Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Información general de la solución
Un marco de ML escalable
En una empresa con millones de clientes repartidos en varias líneas de negocio, los flujos de trabajo de ML requieren la integración de los datos que son propiedad de equipos aislados y administrados por ellos y utilizan diferentes herramientas para aprovechar el valor empresarial. Los bancos están comprometidos a proteger los datos de sus clientes. Del mismo modo, la infraestructura utilizada para el desarrollo de los modelos de ML también está sujeta a altos estándares de seguridad. Esta seguridad adicional suma complejidad y repercute en el tiempo de creación de valor de nuevos modelos de ML. En un marco de aprendizaje automático escalable, puede utilizar un conjunto de herramientas estandarizado y modernizado para reducir el esfuerzo necesario para combinar diferentes herramientas y simplificar el route-to-live proceso para los nuevos modelos de aprendizaje automático.
Tradicionalmente, la administración y el soporte de las actividades de ciencia de datos en el sector de los servicios financieros están controlados por un equipo de plataforma central que recopila los requisitos, aprovisiona los recursos y mantiene la infraestructura para los equipos de datos de toda la organización. Para escalar rápidamente el uso de ML en los equipos federados de toda la organización, se puede utilizar un marco de ML escalable para brindar capacidades de autoservicio a los desarrolladores de nuevos modelos y canalizaciones. Esto permite a los desarrolladores implementar una infraestructura moderna, previamente aprobada, estandarizada y segura. En última instancia, estas capacidades de autoservicio reducen la dependencia de su organización de los equipos de plataformas centralizadas y aceleran la rentabilidad del desarrollo de modelos de ML.
El marco escalable de ML sirve para que los consumidores de datos (por ejemplo, científicos de datos o ingenieros de ML) aprovechen el valor empresarial y les permite hacer lo siguiente:
Explorar y descubrir los datos previamente aprobados que se requieren para el entrenamiento de modelos
Acceder a los datos previamente aprobados de forma rápida y sencilla
Utilizar datos previamente aprobados para demostrar la viabilidad del modelo
Lanzar el modelo probado a producción para que lo usen otros
El siguiente diagrama destaca el end-to-end flujo del marco y la forma simplificada de operar para los casos de uso del aprendizaje automático.
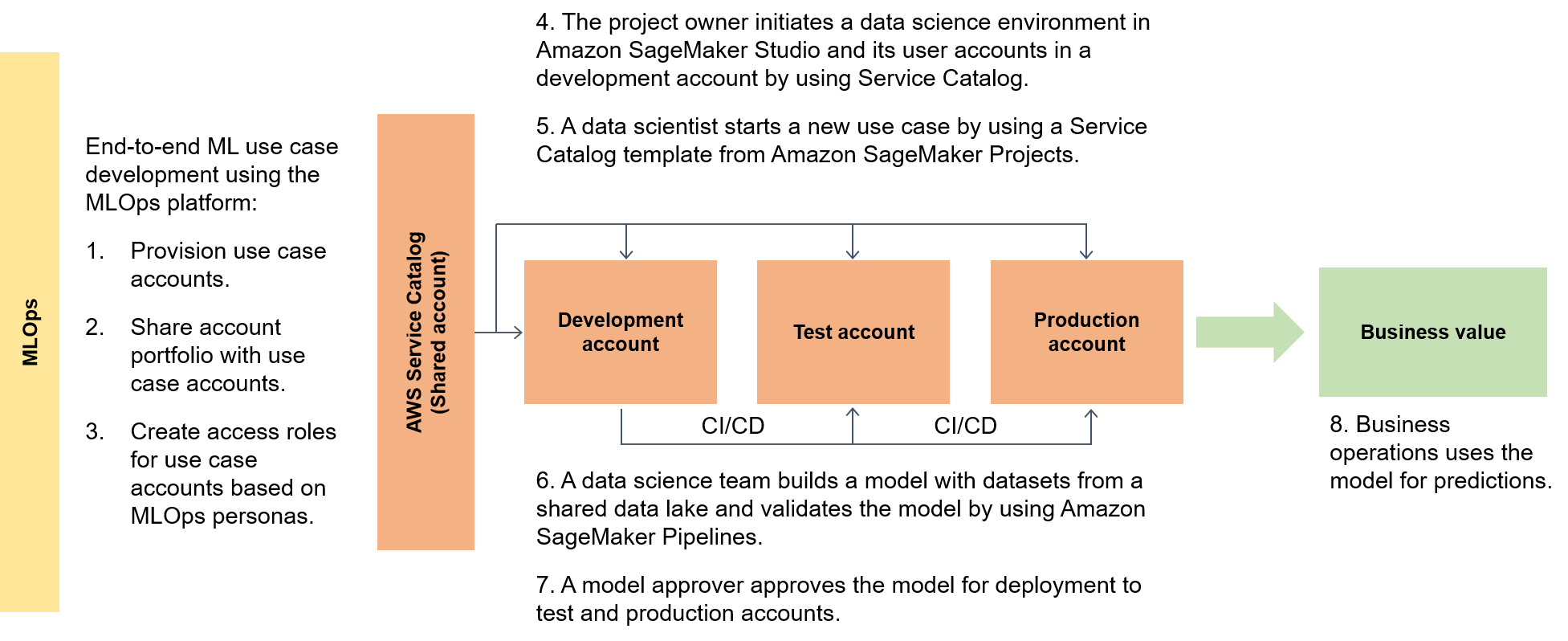
En un contexto más amplio, los consumidores de datos utilizan un acelerador sin servidor denominado data.all para obtener datos de varios lagos de datos y, a continuación, los utilizan para entrenar sus modelos, como se ilustra en el siguiente diagrama.
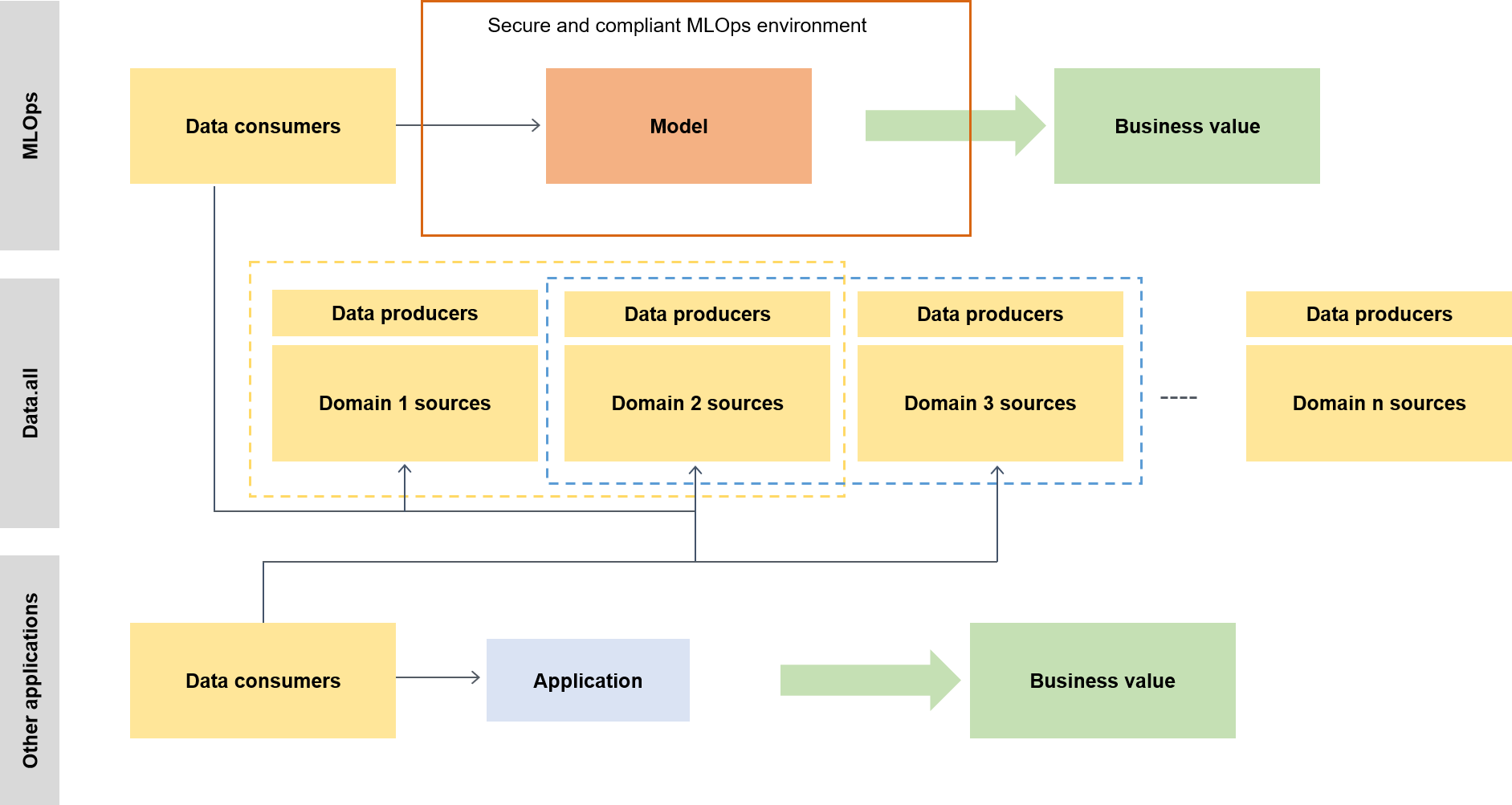
En un nivel inferior, el marco de ML escalable contiene lo siguiente:
Implementación de infraestructura de autoservicio: reduzca su dependencia de los equipos centralizados.
Sistema central de administración de paquetes Python: ponga a disposición paquetes de Python previamente aprobados para el desarrollo de modelos.
Canalizaciones de CI/CD para el desarrollo y la promoción de modelos: reduzca el tiempo de vida al incluir la integración continua y las canalizaciones continuas (CI/CD) como parte de sus plantillas de infraestructura como código (IaC).
Capacidades de prueba de modelos: aproveche las funcionalidades de pruebas unitarias, pruebas de modelos, end-to-end pruebas de integración y pruebas que están disponibles automáticamente para los nuevos modelos.
Desacoplamiento y orquestación de modelos: evite la computación innecesaria y haga que sus implementaciones sean más sólidas desacoplando los pasos del modelo según los requisitos de recursos computacionales y orquestando los diferentes pasos mediante Amazon AI Pipelines. SageMaker
Estandarización del código: mejore la calidad de su código mediante la integración de CI/CD canalizaciones para validar los estándares de la Propuesta de Mejora de Python (PEP 8
