Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Realizar análisis avanzados mediante Amazon Redshift ML
Po Hong y Chyanna Antonio, Amazon Web Services
Resumen
En la nube de Amazon Web Services (AWS), puede utilizar el machine learning de Amazon Redshift (Amazon Redshift ML) para realizar análisis de ML de los datos almacenados en un clúster de Amazon Redshift o en Amazon Simple Storage Service (Amazon S3). Amazon Redshift ML admite el aprendizaje supervisado, que se suele utilizar para análisis avanzados. Los casos de uso de Amazon Redshift ML incluyen la previsión de ingresos, la detección de fraudes con tarjetas de crédito y las predicciones del valor de por vida del cliente (CLV) o la pérdida de clientes.
Amazon Redshift ML facilita a los usuarios de bases de datos crear, entrenar e implementar modelos de machine learning mediante comandos SQL estándar. Amazon Redshift ML utiliza Amazon SageMaker Autopilot para entrenar y ajustar automáticamente los mejores modelos de aprendizaje automático para su clasificación o regresión en función de sus datos, sin perder el control y la visibilidad.
Todas las interacciones entre Amazon Redshift, Amazon S3 y Amazon SageMaker se resumen y automatizan. Una vez entrenado e implementado el modelo de ML, pasa a estar disponible como función definida por el usuario (UDF) en Amazon Redshift y se puede usar en consultas de SQL.
Este patrón complementa el tutorial Crear, entrenar e implementar modelos de aprendizaje automático en Amazon Redshift mediante SQL con Amazon Redshift ML
Requisitos previos y limitaciones
Requisitos previos
Una cuenta de AWS activa
Datos existentes en una tabla de Amazon Redshift
Habilidades
Familiaridad con los términos y conceptos que utiliza Amazon Redshift ML, incluidos machine learning, entrenamiento y predicción.. Para obtener más información, consulte Training ML models (Entrenar modelos de machine learning) en la documentación de Amazon Machine Learning (Amazon ML).
Experiencia en la configuración de usuarios, la administración de acceso y la sintaxis SQL estándar de Amazon Redshift. Para obtener más información, consulte Introducción a Amazon Redshift en la documentación de Amazon Redshift.
Conocimiento y experiencia en Amazon S3 y AWS Identity and Access Management (IAM).
La experiencia en ejecución de comandos de la interfaz de la línea de comandos de AWS (AWS CLI) también es beneficiosa, pero no obligatoria.
Limitaciones
El clúster de Amazon Redshift y el bucket de Amazon S3 deben estar en la misma región de AWS.
El enfoque de este patrón solo admite modelos de aprendizaje supervisado, como la regresión, la clasificación binaria y la clasificación multiclase.
Arquitectura
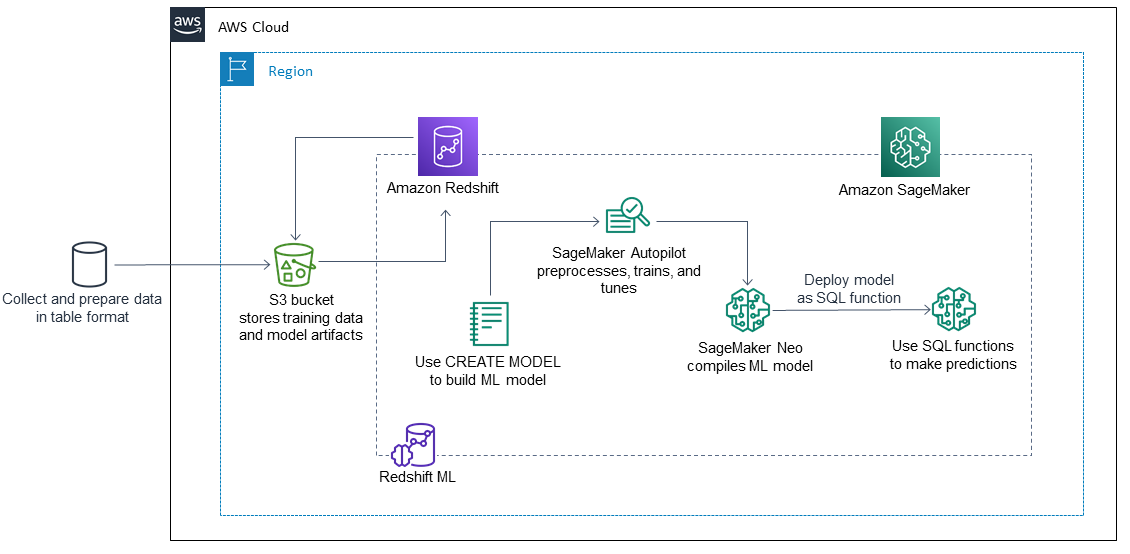
En los siguientes pasos se explica cómo funciona Amazon Redshift ML SageMaker para crear, entrenar e implementar un modelo de aprendizaje automático:
Amazon Redshift exporta los datos de entrenamiento a un bucket de S3.
SageMaker El piloto automático preprocesa automáticamente los datos de entrenamiento.
Una vez invocada la
CREATE MODELdeclaración, Amazon Redshift ML la utiliza SageMaker para la formación.SageMaker Autopilot busca y recomienda el algoritmo de aprendizaje automático y los hiperparámetros óptimos que optimizan las métricas de evaluación.
Amazon Redshift ML registra el modelo de ML de salida como una función SQL en el clúster de Amazon Redshift.
La función del modelo ML se puede utilizar en una instrucción SQL.
