Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Caso de uso: predicción de los resultados de los pacientes y las tasas de reingreso
Los análisis predictivos basados en la IA ofrecen beneficios adicionales al pronosticar los resultados de los pacientes y permitir planes de tratamiento personalizados. Esto puede mejorar la satisfacción de los pacientes y los resultados de salud. Al integrar estas capacidades de IA con Amazon Bedrock y otras tecnologías, los proveedores de atención médica pueden lograr importantes aumentos de productividad, reducir los costos y mejorar la calidad general de la atención al paciente.
Puede almacenar datos médicos, como los historiales de los pacientes, las notas clínicas, los medicamentos y los tratamientos, en un gráfico de conocimiento
Esta solución le ayuda a predecir la probabilidad de volver a ingresar. Estas predicciones pueden mejorar los resultados de los pacientes y reducir los costos de atención médica. Esta solución también puede ayudar a los médicos y administradores de los hospitales a centrar su atención en los pacientes con un mayor riesgo de reingreso. También les ayuda a iniciar intervenciones proactivas con esos pacientes mediante alertas, autoservicio y acciones basadas en datos.
Información general de la solución
Esta solución utiliza un marco de generación aumentada (RAG) de recuperación múltiple para analizar los datos de los pacientes. Predice la probabilidad de reingreso hospitalario de pacientes individuales y le ayuda a calcular una puntuación de propensión al reingreso a nivel hospitalario. Esta solución integra las siguientes funciones:
-
Gráfico de conocimiento: almacena datos estructurados y cronológicos de los pacientes, como las visitas al hospital, los reingresos anteriores, los síntomas, los resultados de laboratorio, los tratamientos prescritos y el historial de adherencia a la medicación
-
Base de datos vectorial: almacena datos clínicos no estructurados, como resúmenes de alta, notas del médico y registros de consultas no atendidas o de efectos secundarios notificados por los medicamentos
-
LLM perfeccionado: utiliza tanto datos estructurados del gráfico de conocimiento como datos no estructurados de la base de datos vectorial para generar inferencias sobre el comportamiento del paciente, la adherencia al tratamiento y la probabilidad de reingreso
Los modelos de puntuación de riesgo cuantifican las inferencias del LLM en puntuaciones numéricas. Puede sumar las puntuaciones en una puntuación de propensión a la readmisión a nivel hospitalario. Esta puntuación define la exposición al riesgo de cada paciente y puede calcularla periódicamente o según sea necesario. Todas las inferencias y puntuaciones de riesgo se indexan y almacenan en Amazon OpenSearch Service para que los administradores de atención y los médicos puedan recuperarlas. Al integrar un agente de IA conversacional en esta base de datos vectorial, los médicos y los administradores de atención pueden extraer información sin problemas a nivel de paciente individual, de todo el centro o por especialidad médica. También puede configurar alertas automatizadas basadas en las puntuaciones de riesgo, lo que fomenta las intervenciones proactivas.
