Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Máquinas de estados Aurora y estados Step Functions
En esta sección se describen las máquinas de proceso y estado específicas de la conmutación por error y la recuperación de clústeres de Amazon Aurora. Los clústeres están configurados como una base de datos global.
nota
Con fines de demostración, en este ejemplo se utiliza Aurora MySQL Compatible Edition. Puede seguir pasos similares para Aurora PostgreSQL Compatible Edition.
Estado estacionario
En estado estable, se ha creado una base de datos global compatible con Amazon Aurora MySQL (dr-globaldb-cluster-mysql) con dos clústeres de bases de datos. El primer clúster de base de datos (db-cluster-01) se creó en el clúster principal Región de AWS
(us-east-1) para atender la carga de trabajo de lectura/escritura. El segundo clúster de base de datos (db-cluster-02) se creó en la región secundaria (us-west-2) para alojar la carga de trabajo de solo lectura.
Además de proporcionar la solución de recuperación ante desastres, puede reducir la carga en su clúster de base de datos principal enrutando las consultas de lectura de sus aplicaciones al clúster de base de datos secundario. Cada uno de estos clústeres contiene una instancia de base de datos denominada dbcluster-01-use1-instance-1 ydbcluster-02-usw2-instance-2, respectivamente.
Estado del evento
Al utilizar una base de datos global de Amazon Aurora, puede planificar y recuperarse de un desastre con bastante rapidez. La recuperación tras un desastre normalmente se mide utilizando valores para el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO). Para obtener más información, consulte Uso de la conmutación o la conmutación por error en una base de datos global de Amazon Aurora.
Con una base de datos global de Aurora, existen dos enfoques diferentes para la conmutación por error:
-
Conmutación (conmutación por error planificada y gestionada)
-
Conmutación por error (conmutación por error manual no planificada o desconexión y promoción)
Cambio
La conmutación está destinada a entornos controlados, como el mantenimiento operativo y otros procedimientos operativos planificados. Mediante una conmutación por error planificada y gestionada, puede reubicar el clúster de base de datos principal de su base de datos global de Aurora en una de las regiones secundarias. Como la conmutación espera a que los clústeres de bases de datos secundarios se sincronicen con la base de datos principal, el RPO es 0 (sin pérdida de datos). Para obtener más información, consulte Realizar cambios en las bases de datos globales de Amazon Aurora.
