Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Fase de procesamiento
Amazon Textract extrae el contenido de los archivos PDF en forma de cadenas que las aplicaciones posteriores no pueden utilizar directamente (por ejemplo, para generar estadísticas mediante la agregación de números). Los valores de datos correctamente identificados y transformados son necesarios porque las aplicaciones posteriores pueden utilizarlos más fácilmente (por ejemplo, para trazar las tendencias de los costos como una serie temporal). Para implementar el procesamiento de archivos PDF, un archivo PDF de cada nuevo tipo de archivo PDF debe procesarse una sola vez a través de Amazon Textract, que luego genera un archivo con formato Template JSON.
Una vez iniciada la AWS Lambda función enFase de ingestión, ejecuta los pasos que se muestran en el siguiente diagrama.
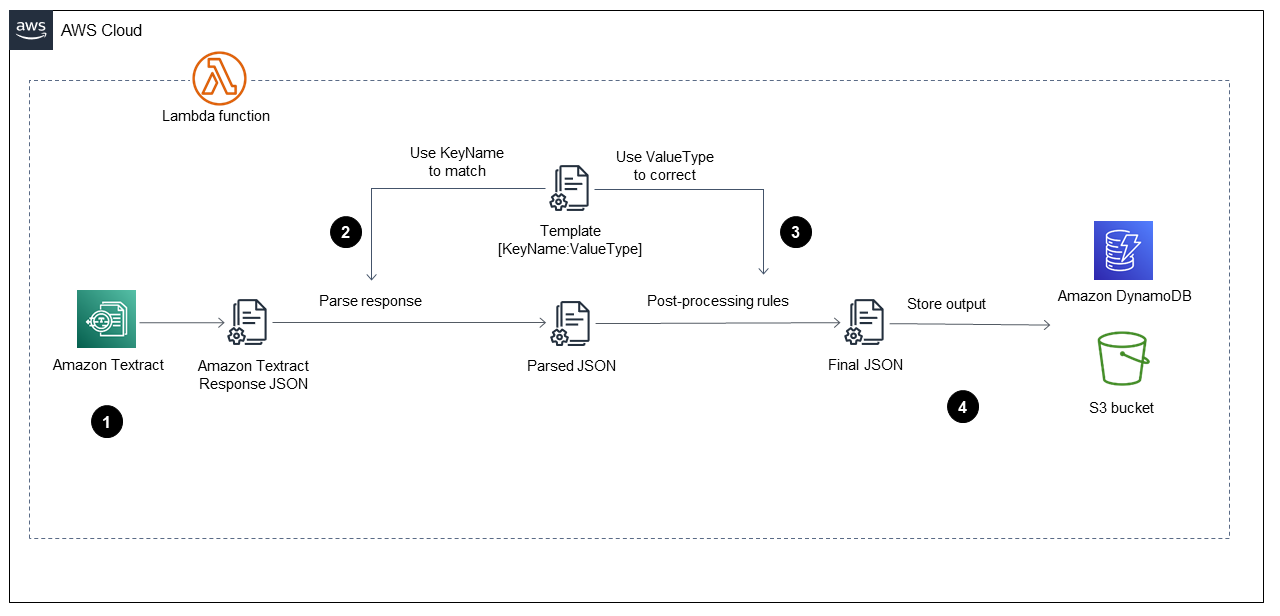
El diagrama muestra la función Lambda que implementa los siguientes pasos:
-
Pide a Amazon Textract que procese el archivo PDF, extraiga el contenido y devuelva un archivo con formato JSON.
-
Toma el archivo JSON y analiza los formularios y las tablas mediante un archivo
TemplateJSON predefinido que tiene el nombre de clave y el tipo de valor correctos para cada campo. Este proceso proporciona un archivo JSON analizado. -
Aplica las reglas de posprocesamiento y usa el archivo
TemplateJSON para corregir cada valor del archivo JSON analizado. Esto produce elFinalarchivo JSON. El archivoTemplateJSON predefinido se puede almacenar en el depósito de S3. -
Almacena el archivo
FinalJSON en Amazon DynamoDB como un registro para cada archivo PDF, además de un archivo JSON para cada archivo PDF de un depósito de salida de S3.
Para ver un step-by-step flujo de trabajo que utiliza Amazon Textract para extraer automáticamente contenido de archivos PDF y procesarlo hasta obtener una salida limpia, consulte el patrón Extraer contenido automáticamente de archivos PDF con Amazon Textract en AWS el sitio web de orientación prescriptiva. El patrón utiliza una técnica de coincidencia de plantillas para identificar correctamente el campo, el nombre clave y las tablas requeridos y, a continuación, aplica correcciones posteriores al procesamiento a cada tipo de datos.
Prácticas recomendadas para la fase de procesamiento
Utilice las cuatro mejores prácticas siguientes para garantizar una fase de procesamiento exitosa:
-
Cree una plantilla de archivo JSON para cada tipo de archivo PDF que desee procesar. Puede almacenar estos diferentes archivos JSON de plantilla en un bucket de S3 al que llama la función Lambda. Si desea procesar distintos tipos de archivos PDF en una función Lambda, debe utilizar un identificador único para cada tipo de archivo PDF (por ejemplo, el nombre de la carpeta del tipo de archivo PDF en el bucket de S3). Tras invocar la función Lambda, recupera el archivo JSON de plantilla correspondiente y lo procesa.
-
Configure un mecanismo para realizar un seguimiento preciso del estado de cada paso de la función Lambda. Por ejemplo, puede añadir
Successestados para después de la llamada a Amazon Textract, cuando el archivo JSON final se guarde en una tabla de Amazon DynamoDB o cuando los archivos PDF se guarden en un bucket de S3. También puede crear una tabla de DynamoDB independiente para realizar un seguimiento del estado de cada archivo PDF en los distintos pasos, lo que proporciona visibilidad del proceso. -
Gestione las limitaciones y las conexiones interrumpidas reintentando automáticamente las operaciones fallidas al procesar por lotes muchos archivos PDF. Se pueden producir limitaciones en Amazon Textract si tu conexión se interrumpe o si superas el número máximo de transacciones por segundo (TPS). Para obtener más información y los pasos para reintentar automáticamente las operaciones fallidas, consulte Gestión de llamadas restringidas y conexiones interrumpidas en la documentación de Amazon Textract.
-
Si tiene archivos PDF con varias páginas, puede utilizar una operación asíncrona para procesar todo el archivo o dividir el archivo PDF en una página individual, utilizar una operación sincrónica para procesar cada página y, a continuación, combinar los resultados de cada página. Para obtener una implementación de código completa de una operación asíncrona, consulte Detectar y analizar texto en documentos de varias páginas en la documentación de Amazon Textract. Para obtener más información sobre el uso de una operación sincrónica, consulte Detección y análisis de texto en documentos de una sola página en la documentación de Amazon Textract.