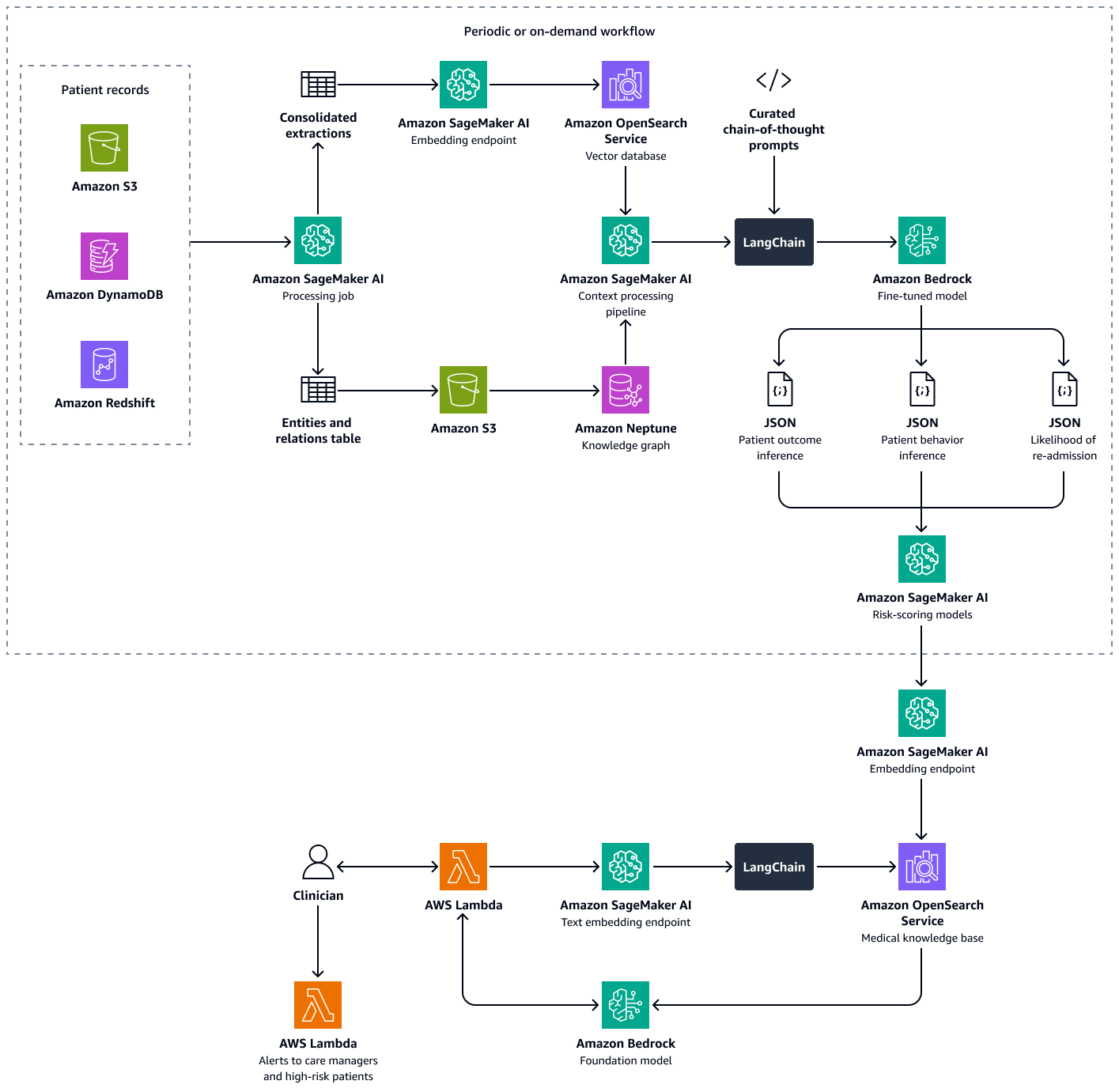
La creación de esta solución consta de los siguientes pasos:
Paso 1: Predecir los resultados de los pacientes mediante un gráfico de conocimientos médicos
En Amazon Neptune, puede usar un gráfico de conocimiento para almacenar información temporal sobre las visitas de los pacientes y los resultados a lo largo del tiempo. La forma más eficaz de crear y almacenar un gráfico de conocimiento es utilizar un modelo gráfico y una base de datos de gráficos. Las bases de datos de gráficos están diseñadas específicamente para almacenar y navegar por las relaciones. Las bases de datos de gráficos facilitan el modelado y la administración de datos altamente conectados y cuentan con esquemas flexibles.