La máquina de dr-orchestrator-stepfunction-FAILOVER estados se invoca durante el estado del evento para cambiar el clúster principal a la región secundaria elegida ()us-west-2.
Para realizar el cambio, haz lo siguiente:
-
Inicie sesión en. AWS Management Console
-
Cambie la región a la región RD (
us-west-2). -
Vaya a Servicios y seleccione Step Functions.
-
Navegue hasta la máquina de
dr-orchestrator-stepfunction-FAILOVERestados. -
Selecciona Iniciar ejecución e introduce el siguiente código JSON en la
Input - optionalsección:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PlannedFailoverAurora", "resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier" } } ] } ] } -
La máquina de
dr-orchestrator-stepfunction-FAILOVERestados lee el tipo de recurso comoPlannedFailoverAuroraMySQL y llama a la máquina dedr-orchestrator-stepfunction-planned-Aurora-failoverestados para conmutar por error la base de datos global de Aurora.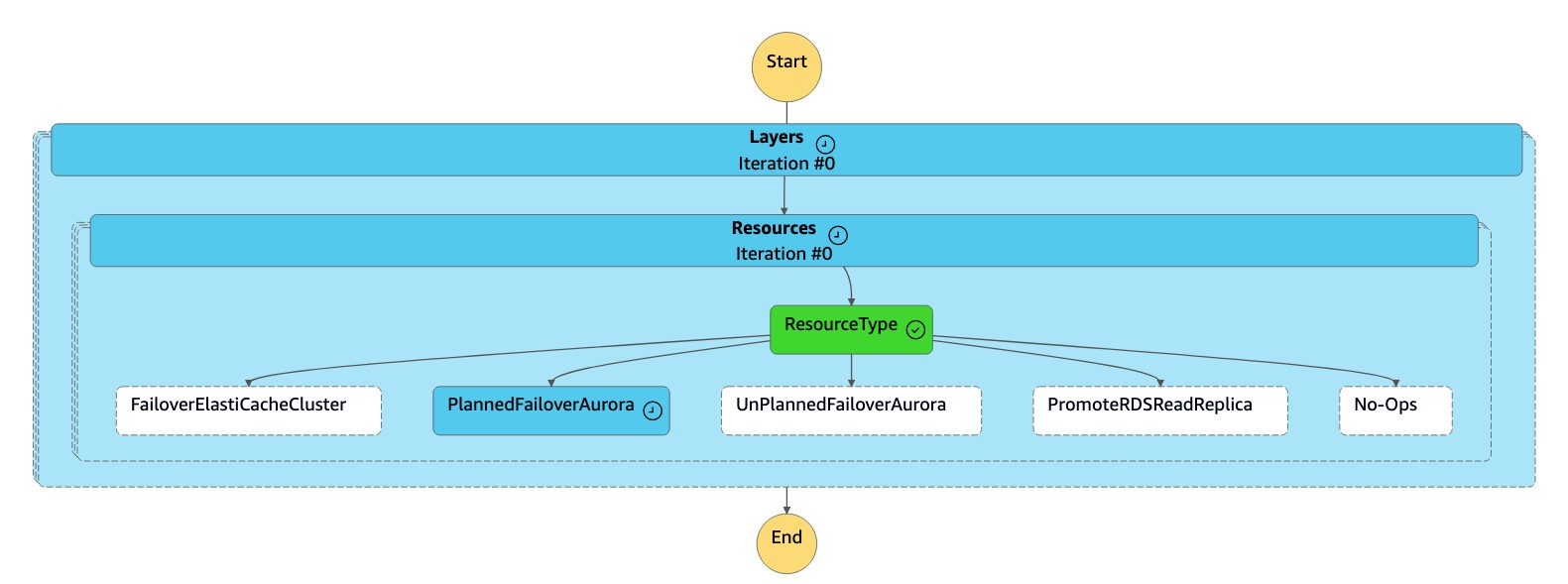
-
La máquina de
dr-orchestrator-stepfunction-planned-Aurora-failoverestados realiza los siguientes pasos para cambiar la función de base de datos global compatible con Aurora MySQL.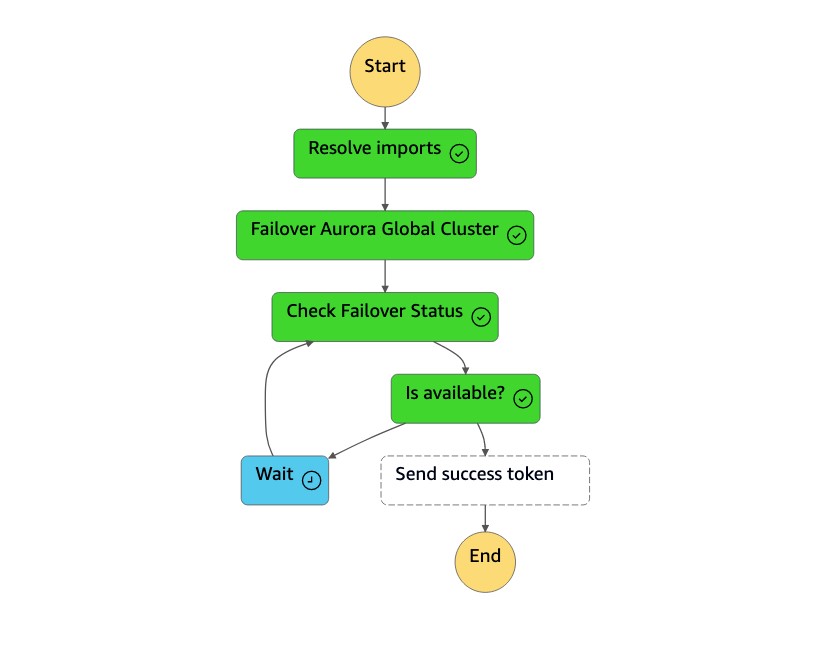
Paso Descripción Valores esperados Resolver las importaciones Una función Lambda reemplaza !Import <variable name>los valores por el nombre real."!Import dr-globaldb-cluster-mysql-global-identifier"se sustituye por"dr-globaldb-cluster-mysql".Clúster global Aurora de conmutación por error Una función Lambda llama a las API Boto3 failover_global_cluster para realizar la conmutación por error de la base de datos global Aurora. { 'GlobalCluster': { 'GlobalClusterIdentifier': 'dr-globaldb-cluster-mysql', 'GlobalClusterResourceId': 'cluster-cce7f9bec2846db4', 'GlobalClusterArn': 'arn:aws:rds::xxx', 'Status': 'failing-over', .... .... } }Compruebe el estado de la conmutación por error Una función Lambda llama a las API Boto3 describe_db_clusters para comprobar el estado de la conmutación por error. modificando, disponible Envía fichas de éxito Una función Lambda llama a las API de Boto3 send_task_success y envía un token de éxito a la máquina de estados. DR Orchestrator FailoverRiCdLtdH7x dMccoxlzFhglsdkzp /83P1E0 k9mBvKZSP7d9YrT1w -
Navegue hasta la consola de Amazon RDS. En Estado, los valores de la base de datos global Aurora cambiarán de Disponible a Conmutación o modificación.
