Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Emule Oracle DR mediante una base de datos global de Aurora compatible con PostgreSQL
HariKrishna Boorgadda, Amazon Web Services
Resumen
Las prácticas recomendadas para la recuperación de desastres (DR) a nivel empresarial consisten, básicamente, en diseñar e implementar sistemas de hardware y software tolerantes a fallos que puedan sobrevivir a un desastre (continuidad de la actividad empresarial) y reanudar las operaciones normales (reanudación de la actividad empresarial) con una intervención mínima e, idealmente, sin pérdida de datos. Crear entornos tolerantes a fallos para cumplir los objetivos de la DR empresarial puede ser una empresa larga y costosa, y requiere un firme compromiso por parte de la empresa.
Oracle Database ofrece tres enfoques diferentes de recuperación de desastres que proporcionan el nivel más alto de protección y disponibilidad de datos en comparación con cualquier otro enfoque para proteger datos de Oracle.
Dispositivo de recuperación sin pérdida de datos de Oracle
Oracle Active Data Guard
Oráculo GoldenGate
Este patrón proporciona una forma de emular la recuperación ante GoldenGate desastres de Oracle mediante una base de datos global de Amazon Aurora. La arquitectura de referencia utiliza Oracle GoldenGate for DR en tres regiones de AWS. El patrón redefine la plataforma de la arquitectura de origen a la base de datos global de Aurora, nativa en la nube y basada en la edición compatible con PostgreSQL de Amazon Aurora.
Las bases de datos globales de Aurora están diseñadas para aplicaciones con una huella global. Una única base de datos de Aurora puede abarcar varias regiones de AWS con hasta cinco regiones secundarias. Las bases de datos globales de Aurora ofrecen las siguientes características:
Replicación física a nivel de almacenamiento
Lecturas globales de baja latencia
Recuperación de desastres rápida tras interrupciones en toda la región
Migraciones rápidas entre regiones
Bajo retraso de replicación en todas las regiones
Little-to-no impacto en el rendimiento de su base de datos
Para obtener más información sobre las características y ventajas de las bases de datos globales de Aurora, consulte Uso de las bases de datos globales de Amazon Aurora. Para obtener más información sobre las conmutaciones por error gestionadas y no planificadas, consulte Uso de la conmutación por error en una base de datos global de Amazon Aurora.
Requisitos previos y limitaciones
Requisitos previos
Una cuenta de AWS activa
Un controlador PostgreSQL de Java Database Connectivity (JDBC) para conectividad de aplicaciones
Una base de datos global de Aurora basada en Amazon Aurora compatible con PostgreSQL
Una base de datos de Oracle Real Application Clusters (RAC) migrada a la base de datos global de Aurora basada en Aurora compatible con PostgreSQL
Limitaciones de las bases de datos globales de Aurora
Las bases de datos globales de Aurora no están disponibles en todas las regiones de AWS. Para obtener una lista de las regiones compatibles, consulte Bases de datos globales de Aurora con Aurora PostgreSQL.
Para obtener información sobre las características no compatibles y otras limitaciones de las bases de datos globales de Aurora, consulte Limitaciones de las bases de datos globales de Amazon Aurora.
Versiones de producto
Amazon Aurora, edición compatible con PostgreSQL, versión 10.14 o posterior
Arquitectura
