Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Prácticas recomendadas
Le recomendamos que siga las mejores prácticas técnicas y de almacenamiento. Estas prácticas recomendadas pueden ayudarlo a aprovechar al máximo su arquitectura centrada en los datos.
Prácticas recomendadas de almacenamiento para macrodatos
En la siguiente tabla se describe una práctica recomendada común para almacenar archivos para una carga de procesamiento de big data en Amazon S3. La última columna es un ejemplo de una política de ciclo de vida que puede establecer. Si Amazon S3 Intelligent-Tiering
Nombre de la capa de datos | Descripción | Ejemplo de estrategia de política de ciclo de vida |
Raw | Contiene datos sin procesar y sin procesar Nota: En el caso de una fuente de datos externa, la capa de datos sin procesar suele ser una copia 1:1 de los datos, pero en AWS los datos se pueden dividir por claves en función de la región de AWS o de la fecha durante el proceso de ingesta. | Transcurrido un año, transfiera los archivos a la clase de almacenamiento S3 Standard-IA. Tras dos años en S3 Standard-IA, archive los archivos en Amazon Simple Storage Service Glacier (Amazon S3 Glacier). |
Escenario | Contiene datos procesados de forma intermedia que están optimizados para el consumo Ejemplo: archivos sin procesar o transformaciones de datos convertidos de CSV a Apache Parquet | Puede eliminar los datos después de un período de tiempo definido o según los requisitos de su organización. Puede eliminar algunos derivados de datos (por ejemplo, una transformación de Apache Avro de un formato JSON original) del lago de datos después de un período de tiempo más corto (por ejemplo, después de 90 días). |
Análisis | Contiene los datos agregados para sus casos de uso específicos en un formato listo para el consumo Ejemplo: Apache Parquet | Puede mover los datos a S3 Standard-IA y, después, eliminarlos después de un período de tiempo definido o según los requisitos de su organización. |
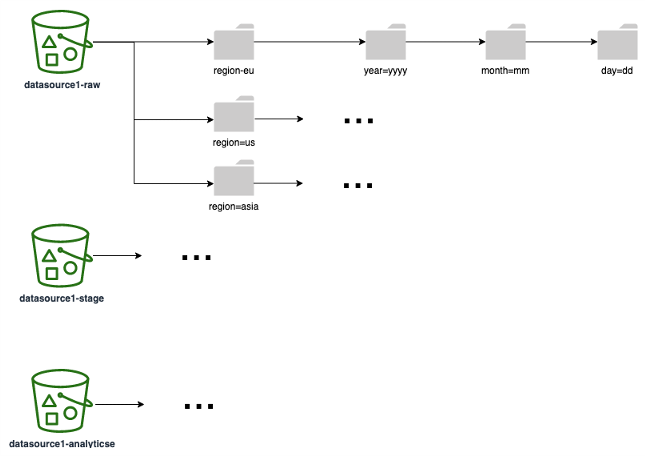
El siguiente diagrama muestra un ejemplo de una estrategia de partición (correspondiente a una carpeta o prefijo de S3) que puede utilizar en todas las capas de datos. Le recomendamos que elija una estrategia de particionamiento en función de cómo se usen sus datos en sentido descendente. Por ejemplo, si los informes se basan en sus datos (donde las consultas más comunes del informe filtran los resultados en función de la región y las fechas), asegúrese de incluir las regiones y las fechas como particiones para mejorar el rendimiento y el tiempo de ejecución de las consultas.
Mejores prácticas técnicas
Las mejores prácticas técnicas dependen de los servicios y tecnologías de procesamiento específicos de AWS que utilice para diseñar su arquitectura centrada en los datos. Sin embargo, le recomendamos que tenga en cuenta las siguientes prácticas recomendadas. Estas prácticas recomendadas se aplican a los casos de uso típicos del procesamiento de datos.
Área | Práctica recomendada |
SQL | Reduzca la cantidad de datos que deben consultarse proyectando los atributos en los datos. En lugar de analizar toda la tabla, puede utilizar la proyección de datos para escanear y devolver solo determinadas columnas obligatorias de la tabla. Si es posible, evite las uniones grandes, ya que las uniones entre varias tablas pueden afectar significativamente al rendimiento debido a que requieren muchos recursos. |
Apache Spark | Optimice las aplicaciones de Spark Optimice la administración de memoria |
Diseño de bases de datos | Siga las prácticas recomendadas de arquitectura para bases de datos |
Depuración de datos | Utilice la depuración de particiones del lado del servidor con. |
Escalado | Comprenda e implemente el escalado horizontal |
