Automatically extract content from PDF files using Amazon Textract
Tianxia Jia, Amazon Web Services
Summary
Many organizations need to extract information from PDF files that are uploaded to their business applications. For example, an organization could need to accurately extract information from tax or medical PDF files for tax analysis or medical claim processing.
On the Amazon Web Services (AWS) Cloud, Amazon Textract automatically extracts information (for example, printed text, forms, and tables) from PDF files and produces a JSON-formatted file that contains information from the original PDF file. You can use Amazon Textract in the AWS Management Console or by implementing API calls. We recommend that you use programmatic API calls
When Amazon Textract processes a file, it creates the following list of Block objects: pages, lines and words of text, forms (key-value pairs), tables and cells, and selection elements. Other object information is also included, for example, bounding boxes, confidence intervals, IDs, and relationships. Amazon Textract extracts the content information as strings. Correctly identified and transformed data values are required because they can be more easily used by your downstream applications.
This pattern describes a step-by-step workflow for using Amazon Textract to automatically extract content from PDF files and process it into a clean output. The pattern uses a template matching technique to correctly identify the required field, key name, and tables, and then applies post-processing corrections to each data type. You can use this pattern to process different types of PDF files and you can then scale and automate this workflow to process PDF files that have an identical format.
Prerequisites and limitations
Prerequisites
An active AWS account.
An existing Amazon Simple Storage Service (Amazon S3) bucket to store the PDF files after they are converted to JPEG format for processing by Amazon Textract. For more information about S3 buckets, see Buckets overview in the Amazon S3 documentation.
The
Textract_PostProcessing.ipynbJupyter notebook (attached), installed and configured. For more information about Jupyter notebooks, see Create a Jupyter notebook in the Amazon SageMaker documentation.Existing PDF files that have an identical format.
An understanding of Python.
Limitations
Your PDF files must be of good quality and clearly readable. Native PDF files are recommended, but you can use scanned documents that are converted to a PDF format if all the individual words are clear. For more information about this, see PDF document preprocessing with Amazon Textract: Visuals detection and removal
on the AWS Machine Learning Blog. For multipage files, you can use an asynchronous operation or split the PDF files into a single page and use a synchronous operation. For more information about these two options, see Detecting and analyzing text in multipage documents and Detecting and analyzing text in single-page documents in the Amazon Textract documentation.
Architecture
This pattern’s workflow first runs Amazon Textract on a sample PDF file (First-time run) and then runs it on PDF files that have an identical format to the first PDF (Repeat run). The following diagram shows the combined First-time run and Repeat run workflow that automatically and repeatedly extracts content from PDF files with identical formats.
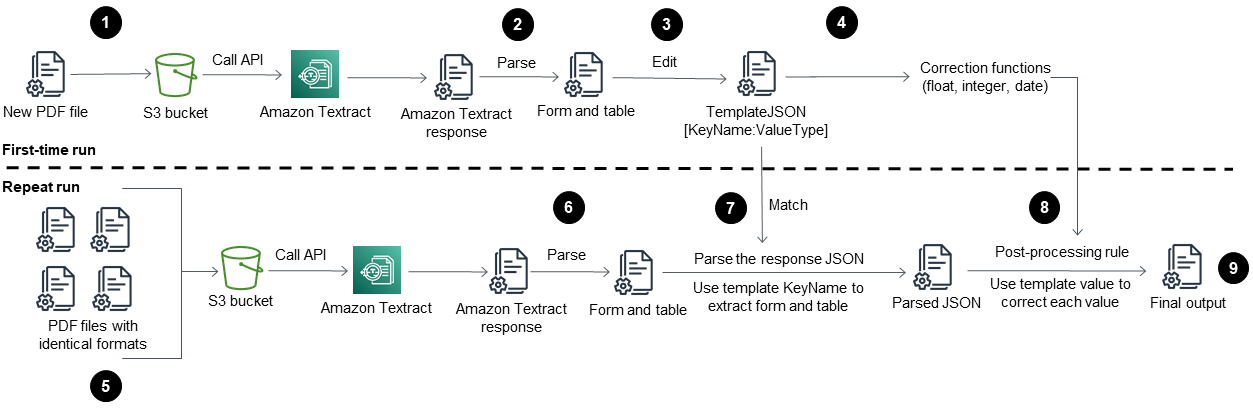
The diagram shows the following workflow for this pattern:
Convert a PDF file into JPEG format and store it in an S3 bucket.
Call the Amazon Textract API and parse the Amazon Textract response JSON file.
Edit the JSON file by adding the correct
KeyName:DataTypepair for each required field. Create aTemplateJSONfile for the Repeat run stage.Define the post-processing correction functions for each data type (for example, float, integer, and date).
Prepare the PDF files that have an identical format to your first PDF file.
Call the Amazon Textract API and parse the Amazon Textract response JSON.
Match the parsed JSON file with the
TemplateJSONfile.Implement post-processing corrections.
The final JSON output file has the correct KeyName and Value for each required field.
Target technology stack
Amazon SageMaker
Amazon S3
Amazon Textract
Automation and scale
You can automate the Repeat run workflow by using an AWS Lambda function that initiates Amazon Textract when a new PDF file is added to Amazon S3. Amazon Textract then runs the processing scripts and the final output can be saved to a storage location. For more information about this, see Using an Amazon S3 trigger to invoke a Lambda function in the Lambda documentation.
Tools
Amazon SageMaker is a fully managed ML service that helps you to quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment.
Amazon Simple Storage Service (Amazon S3) is a cloud-based object storage service that helps you store, protect, and retrieve any amount of data.
Amazon Textract makes it easy to add document text detection and analysis to your applications.
Epics
| Task | Description | Skills required |
|---|---|---|
Convert the PDF file. | Prepare the PDF file for your first-time run by splitting it into a single page and converting it into JPEG format for the Amazon Textract synchronous operation ( NoteYou can also use the Amazon Textract asynchronous operation ( | Data scientist, Developer |
Parse the Amazon Textract response JSON. | Open the
Parse the response JSON into a form and table by using the following code:
| Data scientist, Developer |
Edit the TemplateJSON file. | Edit the parsed JSON for each This template is used for each individual PDF file type, which means that the template can be reused for PDF files that have an identical format. | Data scientist, Developer |
Define the post-processing correction functions. | The values in Amazon Textract's response for the Correct each data type according to the
| Data scientist, Developer |
| Task | Description | Skills required |
|---|---|---|
Prepare the PDF files. | Prepare the PDF files by splitting them into a single page and converting them into JPEG format for the Amazon Textract synchronous operation ( NoteYou can also use the Amazon Textract asynchronous operation ( | Data scientist, Developer |
Call the Amazon Textract API. | Call the Amazon Textract API by using the following code:
| Data scientist, Developer |
Parse the Amazon Textract response JSON. | Parse the response JSON into a form and table by using the following code:
| Data scientist, Developer |
Load the TemplateJSON file and match it with the parsed JSON. | Use the
| Data scientist, Developer |
Post-processing corrections. | Use
| Data scientist, Developer |
Related resources
Attachments
To access additional content that is associated with this document, unzip the following file: attachment.zip
