Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Arquitectura para un sistema de rastreo web escalable en AWS
El siguiente diagrama de arquitectura muestra un sistema de rastreo web diseñado para extraer de manera ética datos ambientales, sociales y de gobierno (ESG) de los sitios web. Utilizas un Pythonrastreador basado en software optimizado para la AWS infraestructura. Solía organizar AWS Batch las tareas de rastreo a gran escala y utilizar Amazon Simple Storage Service (Amazon S3) para el almacenamiento. Las aplicaciones posteriores pueden ingerir y almacenar los datos del bucket de Amazon S3.
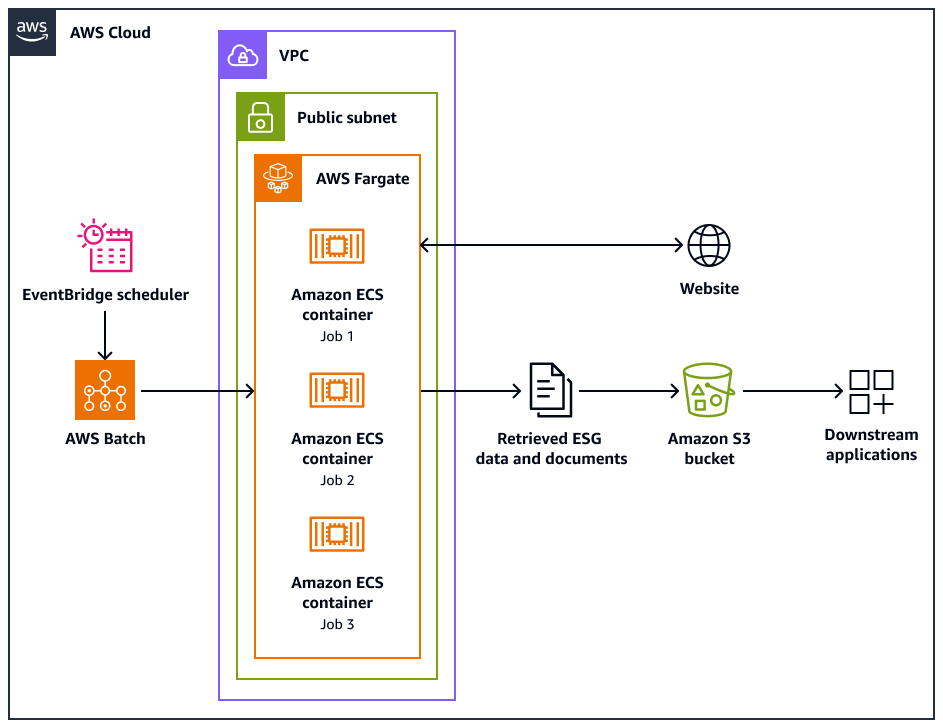
En el diagrama, se muestra el siguiente flujo de trabajo:
-
Amazon EventBridge Scheduler inicia el proceso de rastreo en un intervalo que usted programe.
-
AWS Batch gestiona la ejecución de las tareas del rastreador web. La cola de AWS Batch trabajos contiene y organiza los trabajos de rastreo pendientes.
-
Los trabajos de rastreo web se ejecutan en contenedores de Amazon Elastic Container Service (Amazon ECS) en. AWS Fargate Los trabajos se ejecutan en una subred pública de una nube privada virtual (VPC).
-
El rastreador web rastrea el sitio web de destino y recupera datos y documentos de ESG, como PDF, CSV u otros archivos de documentos.
-
El rastreador web almacena los datos recuperados y los archivos sin procesar en un bucket de Amazon S3.
-
Otros sistemas o aplicaciones ingieren o procesan los datos y archivos almacenados en el bucket de Amazon S3.
Diseño y operaciones de los rastreadores web
Algunos sitios web están diseñados específicamente para ejecutarse en ordenadores de sobremesa o dispositivos móviles. El rastreador web está diseñado para admitir el uso de un agente de usuario de escritorio o un agente de usuario móvil. Estos agentes le ayudan a realizar correctamente las solicitudes al sitio web de destino.
Una vez inicializado el rastreador web, realiza las siguientes operaciones:
-
El rastreador web llama al método.
setup()Este método busca y analiza el archivo robots.txt.nota
También puedes configurar el rastreador web para que busque y analice el mapa del sitio.