-
Una vez completada la máquina de
dr-orchestrator-stepfunction-planned-Aurora-failoverestados, envía un testigo de éxito a la máquina dedr-orchestrator-stepfunction-FAILOVERestados.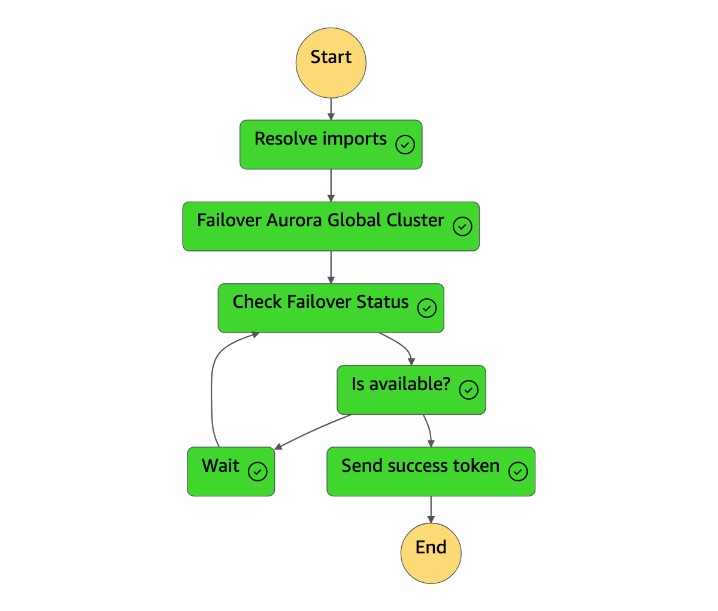
-
La máquina de
dr-orchestrator-stepfunction-FAILOVERestados está completa.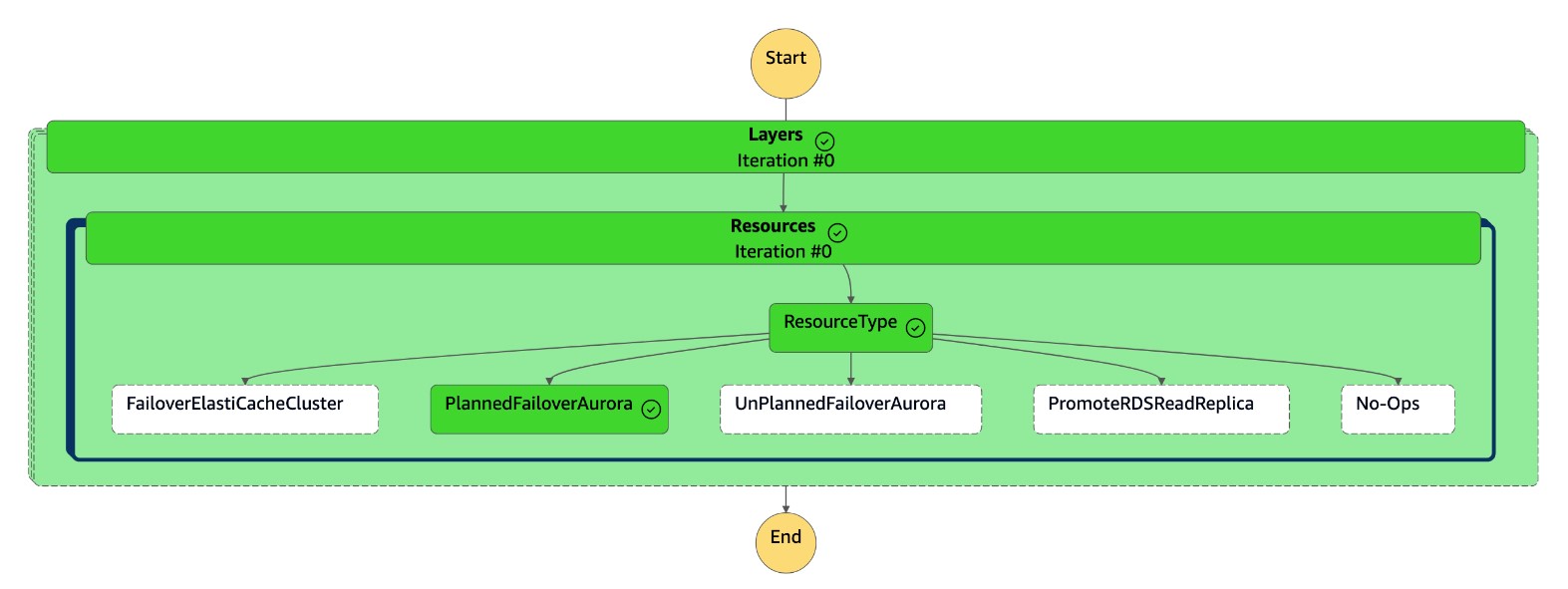
En la consola, la función del clúster secundario (dbcluster-02) ahora es clúster principal y el clúster está preparado para atender cargas de trabajo de lectura y escritura. La función del clúster principal original (dbcluster-01) ahora aparece como Clúster secundario.
Conmutación por error manual no planificada
En raras ocasiones, la base de datos global de Aurora podría sufrir una interrupción inesperada en su base de datos principal Región de AWS. Si esto sucede, el clúster principal de base de datos de Aurora y su nodo de escritor no estarán disponibles, y cesará la reproducción entre el clúster principal y los secundarios. Para minimizar tanto el tiempo de inactividad (RTO) como la pérdida de datos (RPO), realice rápidamente una conmutación por error entre regiones y reconstruya su base de datos global de Aurora. Para obtener más información, consulte Recuperación de una base de datos global de Amazon Aurora tras una interrupción imprevista.
Para realizar una conmutación por error no planificada, debe separar el clúster secundario de la base de datos global de Aurora. Antes de realizar la conmutación por error no planificada, detenga las escrituras de la aplicación en el clúster de base de datos Aurora principal. Una vez que la conmutación por error se haya completado correctamente, vuelva a configurar la aplicación para que escriba en el nuevo clúster de base de datos principal. Este enfoque ayuda a evitar la pérdida de datos. También ayuda a evitar incoherencias en los datos si el nodo de escritura principal vuelve a estar en línea durante el proceso de conmutación por error.
