Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación de canalizaciones de aprendizaje automático listas para la producción en AWS
Josiah Davis, Verdi March, Yin Song, Baichuan Sun, Chen Wu y Wei Yih Yap, Amazon Web Services ()AWS
Enero de 2021 (historial de documentos)
Los proyectos de machine learning (ML) requieren un esfuerzo significativo de varias etapas que incluye el modelado, la implementación y la producción para ofrecer valor empresarial y resolver problemas del mundo real. Hay numerosas alternativas y opciones de personalización disponibles en cada paso, lo que hace que sea cada vez más difícil preparar un modelo de ML para la producción dentro de las limitaciones de recursos y presupuesto. Durante los últimos años en Amazon Web Services (AWS), nuestro equipo de ciencia de datos ha trabajado con diferentes sectores de la industria en iniciativas de ML. Identificamos los problemas que muchos AWS clientes comparten y que se deben tanto a problemas organizativos como a desafíos técnicos, y hemos desarrollado un enfoque óptimo para ofrecer soluciones de aprendizaje automático listas para la producción.
Esta guía es para científicos de datos e ingenieros de ML que participan en las implementaciones en implementaciones de canalización de ML. Describe nuestro enfoque para ofrecer canalizaciones de ML listas para la producción. La guía explica cómo puede pasar de ejecutar modelos de ML de forma interactiva (durante el desarrollo) a implementarlos como parte de una canalización (durante la producción) para su caso de uso de ML. Para ello, también hemos desarrollado un conjunto de plantillas de ejemplo (consulte el proyecto ML Max
Descripción general
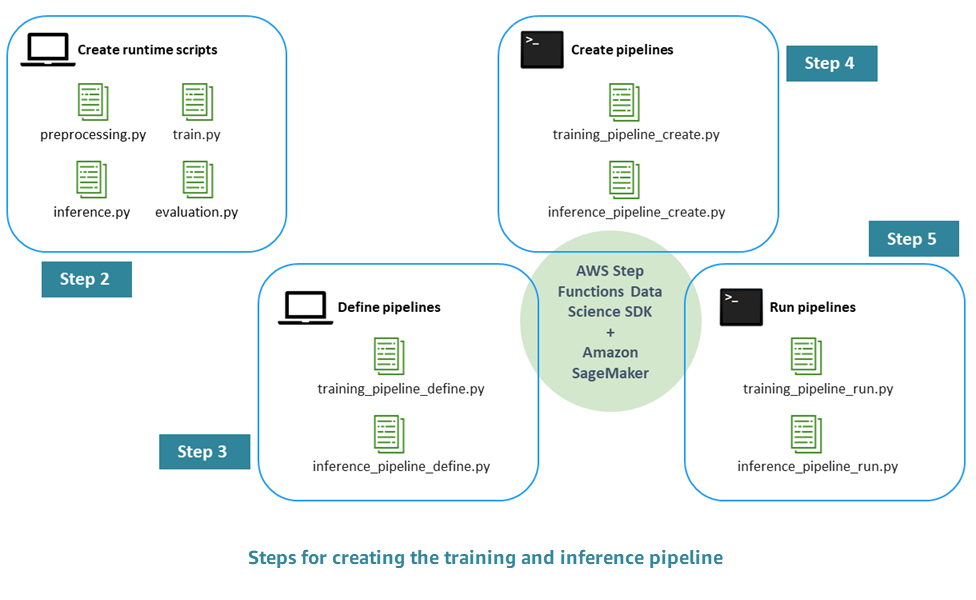
El proceso para crear una canalización de ML lista para la producción consta de los siguientes pasos:
-
Paso 1. Realice el EDA y desarrolle el modelo inicial: los científicos de datos hacen que los datos sin procesar estén disponibles en Amazon Simple Storage Service (Amazon S3), realizan análisis de datos exploratorios (EDA), desarrollan el modelo de aprendizaje automático inicial y evalúan su rendimiento de inferencia. Puede realizar estas actividades de forma interactiva a través de los cuadernos de Jupyter.
-
Paso 2. Cree los scripts en tiempo de ejecución: integre el modelo con los scripts de Python en tiempo de ejecución para que pueda administrarse y aprovisionarse mediante un marco de aprendizaje automático (en nuestro caso, Amazon SageMaker AI). Este es el primer paso para pasar del desarrollo interactivo de un modelo independiente al de producción. En concreto, usted define la lógica para el preprocesamiento, la evaluación, el entrenamiento y la inferencia por separado.
-
Paso 3. Defina la canalización: defina los marcadores de entrada y salida para cada paso de la canalización. Los valores concretos para estos valores se proporcionarán más adelante, durante el tiempo de ejecución (paso 5). Usted se centra en los procesos de entrenamiento, inferencia, validación cruzada y pruebas retrospectivas.
-
Paso 4. Cree la canalización: cree la infraestructura subyacente, incluida la instancia de la máquina de AWS Step Functions estado, de forma automatizada (casi con un clic), mediante el uso de. AWS CloudFormation
-
Paso 5. Ejecute la canalización: usted ejecuta la canalización definida en el paso 4. También debe preparar los metadatos y los datos o las ubicaciones de los datos para rellenar valores concretos para los marcadores de entrada y salida que definió en el paso 3. Esto incluye los scripts del tiempo de ejecución definidos en el paso 2, así como los hiperparámetros del modelo.
-
Paso 6. Amplíe la cartera: usted implementa los procesos de integración e implementación continuos (CI/CD), readiestramiento automatizado, inferencia programada y extensiones similares de la canalización.
El siguiente diagrama ilustra los principales pasos de este proceso.