Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Organice una canalización de ETL con validación, transformación y particionamiento mediante AWS Step Functions
Sandip Gangapadhyay, Amazon Web Services
Resumen
Este patrón describe cómo crear un proceso de extracción, transformación y carga (ETL) sin servidor para validar, transformar, comprimir y particionar un conjunto de datos CSV de gran tamaño con el fin de optimizar el rendimiento y los costos. El proceso está organizado AWS Step Functions e incluye funciones de gestión de errores, reintentos automatizados y notificación al usuario.
Cuando se carga un archivo CSV a una carpeta de origen en un bucket de Amazon Simple Storage Service (Amazon S3), el proceso de ETL comienza a ejecutarse. El proceso valida el contenido y el esquema del archivo CSV de origen, transforma el archivo CSV a un formato comprimido de Apache Parquet, particiona el conjunto de datos por año, mes y día y lo almacena en una carpeta independiente para que las herramientas de análisis lo procesen.
El código que automatiza este patrón está disponible en el GitHub repositorio ETL Pipeline with
Requisitos previos y limitaciones
Requisitos previos
Un activo Cuenta de AWS.
AWS Command Line Interface (AWS CLI) instalado y configurado con su Cuenta de AWS, para que pueda crear AWS recursos mediante el despliegue de una AWS CloudFormation pila. Recomendamos usar la AWS CLI versión 2. Para obtener instrucciones, consulte Instalación o actualización a la última versión de AWS CLI en la AWS CLI documentación. Para obtener instrucciones de configuración, consulte los ajustes de configuración y del archivo de credenciales en la AWS CLI documentación.
Un bucket de Amazon S3.
Un conjunto de datos CSV con el esquema correcto. (El repositorio de código
incluido en este patrón proporciona un archivo CSV de muestra con el esquema y tipo de datos correctos para su uso). Un navegador web compatible con. AWS Management Console(Consulte la lista de los navegadores compatibles
). AWS Glue acceso a la consola.
AWS Step Functions acceso a la consola.
Limitaciones
En AWS Step Functions, el límite máximo para conservar los registros del historial es de 90 días. Para obtener más información, consulte las cuotas de servicio de Step Functions en la AWS Step Functions documentación.
Versiones de producto
Python 3.13 para AWS Lambda
AWS Glue versión 4.0
Arquitectura

El flujo de trabajo que se muestra en el diagrama consta de los siguientes pasos de alto nivel:
El usuario carga un archivo CSV en la carpeta de origen de Amazon S3.
Un evento de notificación de Amazon S3 inicia una AWS Lambda función que inicia la máquina de AWS Step Functions estados.
La función de Lambda valida el esquema y el tipo de datos del archivo CSV sin procesar.
En función de los resultados de la validación:
Si la validación del archivo de origen se realiza correctamente, el archivo se mueve a la carpeta transitoria para su posterior procesamiento.
Si el archivo no se valida, se mueve a la carpeta de errores y se envía una notificación de error a través de Amazon Simple Notification Service (Amazon SNS).
Un AWS Glue rastreador crea el esquema del archivo sin procesar a partir de la carpeta del escenario en Amazon S3.
Un AWS Glue trabajo transforma, comprime y particiona el archivo sin procesar en formato Parquet.
El AWS Glue trabajo también mueve el archivo a la carpeta de transformación de Amazon S3.
El AWS Glue rastreador crea el esquema a partir del archivo transformado. El esquema resultante se puede utilizar en cualquier trabajo de análisis. Puede utilizar Amazon Athena para ejecutar consultas ad-hoc.
Si el proceso se completa sin errores, el archivo de esquema se mueve a la carpeta de almacenamiento. Si se encuentra algún error, el archivo se mueve a la carpeta de errores.
Amazon SNS envía una notificación en la que se indica el éxito o el error en función del estado de finalización del proceso.
Todos los AWS recursos utilizados en este patrón no tienen servidor. No es necesario administrar servidores.
Herramientas
Servicios de AWS
AWS Glue
— AWS Glue es un servicio ETL totalmente gestionado que facilita a los clientes la preparación y carga de sus datos para su análisis. AWS Step Functions
— AWS Step Functions es un servicio de organización sin servidor que le permite combinar AWS Lambda funciones y otras Servicios de AWS para crear aplicaciones críticas para la empresa. A través de la consola AWS Step Functions gráfica, puede ver el flujo de trabajo de su aplicación como una serie de pasos basados en eventos. Amazon S3:
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos que ofrece escalabilidad, disponibilidad de datos, seguridad y rendimiento líderes del sector. Amazon SNS
: Amazon Simple Notification Service (Amazon SNS) es un servicio de mensajería de alta disponibilidad, duradero, seguro y totalmente pub/sub gestionado que le permite desvincular microservicios, sistemas distribuidos y aplicaciones sin servidor. AWS Lambda
— AWS Lambda es un servicio informático que permite ejecutar código sin aprovisionar ni administrar servidores. AWS Lambda ejecuta el código solo cuando es necesario y se escala automáticamente, desde unas pocas solicitudes por día hasta miles por segundo.
