Agregar una conexión JDBC con sus propios controladores JDBC
Puede utilizar su propio controlador JDBC cuando utilice una conexión JDBC. Si el controlador predeterminado utilizado por el rastreador AWS Glue no puede conectarse a una base de datos, puede utilizar su propio controlador JDBC. Por ejemplo, si desea utilizar el SHA-256 con su base de datos de Postgres y los controladores Postgres más antiguos no lo admiten, puede utilizar su propio controlador JDBC.
Orígenes de datos compatibles
| Orígenes de datos compatibles | Orígenes de datos no compatibles |
|---|---|
| MySQL | Snowflake |
| Postgres | |
| Oracle | |
| Redshift | |
| SQL Server | |
| Aurora* |
*Se admite si se utiliza el controlador JDBC nativo. No se pueden aprovechar todas las funciones del controlador.
Agregar un controlador JDBC a una conexión JDBC
nota
Si decide incorporar sus versiones de controladores JDBC, los rastreadores AWS Glue consumirán recursos en trabajos AWS Glue y en los buckets de Amazon S3 para garantizar que los controladores proporcionados se ejecuten en su entorno. El uso adicional de los recursos se reflejará en su cuenta. El costo de los rastreadores AWS Glue y los trabajos se incluye en la categoría AWS Glue de facturación. Además, proporcionar su propio controlador JDBC no significa que el rastreador pueda aprovechar todas las funciones del controlador.
Agregar su propio controlador JDBC a una conexión JDBC:
-
Agregue el archivo del controlador JDBC a una ubicación de Amazon S3. Puede crear un bucket o una carpeta o utilizar un bucket o una carpeta existente.
-
En la consola AWS Glue, seleccione Conexiones en el menú de la izquierda, en el catálogo de datos y luego cree una conexión nueva.
-
Rellene los campos de las Propiedades de la conexión y elija JDBC para Tipo de conexión.
-
En Acceso a la conexión, ingrese la URL del JDBC y el nombre de la clase de controlador del JDBC: opcional. El nombre de la clase de controlador debe corresponder a un origen de datos compatible con los rastreadores AWS Glue.
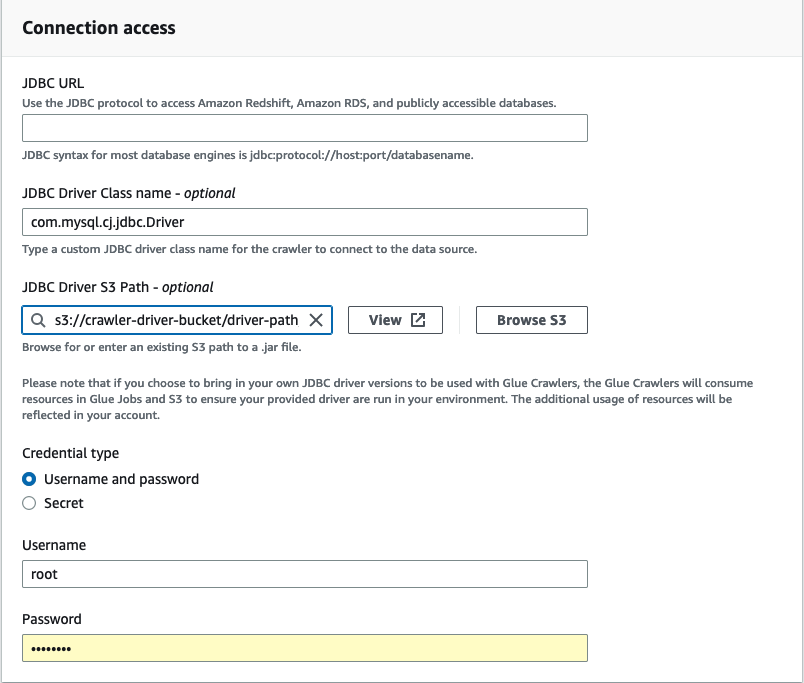
-
Elija la ruta de Amazon S3 en la que se encuentra el controlador JDBC en el campo Ruta Amazon S3 del controlador JDBC: opcional.
