Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Arquitectura
El siguiente diagrama muestra la arquitectura de la solución descrita en esta guía. Un AWS Glue trabajo lee los datos de un depósito de Amazon Simple Storage Service (Amazon S3), que es un servicio de almacenamiento de objetos basado en la nube que le ayuda a almacenar, proteger y recuperar datos. Puede iniciar el AWS Glue Spark SQL trabajo a través de AWS Management Console, AWS Command Line Interface (AWS CLI) o la AWS Glue API. El AWS Glue Spark SQL job procesa los datos sin procesar en un depósito de Amazon S3 y, a continuación, almacena los datos procesados en un depósito diferente.
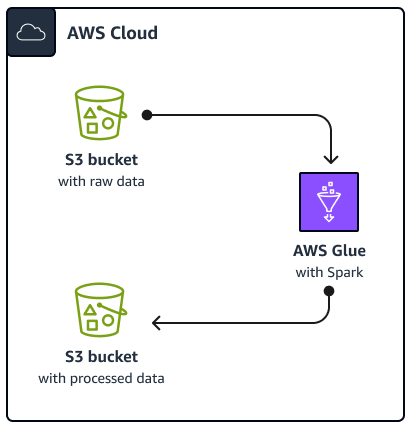
A modo de ejemplo, en esta guía se describe un procedimiento básico AWS GlueSpark SQL trabajo, que está escrito en Python y Spark SQL (PySpark). Este AWS Glue trabajo se utiliza para demostrar las mejores prácticas para Spark SQL afinación. Si bien esta guía se centra en AWS Glue, las mejores prácticas de esta guía también se aplican a Amazon EMR Spark SQL puestos de trabajo.
El siguiente diagrama muestra el ciclo de vida de un Spark SQL consulta. La Spark SQL Catalyst Optimizer genera un plan de consultas. Un plan de consultas es una serie de pasos, como instrucciones, que se utilizan para acceder a los datos de un sistema de base de datos relacional SQL. Para desarrollar un rendimiento optimizado Spark
SQL consulte un plan, el primer paso es ver el EXPLAIN plan, interpretarlo y, a continuación, ajustarlo. Puede utilizar el Spark SQL interfaz de usuario (UI) o Spark SQL Servidor de historial para visualizar el plan.
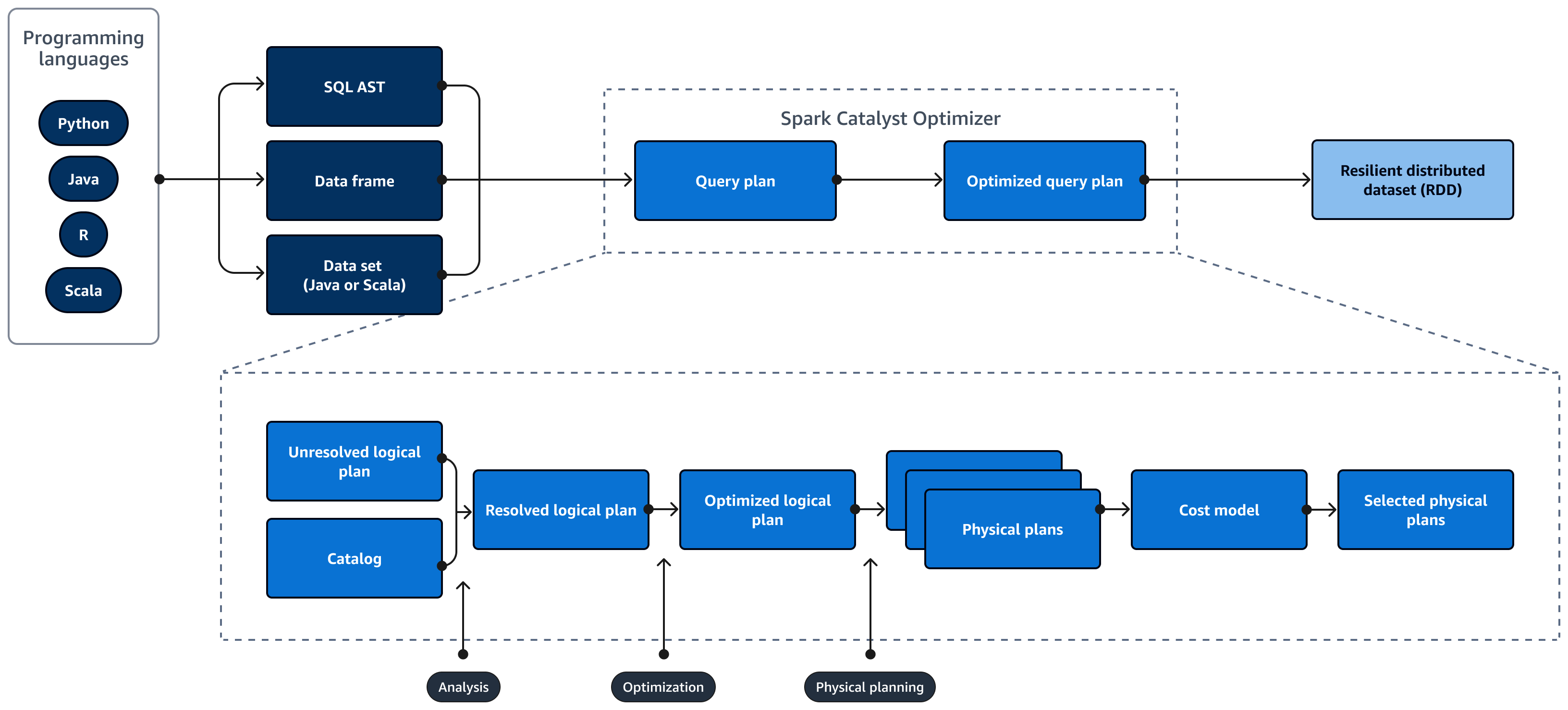
Spark Catalyst Optimizer convierte el plan de consultas inicial en un plan de consultas optimizado de la siguiente manera:
-
Análisis y declarativo APIs: la fase de análisis es el primer paso. El plan lógico no resuelto, en el que los objetos a los que se hace referencia en la consulta SQL no se conocen o no coinciden con una tabla de entrada, se genera con atributos y tipos de datos independientes. La Spark SQL Luego, Catalyst Optimizer aplica un conjunto de reglas para crear un plan lógico. El analizador SQL puede generar un árbol sintáctico abstracto (AST) de SQL y proporcionarlo como entrada para el plan lógico. La entrada también puede ser un marco de datos o un objeto de conjunto de datos que se crea mediante una API. En la siguiente tabla se muestra cuándo debe usar SQL, marcos de datos o conjuntos de datos.