Pila de tecnología
Amazon Redshift
SageMaker
Amazon S3
Herramientas
Amazon Redshift: Amazon Redshift es un servicio de almacenamiento de datos completamente administrado, de nivel empresarial y de escala de petabytes.
Amazon Redshift ML: Amazon Redshift machine learning (Amazon Redshift ML) es un servicio robusto basado en la nube que facilita el uso de la tecnología de machine learning a los analistas y científicos de datos con cualquier nivel de habilidades.
Amazon S3: Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento para Internet.
Amazon SageMaker: SageMaker es un servicio de aprendizaje automático totalmente gestionado.
Amazon SageMaker Autopilot: SageMaker Autopilot es un conjunto de funciones que automatiza las tareas clave de un proceso de aprendizaje automático (AutoML).
Código
Puede crear un modelo de ML supervisado en Amazon Redshift mediante el siguiente código:
"CREATE MODEL customer_churn_auto_model FROM (SELECT state, account_length, area_code, total_charge/account_length AS average_daily_spend, cust_serv_calls/account_length AS average_daily_cases, churn FROM customer_activity WHERE record_date < '2020-01-01' ) TARGET churn FUNCTION ml_fn_customer_churn_auto IAM_ROLE 'arn:aws:iam::XXXXXXXXXXXX:role/Redshift-ML' SETTINGS ( S3_BUCKET 'your-bucket' );")
nota
El SELECT estado puede hacer referencia a las tablas normales de Amazon Redshift, a las tablas externas de Amazon Redshift Spectrum o a ambas.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Prepare un conjunto de datos para entrenamiento y prueba. | Inicie sesión en la consola de administración de AWS y abra la SageMaker consola de Amazon. Siga las instrucciones del tutorial Build, train, and deploy a machine learning model notaLe recomendamos que mezcle y divida el conjunto de datos sin procesar en un conjunto de entrenamiento para el entrenamiento del modelo (70 por ciento) y un conjunto de pruebas para la evaluación del desempeño del modelo (30 por ciento). | Científico de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree y configure un clúster de Amazon Redshift. | En la consola de Amazon Redshift, cree un clúster de acuerdo con sus requisitos. Para obtener más información, consulte Create a cluster (Crear un clúster) en la documentación de Amazon Redshift. importanteLos clústeres de Amazon Redshift se deben crear con la pista de | Administrador de base de datos, arquitecto de la nube |
Cree un bucket de S3 para almacenar los datos de entrenamiento y los artefactos del modelo. | En la consola de Amazon S3, cree un bucket de S3 para los datos de entrenamiento y prueba. Para obtener más información acerca de la creación de un bucket de S3, consulte Creación de un bucket de S3 en Inicios rápidos de AWS. importanteAsegúrese de que el clúster de Amazon Redshift y el bucket de S3 estén en la misma región. | Administrador de base de datos, arquitecto de la nube |
Cree y asocie una política de IAM al clúster de Amazon Redshift. | Cree una política de IAM para permitir que el clúster de Amazon Redshift SageMaker acceda a Amazon S3. Para las instrucciones y los pasos a seguir, consulte Cluster setup for using Amazon Redshift ML (Configuración del clúster para usar Amazon Redshift ML) en la documentación de Amazon Redshift. | Administrador de base de datos, arquitecto de la nube |
Permita que los usuarios y grupos de Amazon Redshift accedan a esquemas y tablas. | Otorgue permisos para permitir que los usuarios y grupos de Amazon Redshift accedan a tablas y esquemas internos y externos. Para ver los pasos e instrucciones, consulte Managing permissions and ownership (Administrar los permisos y la propiedad) en la documentación de Amazon Redshift. | Administrador de base de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree y entrene el modelo de ML en Amazon Redshift. | Cree y entrene el modelo de ML en Amazon Redshift ML. Para obtener más información, consulte la instrucción | Desarrollador, científico de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Realice una inferencia mediante la función del modelo de ML generado. | Para obtener más información sobre cómo realizar inferencias mediante la función del modelo de ML generado, consulte Prediction (Predicción) en la documentación de Amazon Redshift. | Científico de datos, usuario de inteligencia empresarial |
Recursos relacionados
Preparación de un conjunto de datos para entrenamiento y prueba
Preparación y configuración de la pila de tecnología
Choosing Amazon Redshift cluster maintenance tracks (Seleccionar las pistas de mantenimiento de clústeres de Amazon Redshift)
Creating an S3 bucket (Crear un bucket de S3)
Setting up an Amazon Redshift cluster for using Amazon Redshift ML (Configurar un clúster de Amazon Redshift para utilizar Amazon Redshift ML)
Managing permissions and ownership in Amazon Redshift (Administrar permisos y propiedad en Amazon Redshift)
Creación y entrenamiento del modelo de ML en Amazon Redshift
CREATE MODEL statement in Amazon Redshift (La instrucción CREATE MODEL en Amazon Redshift)
Cómo realizar inferencias y predicciones por lotes en Amazon Redshift)
Prediction in Amazon Redshift (Predicción en Amazon Redshift)
Otros recursos
Getting started with Amazon Redshift ML (Introducción a Amazon Redshift ML)
Creating, training, and deploying ML models in Amazon Redshift using SQL with Amazon Redshift ML
(Crear, entrenar e implementar modelos de ML en Amazon Redshift mediante SQL con Amazon Redshift ML) Amazon Redshift partners
(Socios de Amazon Redshift.) AWS machine learning competency partners
(Socios con competencias en machine learning de AWS)
