Amazon Redshift dejará de admitir la creación de nuevas UDF de Python a partir del 1 de noviembre de 2025. Si desea utilizar las UDF de Python, créelas antes de esa fecha. Las UDF de Python existentes seguirán funcionando con normalidad. Para obtener más información, consulte la publicación del blog
Arquitectura del sistema de almacenamiento de datos
En esta sección, se explican los componentes de los que consta la arquitectura de almacenamiento de datos de Amazon Redshift, como se puede ver en la siguiente imagen.
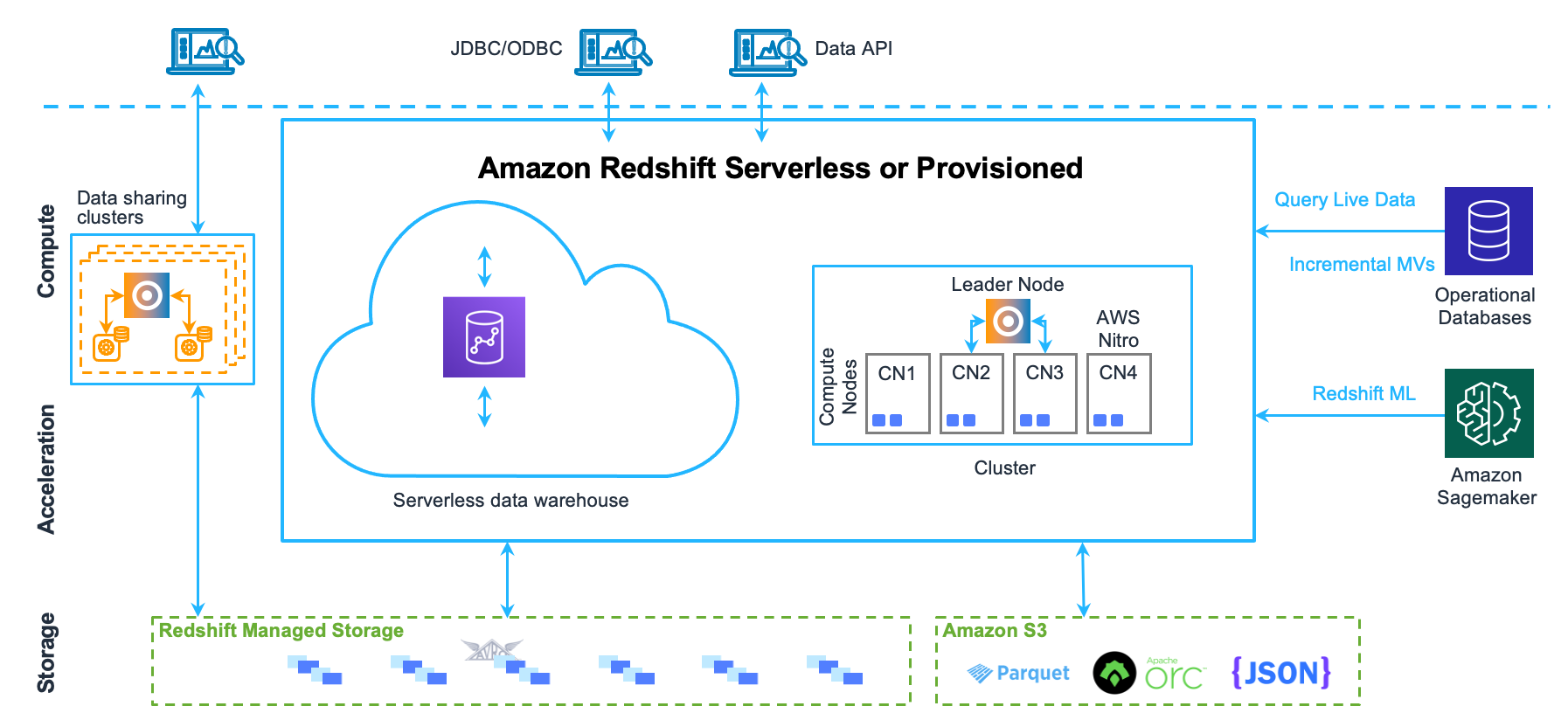
Aplicaciones cliente
Amazon Redshift se integra a diversas herramientas de carga de datos y ETL (extracción, transformación y carga) y a diversas herramientas de inteligencia empresarial (BI), generación de informes, minería de datos y análisis. Amazon Redshift se basa en el estándar abierto PostgreSQL, por lo que la mayoría de las aplicaciones cliente SQL existentes funcionarán con solo un mínimo de cambios. Para obtener más información acerca de las importantes diferencias que existen entre Amazon Redshift SQL y PostgreSQL, consulte Amazon Redshift y PostgreSQL.
Clústeres
El principal componente de la infraestructura de un almacenamiento de datos de Amazon Redshift es el clúster.