El gráfico de conocimiento le ayuda a realizar análisis de series temporales. Los siguientes son los elementos clave de la base de datos de gráficos que se utilizan para la predicción temporal de los resultados de los pacientes:
-
Datos históricos: diagnósticos previos, medicación continuada, medicamentos utilizados anteriormente y resultados de laboratorio del paciente
-
Visitas de los pacientes (cronológicas): fechas de las visitas, síntomas, alergias observadas, notas clínicas, diagnósticos, procedimientos, tratamientos, medicamentos recetados y resultados de laboratorio
-
Síntomas y parámetros clínicos: información clínica y basada en los síntomas, incluida la gravedad, los patrones de progresión y la respuesta del paciente a los medicamentos
Puede utilizar la información del gráfico de conocimientos médicos para afinar un máster en Amazon Bedrock, como Llama 3. El LLM se ajusta con precisión con datos secuenciales del paciente sobre la respuesta del paciente a un conjunto de medicamentos o tratamientos a lo largo del tiempo. Utilice un conjunto de datos etiquetado que clasifique un conjunto de medicamentos o tratamientos y los datos de interacción entre el paciente y la clínica en categorías predefinidas que indiquen el estado de salud del paciente. Algunos ejemplos de estas categorías son el deterioro de la salud, la mejora o el progreso estable. Cuando el médico introduce un nuevo contexto sobre el paciente y sus síntomas, el LLM, bien ajustado, puede utilizar los patrones del conjunto de datos de entrenamiento para predecir el posible resultado del paciente.
La siguiente imagen muestra los pasos secuenciales necesarios para afinar un LLM en Amazon Bedrock mediante un conjunto de datos de formación específico para el sector sanitario. Estos datos pueden incluir las afecciones médicas de los pacientes y las respuestas a los tratamientos a lo largo del tiempo. Este conjunto de datos de entrenamiento ayudaría al modelo a realizar predicciones generalizadas sobre los resultados de los pacientes.
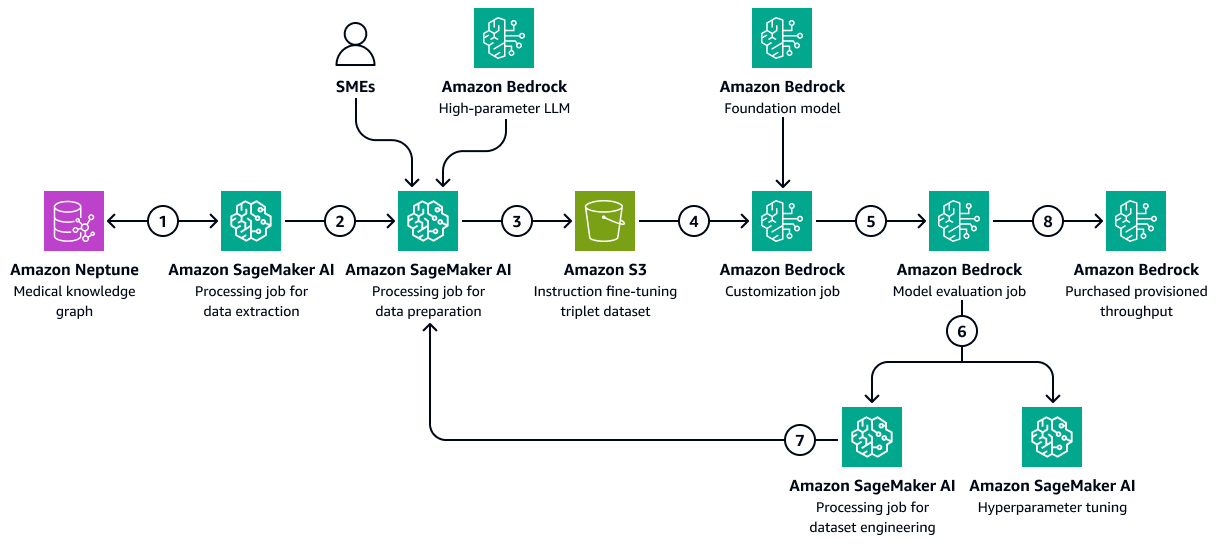
En el diagrama, se muestra el siguiente flujo de trabajo:
-
El trabajo de extracción de datos de Amazon SageMaker AI consulta el gráfico de conocimiento para recuperar datos cronológicos sobre las respuestas de los diferentes pacientes a un conjunto de medicamentos o tratamientos a lo largo del tiempo.