Para realizar la conmutación por error no planificada, llame a la máquina de estado. dr-orchestrator-stepfunction-FAILOVER En este ejemplo, el clúster secundario (db-cluster-02) se encuentra en la región DR (us-west-2) en estado estable.
Para realizar la conmutación por error, haga lo siguiente:
-
Inicie sesión en la consola de .
-
Cambie la región a la región DR (
us-west-2). -
Vaya a Servicios y seleccione Step Functions.
-
Navegue hasta la máquina de
dr-orchestrator-stepfunction-FAILOVERestados. -
Seleccione Iniciar ejecución e introduzca el siguiente código JSON en la
Input - optionalsección, utilizandoUnPlannedFailoverAuroracomoresourceType:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "UnPlannedFailoverAurora", "resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region" } } ] } ] } -
La máquina de
dr-orchestrator-stepfunction-FAILOVERestados lee el tipo de recurso comoUnPlannedFailoverAuroraMySQLy llama a la tareaDetach Cluster from Global Databasedesde la máquina dedr-orchestrator-stepfunction-unplanned-Aurora-failoverestados.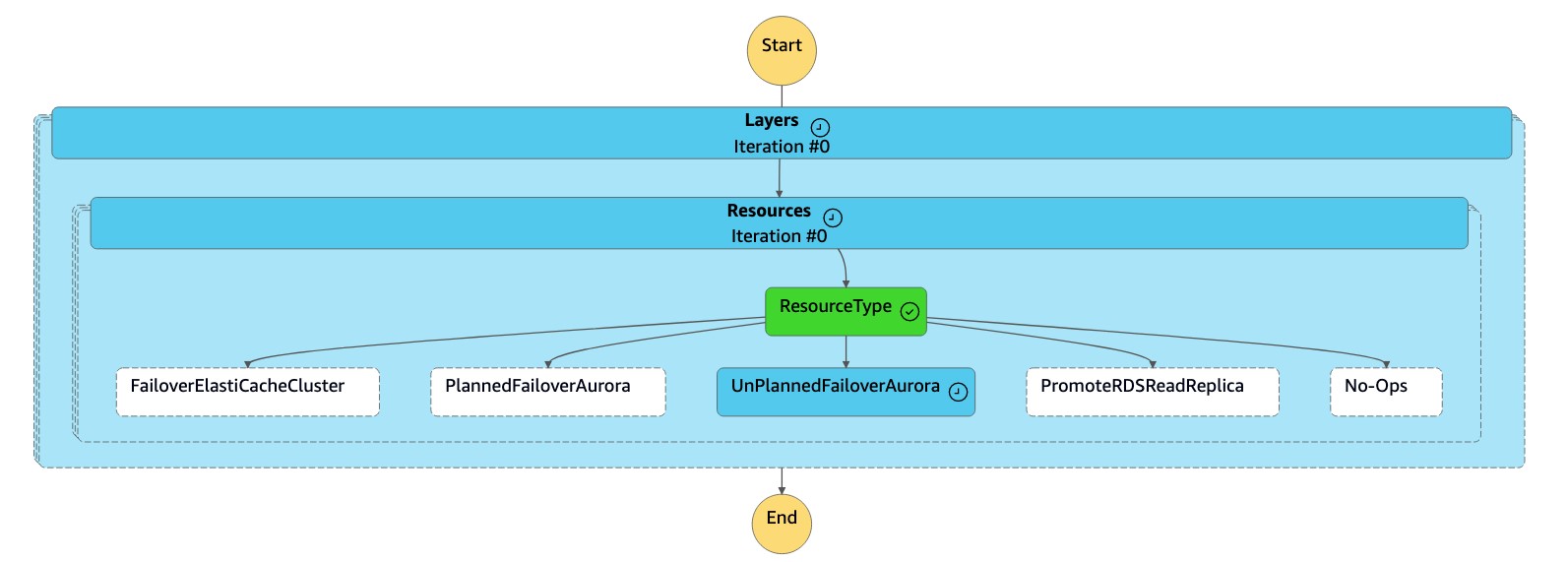
-
La
Detach Cluster from Global Databasetarea separa (elimina) el clúster secundario de la base de datos global.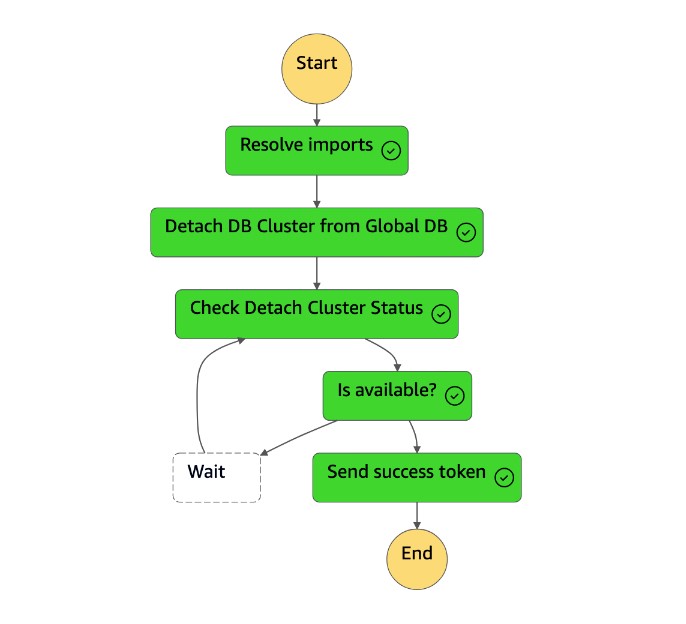
-
El clúster secundario (
dbcluster-02) pasa a ser un clúster independiente y puede atender cargas de trabajo de lectura y escritura. -
La máquina de
dr-orchestrator-stepfunction-FAILOVERestados está completa.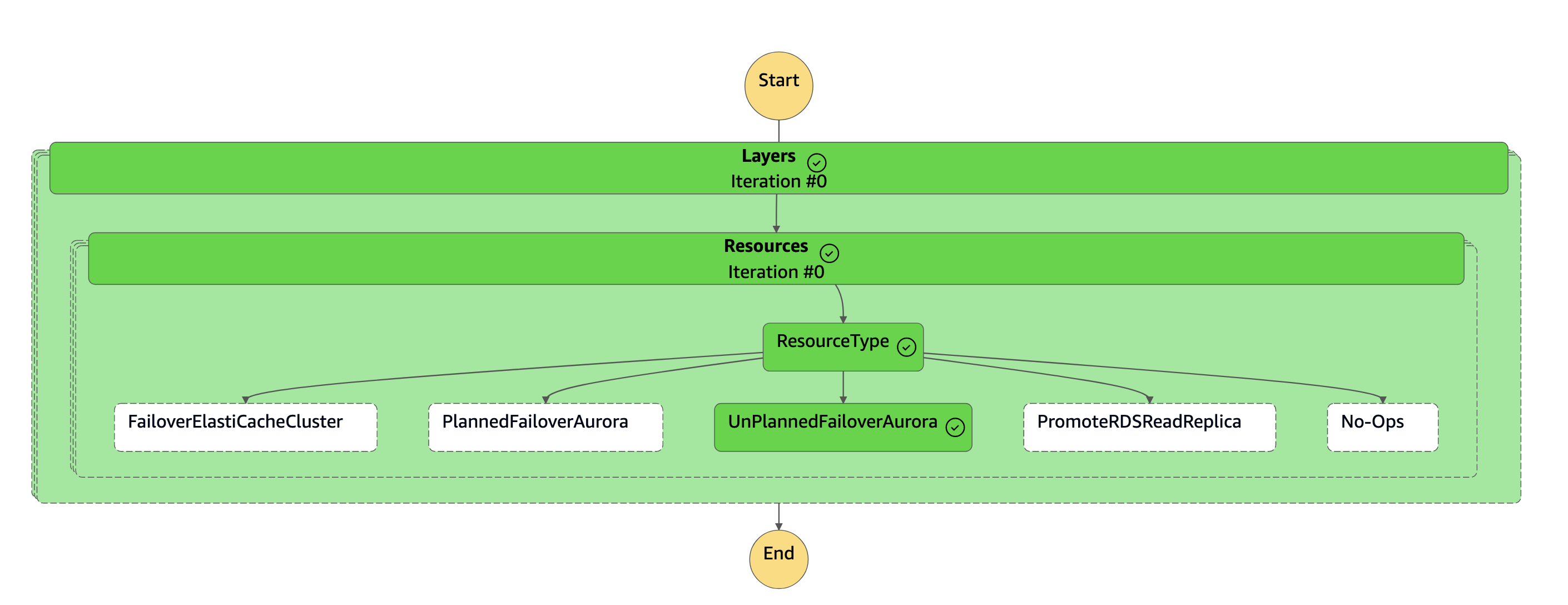
-
El clúster secundario (
dbcluster-02) se separa de la base de datos global de Aurora y se convierte en un clúster independiente para atender la carga de trabajo de lectura/escritura. -