-
Rellene los campos correspondientes al tipo de credencial si ingresa un nombre de usuario y una contraseña o un secreto. Cuando haya terminado, elija Crear conexión.
nota
Las pruebas de conexiones no son compatibles en la actualidad. Al rastrear el origen de datos con un controlador JDBC que haya proporcionado, el rastreador omite este paso.
-
Agregue la conexión recién creada a un rastreador. En la consola AWS Glue, seleccione Rastreadores en el menú de la izquierda, en el Catálogo de datos y cree un rastreador nuevo.
-
En el asistente Agregar rastreadores, en el paso 2, elija Agregar un origen de datos.
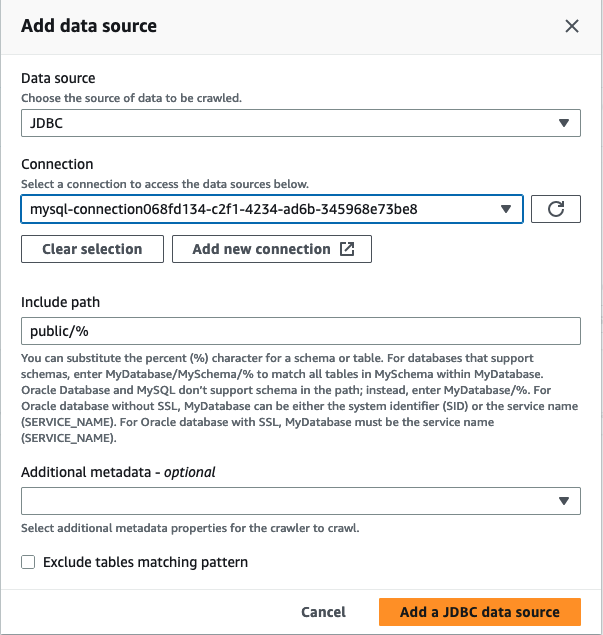
-
Elija JDBC como origen de datos y elija la conexión que se creó en los pasos anteriores. Completado
-
Para utilizar su propio controlador JDBC con un rastreador AWS Glue, agregue los siguientes permisos a la función utilizada por el rastreador:
-
Conceda permisos para las siguientes acciones de trabajos:
CreateJob,DeleteJob,GetJob,GetJobRun,StartJobRun. -
Conceda permisos para las acciones de IAM:
iam:PassRole -
Conceda permisos para todas las acciones de Amazon S3:
s3:DeleteObjects,s3:GetObject,s3:ListBucket,s3:PutObject. -
Conceda al director de servicio acceso al bucket o carpeta en la política de IAM.
Política de IAM de ejemplo:
El rastreador de AWS Glue crea dos carpetas: _glue_job_crawler y _crawler.
Si el archivo jar del controlador se encuentra en la carpeta
s3://amzn-s3-demo-bucket/driver.jar", agregue los siguientes recursos:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/_crawler/*" ]Si el archivo jar del controlador se encuentra en la carpeta
s3://amzn-s3-demo-bucket/tmp/driver/subfolder/driver.jar", agregue los siguientes recursos:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_crawler/*" ] -
-
Si utiliza una VPC, debe permitir el acceso al punto de conexión AWS Glue al crear el punto de conexión de la interfaz y agregarlo a la tabla de enrutamiento. Para obtener más información, consulte Creación de un punto de conexión de VPC para AWS Glue.
-
Si utiliza el cifrado en su catálogo de datos, cree el punto de conexión de la interfaz AWS KMS y agréguelo a la tabla de enrutamiento. Para obtener más información, consulte Crear un punto de conexión de VPC para AWS KMS.