-
El trabajo de preparación de datos de SageMaker IA integra un LLM de Amazon Bedrock y aportaciones de expertos en la materia ()SMEs. El trabajo clasifica los datos recuperados del gráfico de conocimiento en categorías predefinidas (como el deterioro de la salud, la mejora o el progreso estable) que indican el estado de salud de cada paciente.
-
El trabajo crea un conjunto de datos preciso que incluye la información extraída del gráfico de conocimiento, las chain-of-thought indicaciones y la categoría de resultados de los pacientes. Carga este conjunto de datos de entrenamiento en un bucket de Amazon S3.
-
Un trabajo de personalización de Amazon Bedrock utiliza este conjunto de datos de entrenamiento para ajustar un LLM.
-
El trabajo de personalización de Amazon Bedrock integra el modelo fundamental de Amazon Bedrock preferido en el entorno de formación. Comienza el trabajo de ajuste y utiliza el conjunto de datos de entrenamiento y los hiperparámetros de entrenamiento que usted configure.
-
Un trabajo de evaluación de Amazon Bedrock evalúa el modelo ajustado mediante un marco de evaluación de modelos prediseñado.
-
Si es necesario mejorar el modelo, el trabajo de formación se vuelve a ejecutar con más datos tras una cuidadosa consideración del conjunto de datos de formación. Si el modelo no demuestra una mejora gradual del rendimiento, considere también la posibilidad de modificar los hiperparámetros del entrenamiento.
-
Una vez que la evaluación del modelo cumpla con los estándares definidos por las partes interesadas de la empresa, debe alojar el modelo ajustado según el rendimiento aprovisionado de Amazon Bedrock.
Paso 2: Predecir el comportamiento del paciente con respecto a los medicamentos o tratamientos recetados
Tune-Tuned LLMs puede procesar notas clínicas, resúmenes de alta y otros documentos específicos del paciente a partir del gráfico temporal de conocimientos médicos. Pueden evaluar si es probable que el paciente siga los medicamentos o tratamientos recetados.
Este paso utiliza el gráfico de conocimiento creado enPaso 1: Predecir los resultados de los pacientes mediante un gráfico de conocimientos médicos. El gráfico de conocimiento contiene datos del perfil del paciente, incluido el historial de adherencia del paciente como nodo. También incluye los casos de falta de adherencia a los medicamentos o tratamientos, los efectos secundarios de los medicamentos, la falta de acceso a los medicamentos o los obstáculos a su costo, o los regímenes de dosificación complejos, como atributos de dichos nodos.
Fine-Tuned LLMs puede consumir datos de entrega de recetas anteriores del gráfico de conocimientos médicos y resúmenes descriptivos de las notas clínicas de una base de datos vectorial de Amazon OpenSearch Service. Estas notas clínicas pueden mencionar la falta frecuente de citas o el incumplimiento de los tratamientos. El LLM puede usar estas notas para predecir la probabilidad de una futura falta de adhesión.
-
Prepare los datos de entrada de la siguiente manera:
-
Datos estructurados: extraiga los datos recientes de los pacientes, como las tres últimas visitas y los resultados del laboratorio, del gráfico de conocimientos médicos.
-
Datos no estructurados: recupera las notas clínicas recientes de la base de datos vectorial OpenSearch de Amazon Service.
