Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Agregue datos en Amazon DynamoDB para pronósticos de ML en Athena
Sachin Doshi y Peter Molnar, Amazon Web Services
Resumen
Este patrón muestra cómo compilar agregaciones complejas de datos de Internet de las cosas (IoT) en una tabla de Amazon DynamoDB mediante Amazon Athena. También aprenderá a enriquecer los datos con inferencias de aprendizaje automático (ML) mediante Amazon SageMaker AI y a consultar datos geoespaciales mediante Athena. Puede usar este patrón como base para crear una solución de pronóstico de ML que satisfaga las necesidades de su organización.
Con fines de demostración, este patrón emplea como ejemplo una empresa que opera un servicio de transporte compartido de patinetes, y quiere predecir la cantidad óptima de patinetes a instalar para los clientes de diferentes barrios urbanos. La empresa usa un modelo de ML previamente entrenado que predice la demanda de los clientes para la próxima hora en función de las últimas cuatro horas. Este escenario emplea un conjunto de datos públicos de la Oficina de Innovación y Tecnología Cívicas
Requisitos previos y limitaciones
Un activo Cuenta de AWS
Permisos para crear una AWS CloudFormation pila con funciones AWS Identity and Access Management (de IAM) para lo siguiente:
Bucket de Amazon Simple Storage Service (Amazon S3)
Athena
DynamoDB
SageMaker IA
AWS Lambda
Arquitectura
Pila de tecnología
Amazon QuickSight
Amazon S3
Athena
DynamoDB
Lambda
SageMaker IA
Arquitectura de destino
En el siguiente diagrama, se muestra una arquitectura para crear agregaciones de datos complejas en DynamoDB mediante las capacidades de consulta de Athena, una función de Lambda, el almacenamiento de Amazon S3, un punto de conexión de IA y un panel de control. SageMaker QuickSight
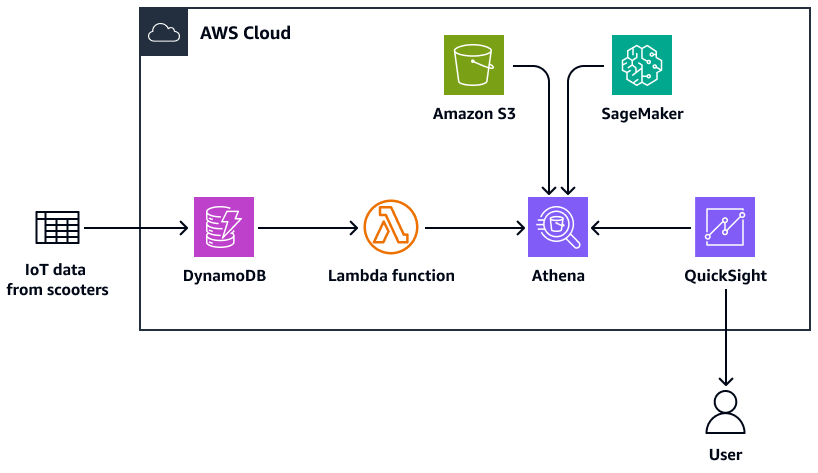
En el diagrama, se muestra el siguiente flujo de trabajo:
Una tabla de DynamoDB incorpora los datos de IoT que se transmiten desde una flota de patinetes.
Una función de Lambda carga la tabla de DynamoDB con los datos incorporados.
Una consulta de Athena crea una nueva tabla de DynamoDB para datos geoespaciales que representan los barrios urbanos.
La ubicación de la consulta se guarda en un bucket de S3.
Una función Athena consulta la inferencia de ML desde el punto final de SageMaker IA que aloja el modelo de ML previamente entrenado.
Athena consulta los datos directamente de las tablas de DynamoDB y los agrega para su análisis.
Un usuario ve el resultado de los datos analizados en un panel de control. QuickSight
Herramientas
Servicios de AWS
Amazon Athena es un servicio de consultas interactivo que facilita el análisis de datos en Amazon S3 con SQL estándar.
