al utilizar create-cluster. En el siguiente ejemplo se utiliza una referencia a un archivo JSON, instancegroupconfig.json
aws emr add-instance-groups --cluster-idj-1EKZ3TYEVF1S2--instance-groups file://your/path/to/instancegroupconfig.json
Aplicar una política de escalado automático a un grupo de instancias existente o modificar una política aplicada
Utilice el comando aws emr put-auto-scaling-policy para aplicar una política de escalado automático a un grupo de instancias existente. El grupo de instancias debe formar parte de un clúster que utilice el rol de IAM; de escalado automático. En el siguiente ejemplo se utiliza una referencia a un archivo JSON, autoscaleconfig.json
aws emr put-auto-scaling-policy --cluster-idj-1EKZ3TYEVF1S2--instance-group-idig-3PLUZBA6WLS07--auto-scaling-policyfile://your/path/to/autoscaleconfig.json
El contenido del archivo autoscaleconfig.json, que define la misma regla de escalado ascendente, tal y como se muestra en el ejemplo anterior, se muestra a continuación.
{ "Constraints": { "MaxCapacity": 10, "MinCapacity": 2 }, "Rules": [{ "Action": { "SimpleScalingPolicyConfiguration": { "AdjustmentType": "CHANGE_IN_CAPACITY", "CoolDown": 300, "ScalingAdjustment": 1 } }, "Description": "Replicates the default scale-out rule in the console for YARN memory", "Name": "Default-scale-out", "Trigger": { "CloudWatchAlarmDefinition": { "ComparisonOperator": "LESS_THAN", "Dimensions": [{ "Key": "JobFlowId", "Value": "${emr.clusterID}" }], "EvaluationPeriods": 1, "MetricName": "YARNMemoryAvailablePercentage", "Namespace": "AWS/ElasticMapReduce", "Period": 300, "Statistic": "AVERAGE", "Threshold": 15, "Unit": "PERCENT" } } }] }
Eliminación de una política de escalado automático desde un grupo de instancias
aws emr remove-auto-scaling-policy --cluster-idj-1EKZ3TYEVF1S2--instance-group-idig-3PLUZBA6WLS07
Recuperación de una configuración de política de escalado automático
El describe-cluster comando recupera la configuración de políticas del bloque. InstanceGroup Por ejemplo, el comando siguiente recupera la configuración para el clúster con un ID de clúster de j-1CWOHP4PI30VJ.
aws emr describe-cluster --cluster-id j-1CWOHP4PI30VJ
El comando produce el siguiente resultado de ejemplo.
{ "Cluster": { "Configurations": [], "Id": "j-1CWOHP4PI30VJ", "NormalizedInstanceHours": 48, "Name": "Auto Scaling Cluster", "ReleaseLabel": "emr-5.2.0", "ServiceRole": "EMR_DefaultRole", "AutoTerminate": false, "TerminationProtected": true, "MasterPublicDnsName": "ec2-54-167-31-38.compute-1.amazonaws.com", "LogUri": "s3n://aws-logs-232939870606-us-east-1/elasticmapreduce/", "Ec2InstanceAttributes": { "Ec2KeyName": "performance", "AdditionalMasterSecurityGroups": [], "AdditionalSlaveSecurityGroups": [], "EmrManagedSlaveSecurityGroup": "sg-09fc9362", "Ec2AvailabilityZone": "us-east-1d", "EmrManagedMasterSecurityGroup": "sg-0bfc9360", "IamInstanceProfile": "EMR_EC2_DefaultRole" }, "Applications": [ { "Name": "Hadoop", "Version": "2.7.3" } ], "InstanceGroups": [ { "AutoScalingPolicy": { "Status": { "State": "ATTACHED", "StateChangeReason": { "Message": "" } }, "Constraints": { "MaxCapacity": 10, "MinCapacity": 2 }, "Rules": [ { "Name": "Default-scale-out", "Trigger": { "CloudWatchAlarmDefinition": { "MetricName": "YARNMemoryAvailablePercentage", "Unit": "PERCENT", "Namespace": "AWS/ElasticMapReduce", "Threshold": 15, "Dimensions": [ { "Key": "JobFlowId", "Value": "j-1CWOHP4PI30VJ" } ], "EvaluationPeriods": 1, "Period": 300, "ComparisonOperator": "LESS_THAN", "Statistic": "AVERAGE" } }, "Description": "", "Action": { "SimpleScalingPolicyConfiguration": { "CoolDown": 300, "AdjustmentType": "CHANGE_IN_CAPACITY", "ScalingAdjustment": 1 } } }, { "Name": "Default-scale-in", "Trigger": { "CloudWatchAlarmDefinition": { "MetricName": "YARNMemoryAvailablePercentage", "Unit": "PERCENT", "Namespace": "AWS/ElasticMapReduce", "Threshold": 75, "Dimensions": [ { "Key": "JobFlowId", "Value": "j-1CWOHP4PI30VJ" } ], "EvaluationPeriods": 1, "Period": 300, "ComparisonOperator": "GREATER_THAN", "Statistic": "AVERAGE" } }, "Description": "", "Action": { "SimpleScalingPolicyConfiguration": { "CoolDown": 300, "AdjustmentType": "CHANGE_IN_CAPACITY", "ScalingAdjustment": -1 } } } ] }, "Configurations": [], "InstanceType": "m5.xlarge", "Market": "ON_DEMAND", "Name": "Core - 2", "ShrinkPolicy": {}, "Status": { "Timeline": { "CreationDateTime": 1479413437.342, "ReadyDateTime": 1479413864.615 }, "State": "RUNNING", "StateChangeReason": { "Message": "" } }, "RunningInstanceCount": 2, "Id": "ig-3M16XBE8C3PH1", "InstanceGroupType": "CORE", "RequestedInstanceCount": 2, "EbsBlockDevices": [] }, { "Configurations": [], "Id": "ig-OP62I28NSE8M", "InstanceGroupType": "MASTER", "InstanceType": "m5.xlarge", "Market": "ON_DEMAND", "Name": "Master - 1", "ShrinkPolicy": {}, "EbsBlockDevices": [], "RequestedInstanceCount": 1, "Status": { "Timeline": { "CreationDateTime": 1479413437.342, "ReadyDateTime": 1479413752.088 }, "State": "RUNNING", "StateChangeReason": { "Message": "" } }, "RunningInstanceCount": 1 } ], "AutoScalingRole": "EMR_AutoScaling_DefaultRole", "Tags": [], "BootstrapActions": [], "Status": { "Timeline": { "CreationDateTime": 1479413437.339, "ReadyDateTime": 1479413863.666 }, "State": "WAITING", "StateChangeReason": { "Message": "Cluster ready after last step completed." } } } }