-
-
Cree un mensaje de entrada que incluya el historial del paciente y el contexto actual. El siguiente es un ejemplo de mensaje:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, adherence patterns, and clinical context to predict the **likelihood of future non-adherence** to prescribed medications or treatments. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Medical Conditions:** {medical_conditions} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Visit Dates & Symptoms:** {visit_dates_symptoms} - **Diagnoses & Procedures:** {diagnoses_procedures} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} - **Side Effects Experienced:** {side_effects} - **Barriers to Adherence (e.g., Cost, Access, Dosing Complexity):** {barriers} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} ### **Let's think Step-by-Step to predict the patient behaviour** 1. You should first analyze past adherence trends and patterns of non-adherence. 2. Identify potential barriers, such as financial constraints, medication side effects, or complex dosing regimens. 3. Thoroughly examine clinical notes and documented patient behaviors that may hint at non-adherence. 4. Correlate adherence history with prescribed treatments and patient conditions. 5. Finally predict the likelihood of non-adherence based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_non_adherence": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Pase el mensaje al LLM ajustado con precisión. El LLM procesa el mensaje y predice el resultado. El siguiente es un ejemplo de respuesta del LLM:
{ "patient_id": "P12345", "likelihood_of_non_adherence": "high", "reasoning": "The patient has a history of missed appointments, has reported side effects to previous medications. Additionally, clinical notes indicate difficulty following complex dosing schedules." } -
Analice la respuesta del modelo para extraer la categoría de resultado prevista. Por ejemplo, la categoría de la respuesta de ejemplo del paso anterior podría ser una alta probabilidad de falta de adherencia.
-
(Opcional) Utilice registros modelo o métodos adicionales para asignar puntuaciones de confianza. Los logits son las probabilidades no normalizadas de que el elemento pertenezca a una determinada clase o categoría.
Paso 3: Predecir la probabilidad de reingreso del paciente
Los reingresos hospitalarios son motivo de gran preocupación debido al alto coste de la administración de la asistencia sanitaria y a su impacto en el bienestar del paciente. Calcular las tasas de reingreso hospitalario es una forma de medir la calidad de la atención al paciente y el desempeño de un proveedor de atención médica.
Para calcular la tasa de reingresos, ha definido un indicador, como una tasa de reingresos a 7 días. Este indicador es el porcentaje de pacientes ingresados que regresan al hospital para una visita no planificada dentro de los siete días posteriores al alta. Para predecir la probabilidad de reingreso de un paciente, un LLM ajustado puede consumir datos temporales del gráfico de conocimientos médicos en el que se creó. Paso 1: Predecir los resultados de los pacientes mediante un gráfico de conocimientos médicos Este gráfico de conocimiento mantiene registros cronológicos de los encuentros con los pacientes, los procedimientos, los medicamentos y los síntomas. Estos registros de datos contienen lo siguiente:
-
Tiempo transcurrido desde la última vez que el paciente fue dado de alta
-
La respuesta del paciente a los tratamientos y medicamentos anteriores
-
La progresión de los síntomas o afecciones a lo largo del tiempo
Puede procesar estas series temporales de eventos para predecir la probabilidad de reingreso de un paciente mediante un sistema seleccionado. El indicador imparte la lógica de predicción al LLM ajustado con precisión.
-
Prepare los datos de entrada de la siguiente manera:
-
Historial de adherencia: extraiga las fechas de recogida de los medicamentos, las frecuencias de reabastecimiento de los medicamentos, los detalles del diagnóstico y del medicamento, el historial médico cronológico y otra información del gráfico de conocimientos médicos.
-
Indicadores de comportamiento: recupere e incluya notas clínicas sobre las consultas faltantes y los efectos secundarios informados por los pacientes.
