Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Migración de valores CLOB de Oracle a filas individuales en PostgreSQL en AWS
Sai Krishna Namburu y Sindhusha Paturu, Amazon Web Services
Resumen
Este patrón describe cómo dividir valores de objetos grandes (CLOB) de Oracle en filas individuales en Amazon Aurora compatible con PostgreSQL y Amazon Relational Database Service (Amazon RDS) para PostgreSQL. PostgreSQL no admite el tipo de datos CLOB.
Las tablas con particiones de intervalos se identifican en la base de datos de Oracle de origen, y el nombre de la tabla, el tipo de partición, el intervalo de partición y otros metadatos se registran y cargan en la base de datos de destino. Puede cargar datos CLOB de tamaño inferior a 1 GB en tablas de destino como texto mediante AWS Database Migration Service (AWS DMS), o bien puede exportar los datos en formato CSV, cargarlos en un bucket de Amazon Simple Storage Service (Amazon S3) y migrarlos a su base de datos PostgreSQL de destino.
Tras la migración, puede usar el código de PostgreSQL personalizado proporcionado con este patrón para dividir los datos CLOB en filas individuales en función del nuevo identificador de caracteres de línea (CHR(10)) y rellenar la tabla de destino.
Requisitos previos y limitaciones
Requisitos previos
Una tabla de base de datos de Oracle con particiones de intervalos y registros con tipo de datos CLOB.
Una base de datos de Aurora compatible con PostgreSQL o Amazon RDS para PostgreSQL con una estructura de tabla similar a la tabla de origen (las mismas columnas y tipos de datos).
Limitaciones
El valor de CLOB no puede superar 1 GB.
Cada fila de la tabla de destino debe tener un nuevo identificador de caracteres de línea.
Versiones de producto
Oracle 12c
Aurora PostgreSQL 11.6
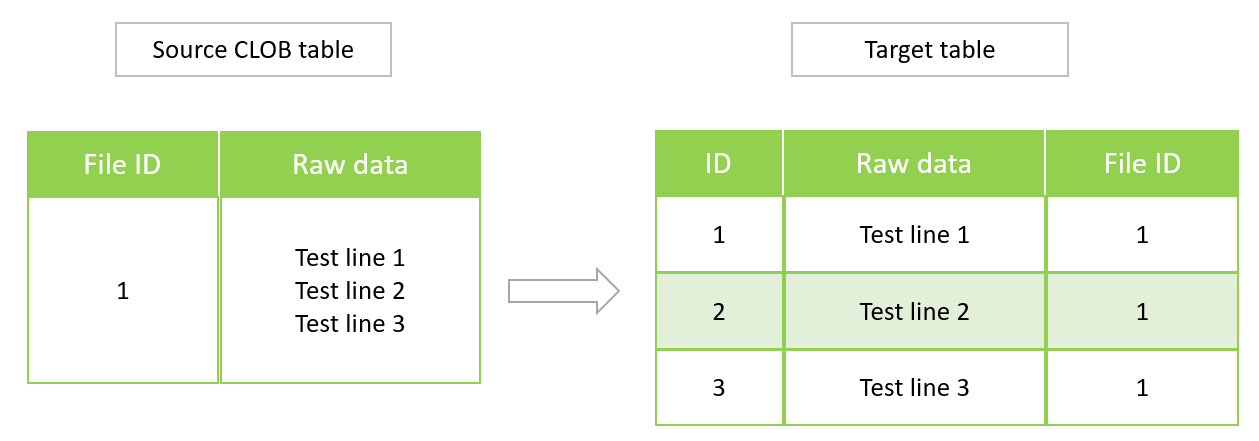
Arquitectura
El siguiente diagrama muestra una tabla de origen de Oracle con datos CLOB, y la tabla PostgreSQL equivalente en Aurora compatible con PostgreSQL versión 11.6.
Herramientas
Servicios de AWS
La edición de Amazon Aurora compatible con PostgreSQL es un motor de base de datos relacional compatible con ACID, completamente administrado que le permite configurar, utilizar y escalar implementaciones de PostgreSQL.
Amazon Relational Database Service (Amazon RDS) para PostgreSQL le ayuda a configurar, utilizar y escalar una base de datos relacional de PostgreSQL en la nube de AWS.
AWS Database Migration Service (AWS DMS) le permite migrar los almacenes de datos a la nube de AWS o entre combinaciones de configuraciones en la nube y en las instalaciones.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que le ayuda a almacenar, proteger y recuperar cualquier cantidad de datos.