Amazon DynamoDB es un servicio de base de datos de NoSQL completamente administrado que ofrece un rendimiento rápido, predecible y escalable.
Amazon SageMaker AI es un servicio de aprendizaje automático gestionado que le ayuda a crear y entrenar modelos de aprendizaje automático y, a continuación, implementarlos en un entorno hospedado listo para la producción.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que le ayuda a almacenar, proteger y recuperar cualquier cantidad de datos.
Amazon QuickSight es un servicio de inteligencia empresarial (BI) a escala de nube que le ayuda a visualizar, analizar y elaborar informes sobre sus datos en un único panel de control.
AWS Lambda es un servicio de computación que ayuda a ejecutar código sin necesidad de aprovisionar ni administrar servidores. Ejecuta el código solo cuando es necesario y amplía la capacidad de manera automática, por lo que solo pagará por el tiempo de procesamiento que utilice.
Repositorio de código
El código de este patrón está disponible en el repositorio GitHub Use ML predictions over Amazon DynamoDB data with Amazon Athena
Una tabla de DynamoDB
Una función de Lambda para cargar la tabla con los datos relevantes
Un punto final de SageMaker IA para las solicitudes de inferencia, con el XGBoost modelo previamente entrenado que se almacena en Amazon S3
Un grupo de trabajo de Athena llamado
V2EngineWorkGroupConsultas con nombre de Athena para buscar los archivos geoespaciales y predecir la demanda de patinetes
Un conector Amazon Athena DynamoDB prediseñado que permite a Athena comunicarse con DynamoDB y AWS SAM utiliza () para crear la aplicación en referencia al conector AWS Serverless Application Model DynamoDB
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Descargue el conjunto de datos y los recursos. |
| Desarrollador de aplicaciones, científico de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Crea una CloudFormation pila. |
notaLa CloudFormation pila puede tardar entre 15 y 20 minutos en crear estos recursos. | AWS DevOps |
Verifique la CloudFormation implementación. | Para comprobar que los datos de ejemplo de la CloudFormation plantilla se cargan en DynamoDB, haga lo siguiente:
| Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree una tabla de Athena con datos geoespaciales. | Para cargar los archivos de geolocalización en Athena, haga lo siguiente:
La consulta crea una nueva tabla para datos geoespaciales que representan los barrios urbanos. La tabla de datos se crea a partir de archivos shapefile de GIS. La instrucción Para ver el código Python para procesar los shapefiles y producir esta tabla, consulte Procesamiento geoespacial de shapefiles de SIG con Amazon | Ingeniero de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Declare una función en Athena para consultar SageMaker la IA. |
| Científico de datos, ingeniero de datos |
Pronostique la demanda de patinetes en función del barrio a partir de los datos agregados de DynamoDB. | Ahora puede usar Athena para consultar datos transaccionales directamente desde DynamoDB y, a continuación, agregar los datos para su análisis y previsión. Esto no se consigue fácilmente consultando directamente una base de datos NoSQL de DynamoDB.
La instrucción SQL hace lo siguiente:
| Desarrollador de aplicaciones, científico de datos |
Verifique el resultado. | La tabla de resultados incluye el barrio, la longitud y la latitud de su centroide. También incluye la cantidad de vehículos que se prevé para la próxima hora. La consulta produce las predicciones para un momento determinado. Puede realizar predicciones para cualquier otro momento cambiando la expresión Si tiene un origen de datos en tiempo real en la tabla de DynamoDB, cambie la marca temporal a | Desarrollador de aplicaciones, científico de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Delete resources (Eliminar recursos). |
| Desarrollador de aplicaciones, AWS DevOps |
Recursos relacionados
Consulta de datos geoespaciales (documentación)AWS
Amazon ElastiCache (Redis OSS)
(AWS documentación)