-
-
Cree un mensaje de entrada que incluya el historial de adherencia y los indicadores de comportamiento. El siguiente es un ejemplo de mensaje:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, clinical events, and adherence patterns to predict the **likelihood of hospital readmission** within the next few days. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Primary Diagnoses:** {diagnoses} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Recent Hospital Encounters:** {encounters} - **Time Since Last Discharge:** {time_since_last_discharge} - **Previous Readmissions:** {past_readmissions} - **Recent Lab Results & Vital Signs:** {recent_lab_results} - **Procedures Performed:** {procedures_performed} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} - **Patient-Reported Side Effects & Complications:** {side_effects} ### **Reasoning Process – You have to analyze this use case step-by-step.** 1. First assess **time since last discharge** and whether recent hospital encounters suggest a pattern of frequent readmissions. 2. Second examine **recent lab results, vital signs, and procedures performed** to identify clinical deterioration. 3. Third analyze **adherence history**, checking if past non-adherence to medications or treatments correlates with readmissions. 4. Then identify **missed appointments, self-reported side effects, or symptoms worsening** from clinical notes. 5. Finally predict the **likelihood of readmission** based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_readmission": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Pase el mensaje al LLM ajustado con precisión. El LLM procesa el aviso y predice la probabilidad y los motivos de la readmisión. El siguiente es un ejemplo de respuesta del LLM:
{ "patient_id": "P67890", "likelihood_of_readmission": "high", "reasoning": "The patient was discharged only 5 days ago, has a history of more than two readmissions to hospitals where the patient received treatment. Recent lab results indicate abnormal kidney function and high liver enzymes. These factors suggest a medium risk of readmission." } -
Clasifique la predicción en una escala estandarizada, como baja, media o alta.
-
Revise el razonamiento proporcionado por el LLM e identifique los factores clave que contribuyen a la predicción.
-
Asigne los resultados cualitativos a las puntuaciones cuantitativas. Por ejemplo, una probabilidad muy alta podría ser igual a 0,9.
-
Utilice conjuntos de datos de validación para calibrar los resultados del modelo con respecto a las tasas reales de readmisión.
Paso 4: Calcular la puntuación de propensión al reingreso hospitalario
A continuación, se calcula la puntuación de propensión al reingreso hospitalario por paciente. Esta puntuación refleja el impacto neto de los tres análisis realizados en los pasos anteriores: los posibles resultados de los pacientes, el comportamiento de los pacientes con respecto a los medicamentos y los tratamientos y la probabilidad de reingreso del paciente. Al sumar la puntuación de propensión al reingreso a nivel del paciente al nivel de la especialidad y, luego, al nivel hospitalario, puede obtener información para los médicos, los directores de atención y los administradores. La puntuación de propensión al reingreso hospitalario le ayuda a evaluar el desempeño general por centro, especialidad o afección. Luego, puede usar esta puntuación para implementar intervenciones proactivas.
-
Asigne ponderaciones a cada uno de los diferentes factores (predicción del resultado, probabilidad de adherencia, readmisión). Los siguientes son ejemplos de pesos:
-
Peso de predicción del resultado: 0,4
-
Peso de predicción de adherencia: 0,3
-
Peso de la probabilidad de readmisión: 0,3
-
-
Utilice el siguiente cálculo para calcular la puntuación compuesta:
ReadadmissionPropensityScore= (OutcomeScore×OutcomeWeight) + (AdherenceScore×AdherenceWeight) + (ReadmissionLikelihoodScore×ReadmissionLikelihoodWeight) -
Asegúrese de que todas las puntuaciones individuales estén en la misma escala, por ejemplo, de 0 a 1.
-
Defina los umbrales de acción. Por ejemplo, las puntuaciones superiores a 0,7 inician las alertas.
Basándose en los análisis anteriores y en la puntuación de propensión al reingreso de un paciente, los médicos o los administradores de atención pueden configurar alertas para monitorear a sus pacientes individuales en función de la puntuación calculada. Si está por encima de un umbral predefinido, se les notifica cuando se alcanza ese umbral. Esto ayuda a los administradores de atención a ser proactivos en lugar de reactivos a la hora de crear planes de atención de alta para sus pacientes. Guarda las puntuaciones de los resultados, el comportamiento y la propensión al reingreso de los pacientes de forma indexada en una base de datos vectorial de Amazon OpenSearch Service para que los administradores de atención puedan recuperarlas sin problemas mediante un agente de IA conversacional.
