Ya no actualizamos el servicio Amazon Machine Learning ni aceptamos nuevos usuarios para él. Esta documentación está disponible para los usuarios actuales, pero ya no la actualizamos. Para obtener más información, consulte Qué es Amazon Machine Learning.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Validación cruzada
La validación cruzada es una técnica para evaluar modelos de ML mediante el entrenamiento de varios modelos de ML en subconjuntos de los datos de entrada disponibles y evaluarlos con el subconjunto complementario de los datos. Utilice la validación cruzada para detectar el sobreajuste, es decir, en aquellos casos en los que no se logre generalizar un patrón.
En Amazon ML, puede utilizar el método de la validación cruzada de K iteraciones para realizar la validación cruzada. En la validación cruzada de K iteraciones se dividen los datos de entrada en K subconjuntos de datos (también conocido como iteraciones). Puede entrenar un modelo de ML en todos menos uno (k-1) de los subconjuntos y, a continuación, evaluar el modelo en el subconjunto que no se ha utilizado para el entrenamiento. Este proceso se repite K veces, con un subconjunto diferente reservado para la evaluación (y excluido del entrenamiento) cada vez.
En el siguiente diagrama se muestra un ejemplo de los subconjuntos de entrenamiento y de los subconjuntos de evaluación complementarios generados para cada uno de los cuatro modelos que se crean y se entrenan durante una validación cruzada de 4 iteraciones. El modelo uno utiliza el primer 25% de los datos para la evaluación y el 75% restante para el entrenamiento. El modelo dos utiliza el segundo subconjunto del 25% (del 25% al 50%) para la evaluación y los tres subconjuntos restantes de los datos para el entrenamiento y así sucesivamente.
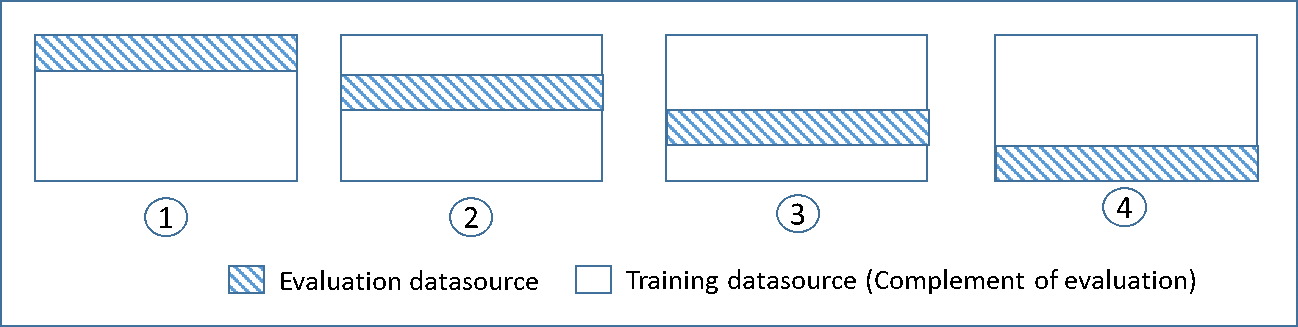
Cada modelo se entrena y se evalúa utilizando fuentes de datos complementarias: los datos de la fuente de datos incluyen y se limitan a todos los datos que no están en la fuente de datos para el entrenamiento. Las fuentes de datos para cada uno de estos subconjuntos se crean con el DataRearrangement parámetro encreateDatasourceFromS3, ycreateDatasourceFromRedShift. createDatasourceFromRDS APIs En el parámetro DataRearrangement, especifique qué subconjunto de datos se incluye en una fuente de datos especificando dónde comienza y finaliza cada segmento. Para crear las fuentes de datos complementarias necesarias para la validación cruzada de 4 iteraciones, especifique el parámetro DataRearrangement tal y como se muestra en el ejemplo siguiente:
Modelo uno:
Origen de datos para evaluación:
{"splitting":{"percentBegin":0, "percentEnd":25}}
Origen de datos para entrenamiento:
{"splitting":{"percentBegin":0, "percentEnd":25, "complement":"true"}}
Modelo dos:
Origen de datos para evaluación:
{"splitting":{"percentBegin":25, "percentEnd":50}}
Origen de datos para entrenamiento:
{"splitting":{"percentBegin":25, "percentEnd":50, "complement":"true"}}
Modelo tres:
Origen de datos para evaluación:
{"splitting":{"percentBegin":50, "percentEnd":75}}
Origen de datos para entrenamiento:
{"splitting":{"percentBegin":50, "percentEnd":75, "complement":"true"}}
Modelo cuatro:
Origen de datos para evaluación:
{"splitting":{"percentBegin":75, "percentEnd":100}}
Origen de datos para entrenamiento:
{"splitting":{"percentBegin":75, "percentEnd":100, "complement":"true"}}
Llevar a cabo una validación cruzada de 4 iteraciones genera cuatro modelos, cuatro fuentes de datos para entrenar los modelos, cuatro fuentes de datos para evaluar los modelos y cuatro evaluaciones, una para cada modelo. Amazon ML genera una métrica de desempeño del modelo para cada evaluación. Por ejemplo, en una validación cruzada de 4 iteraciones para un problema de clasificación binaria, cada una de las evaluaciones genera una métrica de Area Under the ROC Curve (AUC). Puede obtener la medición del desempeño general calculando la media de las cuatro métricas AUC. Para obtener información sobre la métrica AUC, consulte Medición de la precisión del modelo de ML.
Para ver código de muestra que ilustra cómo crear una validación cruzada y calcular la media de las puntuaciones del modelo, consulte el código de muestra de Amazon ML
Ajuste de los modelos
Una vez que le haya realizado una validación cruzada entre los modelos, puede ajustar la configuración del siguiente modelo si el modelo no alcanza sus estándares de rendimiento. Para obtener más información acerca del sobreajuste, consulte Ajuste del modelo: ajustes deficientes vs. ajustes excesivos. Para obtener más información acerca de la regularización, consulte Regularización. Para obtener más información acerca de cómo realizar cambios en la configuración de la regularización, consulte Creación de un modelo de ML con opciones personalizadas.