). Plantillas de aprendizaje automático genéricas de inicio rápido: obtenga plantillas de Service Catalog que instancien sus entornos de modelado de aprendizaje automático (desarrollo, preproducción y producción) y los procesos asociados con solo hacer clic en un botón mediante AI Projects para la implementación. SageMaker
Supervisión de la calidad de los datos y los modelos: asegúrese de que sus modelos cumplen con los requisitos operativos y dentro de su nivel de tolerancia al riesgo mediante el uso de Amazon SageMaker AI Model Monitor para supervisar automáticamente las desviaciones en la calidad de los datos y los modelos.
Monitoreo de sesgos: permita que los propietarios de sus modelos tomen decisiones justas y equitativas comprobando automáticamente si hay desequilibrios en los datos y si los cambios en el mundo han introducido sesgos en su modelo.
Un concentrador central de metadatos
Data.all
SageMaker validación
Para demostrar las capacidades de la SageMaker IA en una variedad de arquitecturas de procesamiento de datos y aprendizaje automático, el equipo que implementa las capacidades selecciona, junto con el equipo directivo bancario, casos de uso de complejidad variable de diferentes divisiones de clientes bancarios. Los datos del caso de uso se ocultan y están disponibles en un depósito de datos local de Amazon Simple Storage Service (Amazon S3)
Cuando se completa la migración del modelo del entorno de entrenamiento original a una arquitectura de SageMaker IA, el lago de datos alojado en la nube permite que los datos estén disponibles para que los lean los modelos de producción. A continuación, las predicciones generadas por los modelos de producción se vuelven a escribir en el lago de datos.
Una vez migrados los casos de uso candidatos, el marco de ML escalable toma una base de referencia inicial para las métricas objetivo. Puede comparar la base de referencia con los tiempos anteriores en las instalaciones o con otros proveedores de servicios en la nube como prueba de las mejoras de tiempo que permite el marco de ML escalable.