SQL Tramas de datos Conjuntos de datos Errores de sintaxis Tiempo de ejecución Tiempo de compilación Tiempo de compilación Errores de análisis Tiempo de ejecución Tiempo de ejecución Tiempo de compilación Para obtener más información sobre los tipos de entradas, consulte lo siguiente:
-
La API de un conjunto de datos proporciona una versión mecanografiada. Esto reduce el rendimiento debido a que se depende en gran medida de las funciones lambda definidas por el usuario. Los RDD o los conjuntos de datos se escriben de forma estática. Por ejemplo, al definir un RDD, es necesario proporcionar de forma explícita la definición del esquema.
-
Una API de marco de datos proporciona operaciones relacionales sin tipo. Los marcos de datos se escriben dinámicamente. Al igual que en RDD, cuando se define un marco de datos, el esquema permanece igual. Los datos siguen estructurados. Sin embargo, esta información solo está disponible en tiempo de ejecución. Esto permite al compilador escribir sentencias tipo SQL y definir nuevas columnas sobre la marcha. Por ejemplo, puede añadir columnas a un marco de datos existente sin necesidad de definir una nueva clase para cada operación.
-
A Spark SQL La consulta se evalúa para detectar errores de sintaxis y análisis durante el tiempo de ejecución, lo que proporciona tiempos de ejecución más rápidos.
-
-
Catálogo:Spark SQL uses Apache Hive Metastore (HMS) para gestionar los metadatos de las entidades relacionales persistentes, como bases de datos, tablas, columnas y particiones.
-
Optimización: el optimizador reescribe el plan de consultas mediante la heurística y el costo. Hace lo siguiente para producir un plan lógico optimizado:
-
Poda las columnas
-
Empuja los predicados hacia abajo
-
Reordena las uniones
-
-
Los planes físicos y el planificador: Spark SQL Catalyst Optimizer convierte el plan lógico en un conjunto de planes físicos. Esto significa que convierte el qué en cómo.
-
Planes físicos seleccionados: Spark SQL Catalyst Optimizer selecciona el plan físico más rentable.
-
Plan de consultas optimizado: Spark SQL ejecuta el plan de consultas optimizado para el rendimiento y los costes. Spark SQL La administración de memoria realiza un seguimiento del uso de la memoria y la distribuye entre las tareas y los operadores. La Spark SQL El motor Tungsten puede mejorar sustancialmente la eficiencia de la memoria y la CPU para Spark SQL aplicaciones. También implementa el procesamiento de modelos de datos binarios y opera directamente con datos binarios. Esto evita la necesidad de deserialización y reduce significativamente la sobrecarga asociada a la conversión y deserialización de datos.