-
El rastreador web procesa el archivo robots.txt. Si se especifica un retraso de rastreo en el archivo robots.txt, el rastreador web extrae el retraso de rastreo para el agente de usuario de escritorio. Si no se especifica ningún retraso de rastreo en el archivo robots.txt, el rastreador web utiliza un retraso aleatorio.
-
El rastreador web llama al
crawl()método, lo que inicia el proceso de rastreo. Si no URLs hay ninguno en la cola, añade la URL de inicio.nota
El rastreador continúa rastreando hasta que alcance el número máximo de páginas o se quede sin páginas URLs para rastrear.
-
El rastreador procesa el. URLs Para cada URL de la cola, el rastreador comprueba si la URL ya se ha rastreado.
-
Si no se ha rastreado una URL, el rastreador llama al método de la siguiente manera:
crawl_url()-
El rastreador comprueba el archivo robots.txt para determinar si puede utilizar el agente de usuario de escritorio para rastrear la URL.
-
Si está permitido, el rastreador intentará rastrear la URL mediante el agente de usuario de escritorio.
-
Si no está permitido o si el agente de usuario de escritorio no puede rastrear, el rastreador comprueba el archivo robots.txt para determinar si puede utilizar el agente de usuario móvil para rastrear la URL.
-
Si está permitido, el rastreador intentará rastrear la URL mediante el agente de usuario móvil.
-
-
El rastreador llama al
attempt_crawl()método, que recupera y procesa el contenido. El rastreador envía una solicitud GET a la URL con los encabezados adecuados. Si se produce un error en la solicitud, el rastreador utiliza la lógica de reintento. -
Si el archivo está en formato HTML, el rastreador llama al método.
extract_esg_data()Utiliza Beautiful Souppara analizar el contenido HTML. Extrae datos ambientales, sociales y de gobierno (ESG) mediante la coincidencia de palabras clave. Si el archivo es un PDF, el rastreador llama al
save_pdf()método. El rastreador descarga y guarda el archivo PDF en el bucket de Amazon S3. -
El rastreador llama al método.
extract_news_links()Busca y almacena enlaces a artículos de noticias, comunicados de prensa y publicaciones de blogs. -
El rastreador llama al
extract_pdf_links()método. Esto identifica y almacena los enlaces a los documentos PDF. -
El rastreador llama al
is_relevant_to_sustainable_finance()método. Esto comprueba si las noticias o los artículos están relacionados con las finanzas sostenibles mediante el uso de palabras clave predefinidas. -
Después de cada intento de rastreo, el rastreador implementa un retraso mediante el
delay()método. Si se especificó un retraso en el archivo robots.txt, utilizará ese valor. De lo contrario, utiliza un retraso aleatorio de entre 1 y 3 segundos. -
El rastreador llama al
save_esg_data()método para guardar los datos de ESG en un archivo CSV. El archivo CSV se guarda en el bucket de Amazon S3. -
El rastreador utiliza el
save_news_links()método para guardar los enlaces de noticias a un archivo CSV, incluida la información relevante. El archivo CSV se guarda en el bucket de Amazon S3. -
El rastreador utiliza el
save_pdf_links()método para guardar los enlaces del PDF a un archivo CSV. El archivo CSV se guarda en el bucket de Amazon S3.
Procesamiento de datos y procesamiento de datos
El proceso de rastreo se organiza y se realiza de forma estructurada. AWS Batch asigna los trabajos a cada empresa para que se ejecuten en paralelo, en lotes. Cada lote se centra en el dominio y los subdominios de una sola empresa, tal como los ha identificado en su conjunto de datos. Sin embargo, los trabajos del mismo lote se ejecutan de forma secuencial para no inundar el sitio web con demasiadas solicitudes. Esto ayuda a la aplicación a gestionar la carga de trabajo de rastreo de forma más eficiente y a garantizar que se recopilen todos los datos relevantes de cada empresa.
Al organizar el rastreo web en lotes específicos de la empresa, se agrupan los datos recopilados. Esto ayuda a evitar que los datos de una empresa se mezclen con los datos de otras empresas.
El procesamiento por lotes ayuda a la aplicación a recopilar datos de la web de manera eficiente, al tiempo que mantiene una estructura clara y una separación de la información en función de las empresas objetivo y sus respectivos dominios web. Este enfoque ayuda a garantizar la integridad y la usabilidad de los datos recopilados, ya que están perfectamente organizados y asociados a la empresa y los dominios adecuados.
