Tras considerarlo detenidamente, hemos decidido dejar de utilizar Amazon Kinesis Data Analytics para aplicaciones SQL:
1. A partir del 1 de septiembre de 2025, no proporcionaremos ninguna corrección de errores para las aplicaciones de Amazon Kinesis Data Analytics for SQL porque tendremos un soporte limitado debido a la próxima discontinuación.
2. A partir del 15 de octubre de 2025, no podrá crear nuevas aplicaciones de Kinesis Data Analytics for SQL.
3. Eliminaremos sus aplicaciones a partir del 27 de enero de 2026. No podrá iniciar ni utilizar sus aplicaciones de Amazon Kinesis Data Analytics para SQL. A partir de ese momento, el servicio de soporte de Amazon Kinesis Data Analytics para SQL dejará de estar disponible. Para obtener más información, consulte Retirada de las aplicaciones de Amazon Kinesis Data Analytics para SQL.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Aplicaciones de Amazon Kinesis Data Analytics para SQL: cómo funciona
nota
Después del 12 de septiembre de 2023, no podrá crear nuevas aplicaciones con Kinesis Data Firehose como origen si aún no utiliza Kinesis Data Analytics para SQL. Para obtener más información, consulte Límites.
Una aplicación es el recurso principal en Amazon Kinesis Data Analytics que puede crear en su cuenta. Puede crear y administrar aplicaciones mediante la API de Kinesis Data Analytics AWS Management Console o la API. Kinesis Data Analytics proporciona operaciones de la API para la administración de aplicaciones. Para ver la lista de operaciones de la API, consulte Acciones.
Las aplicaciones de análisis de datos de Kinesis Data Analytics leen y procesan datos de streaming en tiempo real de forma constante. Debe escribir el código de la aplicación con SQL para procesar los datos de streaming entrantes y producir la salida. A continuación, Kinesis Data Analytics escribe la salida en el destino que se haya configurado. El siguiente diagrama ilustra la arquitectura de una aplicación típica.
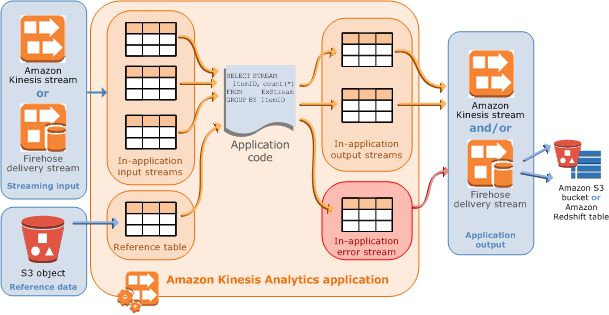
Cada aplicación tiene un nombre, descripción, ID de versión y estado. Amazon Kinesis Data Analytics asigna un ID de versión la primera vez que crea una aplicación. Se actualiza este ID de versión cuando actualiza la configuración de cualquier aplicación. Por ejemplo, si añade una configuración de entrada, añade o elimina un origen de datos de referencia, añade o elimina la configuración de salida o actualiza el código de la aplicación, Kinesis Data Analytics actualiza el ID de versión de la aplicación actual. Kinesis Data Analytics también mantiene marcas temporales de cuando se creó una aplicación y de su última actualización.
Además de estas propiedades básicas, cada aplicación se compone de lo siguiente:
-
Entrada: es el origen de streaming de la aplicación. Puede seleccionar un flujo de datos de Kinesis o un flujo de entrega de datos de Firehose como origen de flujo. En la configuración de entrada, debe asignar el origen de streaming a una secuencia de entrada en la aplicación. La secuencia en la aplicación se asemeja a una tabla que se actualiza constantemente, en la que puede realizar operaciones
SELECTeINSERT SQL. En su código de aplicación, puede crear flujos en la aplicación adicionales para almacenar los resultados intermedios de la consulta.Si lo desea, puede dividir un único origen de streaming en varias secuencias de entrada en la aplicación para mejorar el rendimiento. Para obtener más información, consulte Límites y Configuración de entrada de la aplicación.