Pila de tecnología de origen
Base de datos de Oracle RAC de cuatro nodos
Oracle GoldenGate
Arquitectura de origen
El siguiente diagrama muestra tres clústeres con Oracle RAC de cuatro nodos en diferentes regiones de AWS replicados mediante Oracle. GoldenGate

Pila de tecnología de destino
Una base de datos global de Amazon Aurora de tres clústeres basada en Aurora compatible con PostgreSQL, con un clúster en la región principal y dos clústeres en diferentes regiones secundarias
Arquitectura de destino
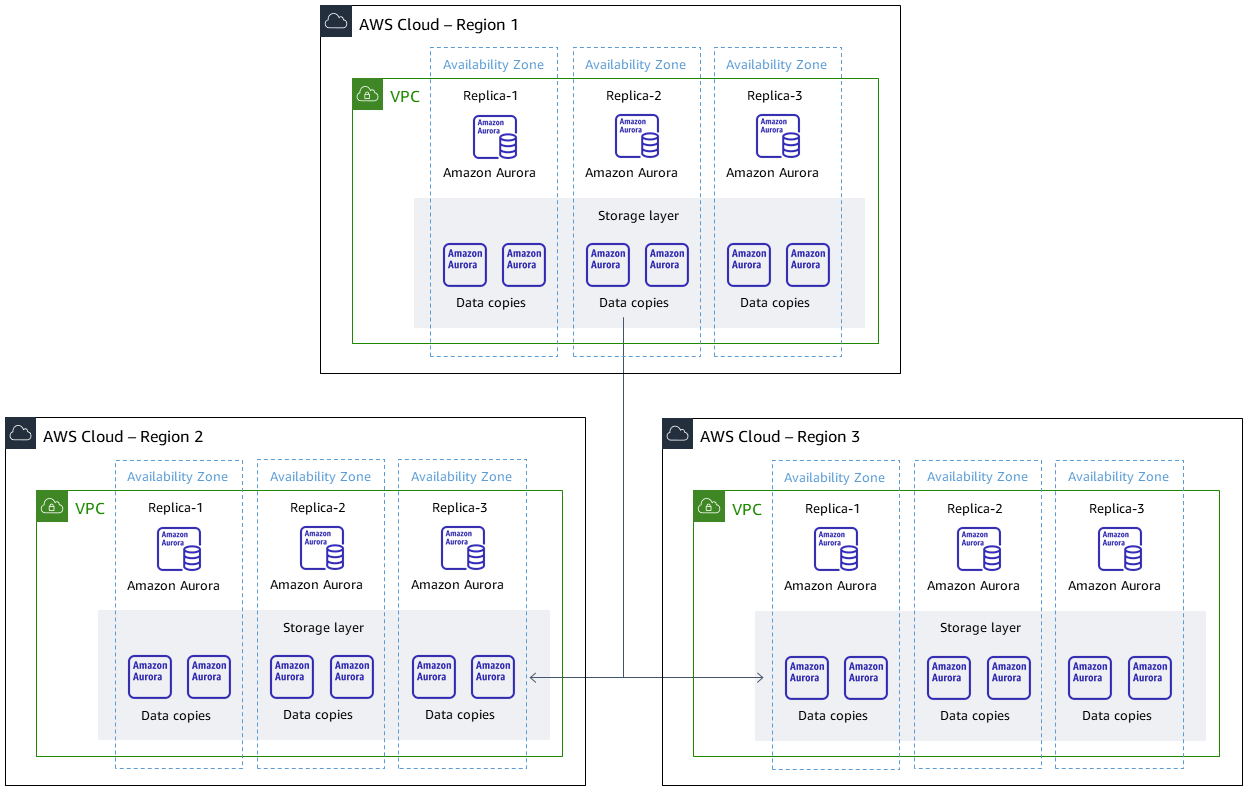
Herramientas
Servicios de AWS
La edición de Amazon Aurora compatible con PostgreSQL es un motor de base de datos relacional compatible con ACID, completamente administrado que le permite configurar, utilizar y escalar implementaciones de PostgreSQL.
Las bases de datos globales de Amazon Aurora abarcan varias regiones de AWS, lo que permite lecturas globales de baja latencia y proporcionan una recuperación rápida de cualquier interrupción que pueda afectar a toda una región de AWS.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Adjunte uno o varios clústeres de Aurora secundarios. | En la Consola de administración de AWS, seleccione Amazon Aurora. Seleccione el clúster principal, elija Acciones y seleccione Añadir región en la lista desplegable. | Administrador de base de datos |
Seleccione la clase de instancia. | Puede cambiar la clase de instancia del clúster secundario. Sin embargo, le recomendamos mantenerla igual que la clase de instancia del clúster principal. | Administrador de base de datos |
Añada la tercera región. | Repita los pasos de esta épica para añadir un clúster en la tercera región. | Administrador de base de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Elimine el clúster secundario de la base de datos global de Aurora. |
| Administrador de base de datos |
Puede volver a configurar la aplicación para desviar el tráfico de escritura al clúster que acaba de promover. | Cambie el punto de conexión de la aplicación por el del clúster recién promocionado. | Administrador de base de datos |
Detenga la ejecución de cualquier operación de escritura en el clúster no disponible. | Detenga la aplicación y cualquier actividad del lenguaje de manipulación de datos (DML) en el clúster que ha eliminado. | Administrador de base de datos |
Crear una base de datos global de Aurora. | Ahora puede crear una base de datos global de Aurora con el clúster recién promovido como clúster principal. | Administrador de base de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Seleccione el clúster principal que se va a iniciar desde la base de datos global. | En la consola de Amazon Aurora, en la configuración de la base de datos global, elija el clúster principal. | Administrador de base de datos |
Iniciar el clúster. | En la lista desplegable Acciones, seleccione Iniciar. Este proceso puede tardar algún tiempo. Actualice la pantalla para ver el estado o compruebe, en la columna Estado, el estado actual del clúster una vez finalizada la operación. | Administrador de base de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Elimine los clústeres secundarios restantes. | Tras completar el piloto de conmutación por error, elimine los clústeres secundarios de la base de datos global. | Administrador de base de datos |
Elimine el clúster principal. | Eliminar el clúster. | Administrador de base de datos |
Recursos relacionados