Código
El código de este patrón está disponible en el GitHub AWS Step Functions repositorio ETL Pipeline with
template.yml— AWS CloudFormation plantilla con la que crear la canalización de ETL AWS Step Functions.parameter.json– Contiene todos los parámetros y valores de los parámetros. Actualice este archivo para cambiar los valores de los parámetros, tal y como se describe en la sección Épica.myLayer/pythoncarpeta: contiene los paquetes de Python necesarios para crear la AWS Lambda capa requerida para este proyecto.Carpeta
lambda– Contiene las siguientes funciones de Lambda:move_file.py– Mueve el conjunto de datos de origen a la carpeta de almacenamiento, transformación o errores.check_crawler.py— Comprueba el estado del AWS Glue rastreador tantas veces como lo haya configurado la variable deRETRYLIMITentorno antes de enviar un mensaje de error.start_crawler.py— Inicia el AWS Glue rastreador.start_step_function.py— Empieza AWS Step Functions.start_codebuild.py— Inicia el AWS CodeBuild proyecto.validation.py– Valida el conjunto de datos sin procesar de entrada.s3object.py— Crea la estructura de directorios necesaria dentro del bucket de Amazon S3.notification.py– Envía notificaciones de éxito o error al final del proceso.
Para usar el código de muestra, siga las instrucciones en la sección Epics .
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Clone el repositorio de código de muestra. |
| Desarrollador |
Actualice los valores de los parámetros. | En la copia local del repositorio, edite el archivo
| Desarrollador |
Cargue el código fuente en el bucket de Amazon S3. | Antes de implementar la AWS CloudFormation plantilla que automatiza la canalización de ETL, debe empaquetar los archivos fuente de la plantilla y subirlos a un bucket de Amazon S3. Para ello, ejecute el siguiente AWS CLI comando con su perfil preconfigurado:
donde:
| Desarrollador |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Implemente la CloudFormation plantilla. | Para implementar la AWS CloudFormation plantilla, ejecute el siguiente AWS CLI comando:
donde:
| Desarrollador |
Compruebe el progreso. | En la AWS CloudFormation consola | Desarrollador |
Anote el nombre AWS Glue de la base de datos. | La pestaña Salidas de la pila muestra el nombre de la AWS Glue base de datos. El nombre de la clave es | Desarrollador |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Inicie el proceso de ETL. |
| Desarrollador |
Compruebe el conjunto de datos particionado. | Cuando se complete el proceso de ETL, compruebe que el conjunto de datos particionado esté disponible en la carpeta de transformación de Amazon S3 ( | Desarrollador |
Comprueba la base de AWS Glue datos particionada. |
| Desarrollador |
Ejecutar consultas. | (Opcional) Use Amazon Athena para ejecutar consultas ad hoc en la base de datos particionada y transformada. Para obtener instrucciones, consulte Ejecutar consultas SQL en Amazon Athena en la AWS documentación. | Análisis de la base de datos |
Solución de problemas
| Problema | Solución |
|---|---|
AWS Identity and Access Management (IAM) para el AWS Glue trabajo y el rastreador | Si sigue personalizando el AWS Glue trabajo o el rastreador, asegúrese de conceder los permisos de IAM adecuados en la función de IAM utilizada por el AWS Glue trabajo o de proporcionarle permisos de datos. AWS Lake Formation Para obtener más información, consulte la Documentación de AWS. |
Recursos relacionados
Servicio de AWS documentación
Información adicional
El siguiente diagrama muestra el AWS Step Functions flujo de trabajo para una canalización de ETL exitosa, desde el panel del AWS Step Functions Inspector.
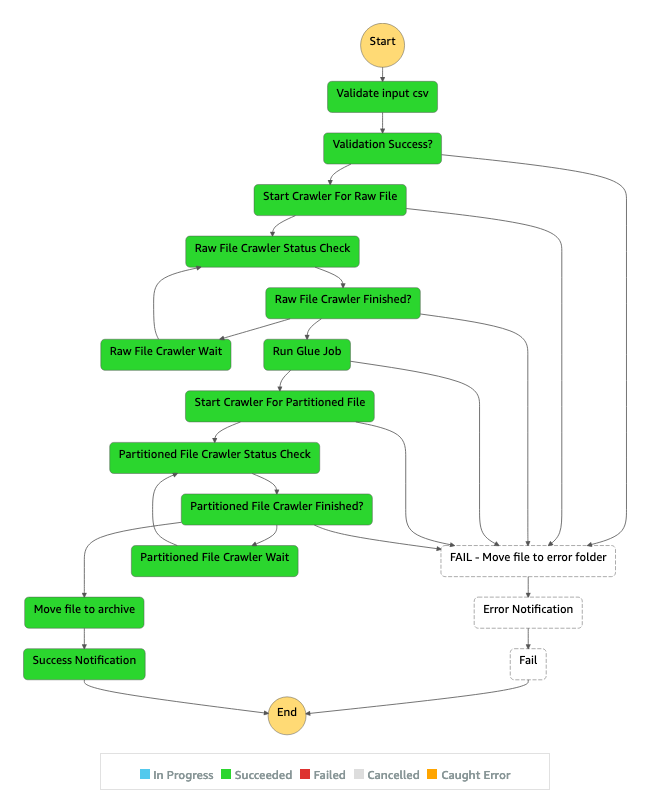
El siguiente diagrama muestra el AWS Step Functions flujo de trabajo de una canalización de ETL que falla debido a un error de validación de entrada, desde el panel Step Functions Inspector.