El siguiente diagrama muestra el flujo de trabajo de un agente de inteligencia artificial conversacional que un médico o un administrador de atención puede utilizar para obtener información sobre los resultados de los pacientes, el comportamiento esperado y la propensión a volver a ser ingresados. Los usuarios pueden obtener información a nivel de paciente, departamento o hospital. El agente de IA recupera estos datos, que se almacenan de forma indexada en una base de datos vectorial de Amazon OpenSearch Service. El agente utiliza la consulta para recuperar los datos relevantes y proporciona respuestas personalizadas, incluidas las acciones sugeridas para los pacientes que corren un alto riesgo de volver a ser admitidos. Según el nivel de riesgo, el agente también puede configurar recordatorios para los pacientes y los cuidadores.
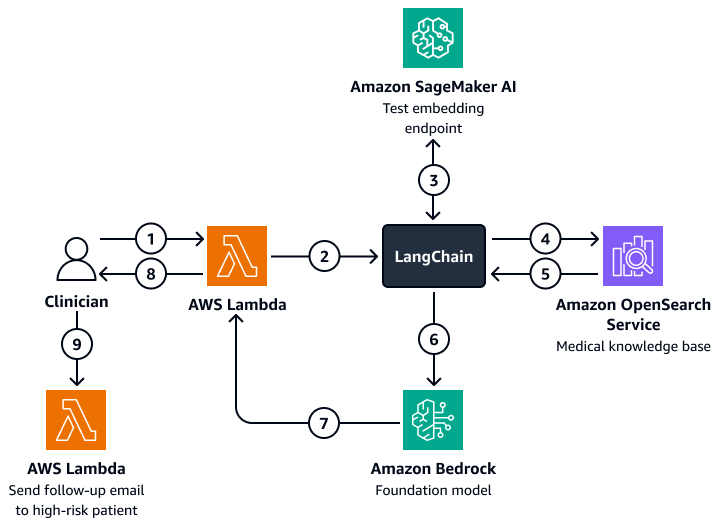
En el diagrama, se muestra el siguiente flujo de trabajo:
-
El médico le hace una pregunta a un agente de IA conversacional, que alberga una función. AWS Lambda
-
La función Lambda inicia un LangChain agente.
-
La LangChain el agente envía la pregunta del usuario a un punto final de incrustación de texto de Amazon SageMaker AI. El punto final incorpora la pregunta.
-
La LangChain el agente pasa la pregunta incrustada a una base de conocimientos médicos en Amazon OpenSearch Service.
-
Amazon OpenSearch Service devuelve la información específica que es más relevante para la consulta del usuario al LangChain agente.
-
La LangChain los agentes envían la consulta y el contexto recuperado de la base de conocimientos a un modelo básico de Amazon Bedrock.
-
El modelo básico de Amazon Bedrock genera una respuesta y la envía a la función Lambda.
-
La función Lambda devuelve la respuesta al médico.
-
El médico inicia una función Lambda que envía un correo electrónico de seguimiento a un paciente que tiene un alto riesgo de reingreso.
Alineación con el marco de AWS Well-Architected
-
Excelencia operativa: la solución es un sistema automatizado y desacoplado que utiliza Amazon Bedrock y proporciona alertas en AWS Lambda tiempo real.
-
Seguridad: esta solución está diseñada para cumplir con las normas sanitarias, como la HIPAA. También puede implementar el cifrado, un control de acceso detallado y las barandillas Amazon Bedrock para ayudar a proteger los datos de los pacientes.
-
Fiabilidad: la arquitectura utiliza sistemas tolerantes a fallos y sin servidores. Servicios de AWS
-
Eficiencia del rendimiento: Amazon OpenSearch Service y los productos afinados LLMs pueden proporcionar predicciones rápidas y precisas.
-
Optimización de costos: las tecnologías y los pay-per-inference modelos sin servidor ayudan a minimizar los costos. Si bien el uso de un LLM ajustado puede generar cargos adicionales, el modelo utiliza un enfoque RAG que reduce los datos y el tiempo computacional necesarios para el proceso de ajuste.
-
Sostenibilidad: la arquitectura minimiza el consumo de recursos mediante el uso de una infraestructura sin servidores. También es compatible con operaciones de atención médica eficientes y escalables.