Vuelva a configurar la aplicación para enviar todas las operaciones de escritura a este nuevo clúster de base de datos Aurora independiente mediante su nuevo punto final de clúster.
Recuperación por recuperación
Una recuperación por recuperación devuelve la base de datos a la ubicación principal original (o nueva) después de que se resuelva un desastre (o un evento programado). Cuando se haya resuelto la interrupción imprevista, es posible que desee volver a añadir su antigua región principal a la base de datos global de Aurora Aurora. Primero debe eliminar el clúster de base de datos existente de la región principal anterior, crear un nuevo clúster de base de datos a partir de la nueva región principal y, a continuación, utilizar el proceso de conmutación por error planificado y gestionado para cambiar la función del nuevo clúster.
Esto puede considerarse una actividad planificada que puede realizar fuera de las horas de mayor actividad o durante un fin de semana.
Debe modificar manualmente el clúster de base de datos Amazon Aurora e inhabilitarlo DeletionProtection antes de ejecutar la máquina de DR Orchestrator FAILBACK estado desde la región principal anterior (us-east-1) con la que se creóDeletionProtection.
DR Orchestrator Framework utiliza la máquina de dr-orchestrator-stepfunction-FAILBACK estados para automatizar los pasos necesarios para eliminar el clúster existente y crear uno nuevo en la antigua región principal.
Para deshabilitarloDeletionProtection, haga lo siguiente:
-
Inicie sesión en la consola de .