Otras herramientas
Puede usar las siguientes herramientas de cliente para conectarse, acceder y gestionar sus bases de datos de Aurora compatible con PostgreSQL y Amazon RDS para PostgreSQL. (Estas herramientas no se usan en este patrón).
pgAdmin
es una herramienta de gestión de código abierto para PostgreSQL. Proporciona una interfaz gráfica que permite crear, mantener y utilizar objetos de bases de datos. DBeaver
es una herramienta de base de datos de código abierto para desarrolladores y administradores de bases de datos. Esta herramienta le permite manipular, supervisar, analizar, administrar y migrar sus datos.
Prácticas recomendadas
Para conocer las prácticas recomendadas para migrar su base de datos de Oracle a PostgreSQL, consulte la publicación del blog de AWS Prácticas recomendadas para migrar una base de datos de Oracle a Amazon RDS PostgreSQL o Amazon Aurora PostgreSQL: consideraciones sobre el proceso de migración y la infraestructura
Para obtener información sobre las prácticas recomendadas para configurar la tarea de AWS DMS para migrar objetos binarios grandes, consulte Migración de objetos binarios grandes (LOBs) en la documentación de AWS DMS.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Analice los datos de CLOB. | En la base de datos de Oracle de origen, analice los datos de CLOB para comprobar si contienen encabezados de columna y así poder determinar el método de carga de los datos en la tabla de destino. Para analizar los datos de entrada, ejecute la siguiente consulta.
| Desarrollador |
Cargue los datos de CLOB en la base de datos de destino. | Migre la tabla que contiene datos de CLOB a una tabla provisional (transitoria) en la base de datos de destino de Aurora o Amazon RDS. Puede usar AWS DMS o cargar los datos en formato de archivo CSV a un bucket de Amazon S3. Para obtener más información sobre el uso de AWS DMS para esta tarea, consulte Uso de una base de datos de Oracle como fuente y Uso de una base de datos PostgreSQL como destino en la documentación de AWS DMS. Para obtener más información sobre el uso de Amazon S3 para esta tarea, consulte Uso de Amazon S3 como destino en la documentación de AWS DMS. | Ingeniero de migraciones, administrador de bases de datos |
Valide la tabla PostgreSQL de destino. | Valide los datos de destino, incluidos los encabezados, comparándolos con los datos de origen. Para ello, ejecute las siguientes consultas en la base de datos de destino.
Compare los resultados con los resultados de las consultas a la base de datos de origen (desde el primer paso). | Desarrollador |
Divida los datos de CLOB en filas independientes. | Ejecute el código PostgreSQL personalizado que se proporciona en la sección Información adicional para dividir los datos CLOB e insertarlos en filas independientes en la tabla PostgreSQL de destino. | Desarrollador |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Valide los datos en la tabla de destino. | Valide los datos insertados en la tabla de destino ejecutando las siguientes consultas.
| Desarrollador |
Recursos relacionados
Tipo de datos CLOB
(documentación de Oracle) Tipos de datos
(documentación de PostgreSQL)
Información adicional
Función de PostgreSQL para dividir datos CLOB
do $$ declare totalstr varchar; str1 varchar; str2 varchar; pos1 integer := 1; pos2 integer ; len integer; begin select rawdata||chr(10) into totalstr from clobdata_pg; len := length(totalstr) ; raise notice 'Total length : %',len; raise notice 'totalstr : %',totalstr; raise notice 'Before while loop'; while pos1 < len loop select position (chr(10) in totalstr) into pos2; raise notice '1st position of new line : %',pos2; str1 := substring (totalstr,pos1,pos2-1); raise notice 'str1 : %',str1; insert into clobdatatarget(data) values (str1); totalstr := substring(totalstr,pos2+1,len); raise notice 'new totalstr :%',totalstr; len := length(totalstr) ; end loop; end $$ LANGUAGE 'plpgsql' ;
Ejemplos de entrada y salida
Puede usar los siguientes ejemplos para probar el código PostgreSQL antes de migrar los datos.
Cree una base de datos de Oracle con tres líneas de entrada.
CREATE TABLE clobdata_or ( id INTEGER GENERATED ALWAYS AS IDENTITY, rawdata clob ); insert into clobdata_or(rawdata) values (to_clob('test line 1') || chr(10) || to_clob('test line 2') || chr(10) || to_clob('test line 3') || chr(10)); COMMIT; SELECT * FROM clobdata_or;
Se mostrarán los siguientes valores.
id | rawdata |
1 | test line 1 test line 2 test line 3 |
Cargue los datos de origen en una tabla transitoria de PostgreSQL (clobdata_pg) para su procesamiento.
SELECT * FROM clobdata_pg; CREATE TEMP TABLE clobdatatarget (id1 SERIAL,data VARCHAR ); <Run the code in the additional information section.> SELECT * FROM clobdatatarget;
Se mostrarán los siguientes valores.
id1 | datos |
1 | Línea de prueba 1 |
2 | Línea de prueba 2 |
3 | Línea de prueba 3 |