Amazon Kinesis Data Analytics proporciona una columna de marca temporal denominada Marcas temporales y la comuna ROWTIME para cada secuencia en la aplicación. Puede utilizar esta columna en las consultas en ventana basadas en el tiempo. Para obtener más información, consulte Consultas en ventana.
Si lo desea, puede configurar un origen de datos de referencia para enriquecer el flujo de datos de entrada en la aplicación. Se produce una tabla de referencia en la aplicación. Debe almacenar los datos de referencia como un objeto en el bucket S3. Cuando se inicia la aplicación, Amazon Kinesis Data Analytics lee el objeto de Amazon S3 y crea una tabla en la aplicación. Para obtener más información, consulte Configuración de entrada de la aplicación.
-
Código de la aplicación: una serie de instrucciones SQL que procesan entradas y producen salidas. Puede escribir instrucciones de SQL en a secuencias en la aplicación y con tablas de referencia. También puede escribir consultas JOIN para combinar datos de ambos orígenes.
Para obtener información sobre los elementos del lenguaje SQL compatibles con Kinesis Data Analytics, consulte Referencia de SQL de Amazon Kinesis Data Analytics.
En su forma más sencilla, el código de la aplicación puede ser una única instrucción SQL que selecciona de una entrada de streaming e introduce los resultados en una salida de streaming. También puede ser una serie de instrucciones SQL en las que la salida de una alimenta la salida de la siguiente instrucción SQL. Además, puede escribir el código de aplicación para dividir una secuencia de entrada en varias secuencias. A continuación, puede aplicar consultas adicionales para procesar estas secuencias. Para obtener más información, consulte Código de la aplicación.
-
Salida: en el código de la aplicación, los resultados de las consultas van a secuencias en la aplicación. En el código de la aplicación, puede crear una o más secuencias en la aplicación adicionales para conservar resultados intermedios. Además, como opción, puede configurar la salida de la aplicación para que se envíen datos de secuencias en la aplicación, que mantengan la salida de la aplicación (se conocen también como reproducciones de salida en la aplicación), para destinos externos. Los destinos externos pueden ser un flujo de entrega de Firehose o un flujo de datos de Kinesis. Tenga en cuenta lo siguiente en relación con estos destinos:
-
Puede configurar una transmisión de entrega de Firehose para escribir los resultados en Amazon S3, Amazon Redshift o OpenSearch Amazon Service (ServiceOpenSearch ).
-
También puede escribir la salida de la aplicación en un destino personalizado, en lugar de Amazon S3 o Amazon Redshift. Para ello, debe especificar un flujo de datos de Kinesis como destino en la configuración de salida. A continuación, se configura AWS Lambda para sondear la transmisión e invocar la función Lambda. El código de la función de Lambda recibe datos de secuencia como entrada. En el código de la función de Lambda puede escribir los datos entrantes en su destino personalizado. Para obtener más información, consulte Uso AWS Lambda con Amazon Kinesis Data Analytics.
Para obtener más información, consulte Configuración de salida de la aplicación.
-
Además, tenga en cuenta lo siguiente:
-
Amazon Kinesis Data Analytics necesita permisos para leer los registros de un origen de streaming y escribir la salida de la aplicación en los destinos externos. Use los roles de IAM para otorgar estos permisos.
-
Kinesis Data Analytics proporciona automáticamente una secuencia de errores en la aplicación para cada aplicación. Si la aplicación tiene problemas al procesar determinados registros (por ejemplo, por un retraso o porque no coincide el tipo), ese registro se escribe en la secuencia de errores. Puede configurar la salida de la aplicación para indicar a Kinesis Data Analytics que conserve los datos de la secuencia de errores en un destino externo para su posterior evaluación. Para obtener más información, consulte Gestión de errores.
-
Amazon Kinesis Data Analytics garantiza que se escriben los registros de salida de la aplicación en el destino configurado. Utiliza "al menos un" modelo de entrega y procesamiento, incluso si se produce una interrupción de la aplicación. Para obtener más información, consulte Modelo de entrega para conservar la salida de las aplicaciones en destinos externos.