-
Cambie la región a la antigua región principal (
us-east-1). -
Navegue hasta la consola de Amazon RDS, seleccione el nombre del clúster (
dbcluster-01) y elija Modificar. -
En Protección contra eliminación, desactive la casilla Habilitar la protección contra eliminación y seleccione Continuar.
-
Seleccione Aplicar inmediatamente y, a continuación, seleccione Modificar clúster.
La máquina de DR Orchestrator FAILBACK estados se invoca durante el proceso de recuperación desde la región principal anterior (us-east-1).
Para realizar la conmutación por recuperación, haga lo siguiente:
-
Inicie sesión en la consola de .
-
Cambie la región a la antigua región principal (
us-east-1). -
Vaya a Servicios y, a continuación, seleccione Step Functions.
-
Navegue hasta la máquina de
DR Orchestrator FAILBACKestados. -
Selecciona Iniciar ejecución e introduce el siguiente código JSON en la
Input - optionalsección:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateAuroraSecondaryDBCluster", "resourceName": "To create secondary Aurora MySQL Global Database Cluster", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name", "SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier", "DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier", "Port": "!Import dr-globaldb-cluster-mysql-port", "DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class", "DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name", "VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids", "Engine": "!Import dr-globaldb-cluster-mysql-engine", "EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version", "KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId", "SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] } -
La máquina de
DR Orchestrator FAILBACKestados lee el tipo de recurso comoCreateAuroraSecondaryDBClustery llama a la máquina dedr-orchestrator-stepfunction-create-Aurora-Secondary-clusterestados.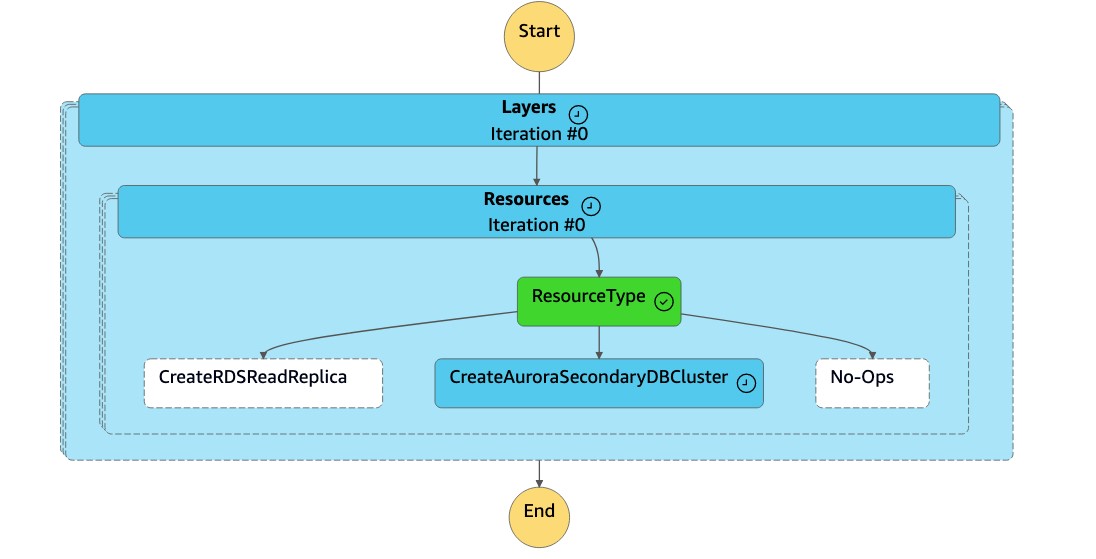
-
La máquina de
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterestados elimina el clúster existente (dbcluster-01) de la antigua región principal (us-east-1).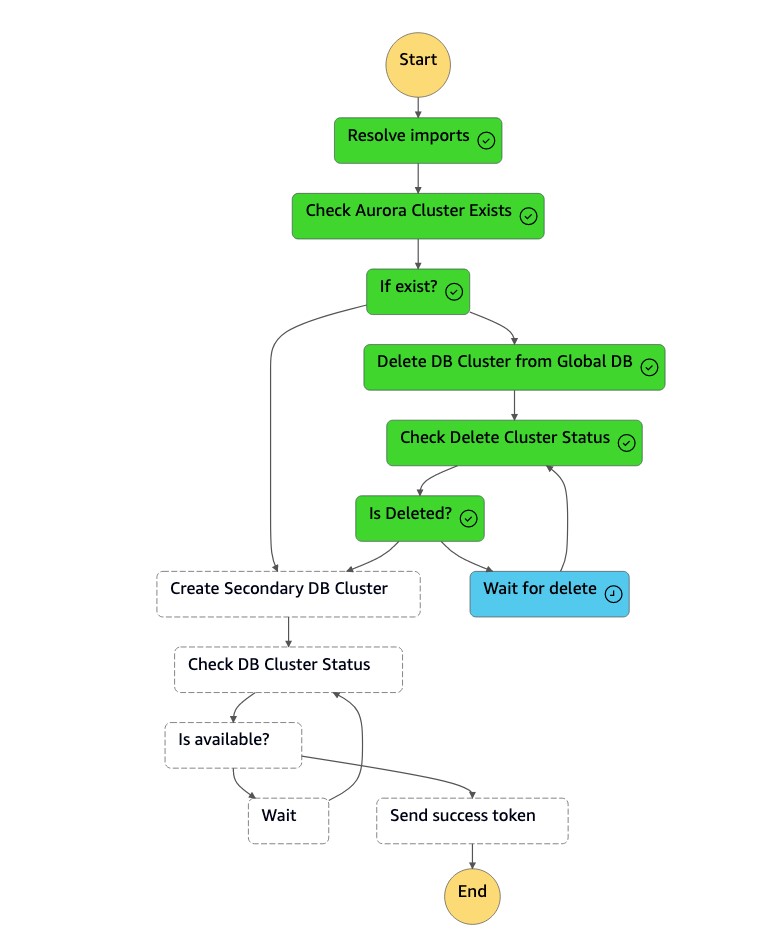
-
Tras eliminar el clúster (
dbcluster-01), la máquina de estado crea un nuevo clúster (dbcluster-01) junto con la instancia de base de datos y se une a la base de datos global Aurora como clúster secundario para atender cargas de trabajo de solo lectura.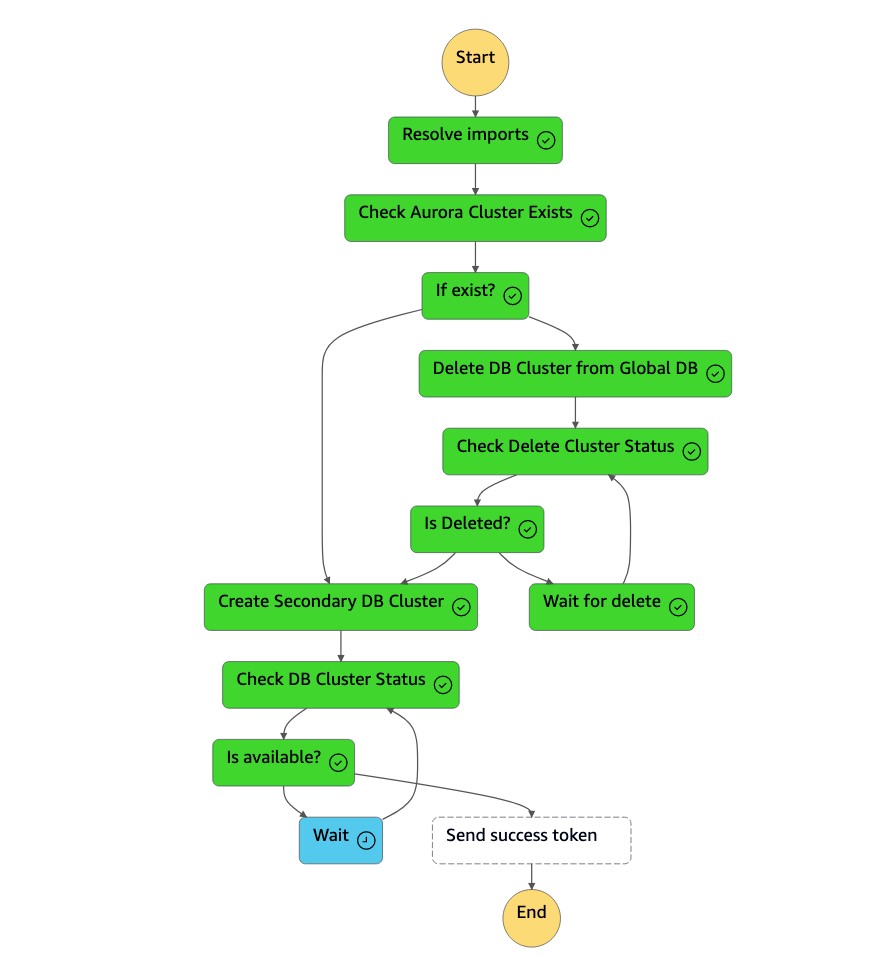
-
Cuando el clúster secundario está disponible, la máquina de
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterestados se completa y envía un token de éxito a la máquina deDR Orchestrator Failbackestados.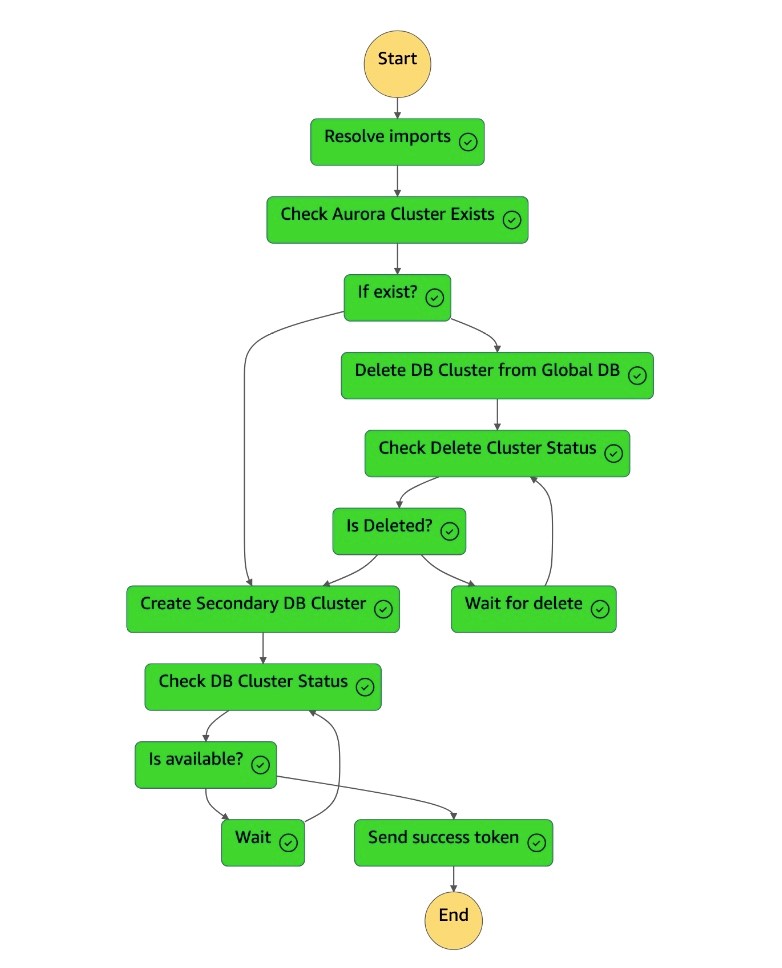
-
La máquina de
dr-orchestrator-stepfunction-FAILBACKestados está completa.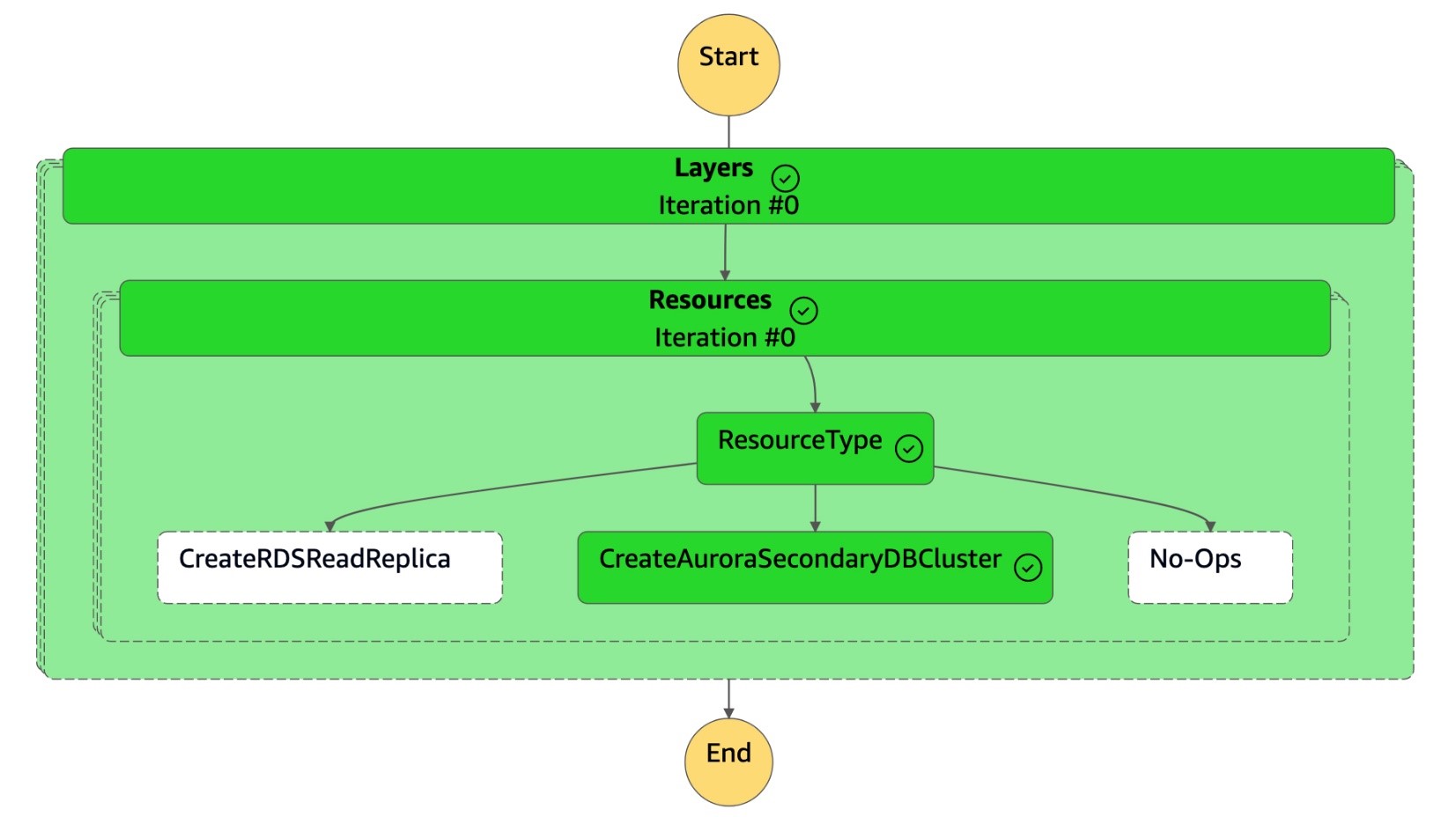
-
Puede comprobar la base de datos global de Aurora en la consola de Amazon RDS.