Un clúster se compone de uno o varios nodos de computación. Si un clúster se aprovisiona con dos o más nodos de computación, un nodo principal adicional coordina los nodos de computación y administra la comunicación externa. La aplicación cliente interactúa de forma directa solo con el nodo principal. Los nodos de computación son transparentes para las aplicaciones externas.
Nodo principal
El nodo principal administra las comunicaciones con los programas de clientes y todas las comunicaciones con los nodos de computación. Analiza y desarrolla los planes de ejecución para realizar las operaciones de bases de datos, en particular, la serie de pasos necesarios para obtener resultados de consultas complejas. Según el plan de ejecución, el nodo principal compila un código, lo distribuye a los nodos de computación y les asigna una parte de los datos a cada uno.
El nodo principal distribuye instrucciones SQL a los nodos de computación solo cuando una consulta hace referencia a tablas que se encuentran almacenadas en los nodos de computación. Todas las demás consultas se ejecutan exclusivamente en el nodo principal. Amazon Redshift está diseñado para implementar ciertas funciones SQL solo en el nodo principal. Una consulta que utiliza cualquiera de estas funciones devolverá un mensaje de error si hace referencia a tablas que residen en los nodos de computación. Para obtener más información, consulte Funciones SQL admitidas en el nodo principal.
Nodos de computación
El nodo principal compila un código para los elementos individuales del plan de ejecución y lo asigna a los nodos de computación individuales. Los nodos de computación ejecutan el código compilado y envían resultados intermedios de vuelta al nodo principal para su agregación final.
Cada nodo de computación tiene su propia CPU y memoria dedicadas, que se determinan por el tipo de nodo. A medida que la carga de trabajo crece, puede aumentar la capacidad de computación de un clúster mediante el incremento del número de nodos, la actualización del tipo de nodo o ambas acciones.
Amazon Redshift proporciona varios tipos de nodo que se ajustan a sus necesidades de computación. Para obtener información detallada acerca de cada tipo de nodo, consulte Clústeres de Amazon Redshift en la Guía de administración de Amazon Redshift.
Redshift Managed Storage
Los datos del almacenamiento de datos se almacenan en Redshift Managed Storage (RMS) de nivel de almacenamiento independiente. RMS ofrece la posibilidad de escalar el almacenamiento hasta petabytes mediante el almacenamiento de Amazon S3. RMS le permite escalar y pagar la computación y el almacenamiento de forma independiente, de modo que pueda dimensionar su clúster en función únicamente de sus necesidades de computación. Utiliza automáticamente el almacenamiento local basado en SSD de alto rendimiento como caché de nivel 1. También aprovecha las optimizaciones, como la temperatura del bloque de datos, la antigüedad del bloque de datos y los patrones de cargas de trabajo para ofrecer un alto rendimiento y, al mismo tiempo, escalar el almacenamiento automáticamente a Amazon S3 cuando sea necesario sin necesidad de realizar ninguna acción.
Sectores del nodo
Un nodo de computación está particionado en sectores. A cada sector se le asigna una parte de la memoria y del espacio en disco del nodo, donde se procesa una parte de la carga de trabajo asignada al nodo. El nodo principal administra los datos de distribución a los sectores y les reparte la carga de trabajo de cualquier consulta u otra operación de base de datos. A continuación, los sectores funcionan en paralelo para completar la operación.
El número de sectores por nodo está determinado por el tamaño de nodo del clúster. Para obtener más información acerca del número de sectores para cada tamaño de nodo, consulte Acerca de clústeres y nodos en la Guía de administración de Amazon Redshift.
Cuando crea una tabla, opcionalmente puede especificar una columna como la clave de distribución. Cuando se carga la tabla con los datos, las filas se distribuyen a los sectores del nodo de acuerdo con la clave de distribución que se defina para una tabla. La elección de una buena clave de distribución permite que Amazon Redshift utilice el procesamiento en paralelo para cargar datos y ejecutar consultas de forma eficiente. Para obtener más información acerca de una clave de distribución, consulte Elegir el modo de distribución recomendado.
Red interna
Amazon Redshift aprovecha las conexiones de ancho de banda alto, la gran proximidad y los protocolos de comunicación personalizados para proporcionar una comunicación de red privada de muy alta velocidad entre el nodo principal y los nodos informáticos. Los nodos de computación se ejecutan en una red aislada independiente a las que las aplicaciones cliente nunca obtienen acceso directamente.
Bases de datos
Un clúster contiene una o varias bases de datos. Los datos de usuario se almacenan en los nodos de computación. El cliente SQL se comunica con el nodo principal y este coordina la ejecución de consultas con los nodos de computación.
Amazon Redshift es un sistema de administración de base de datos relacional (RDBMS), por lo que es compatible con otras aplicaciones de RDBMS. Aunque proporciona la misma funcionalidad que un RDBMS típico, incluidas las funciones de procesamiento de transacciones online (OLTP), como insertar y eliminar datos, Amazon Redshift está optimizado para realizar informes y análisis de alto rendimiento de conjuntos de datos muy grandes.
Amazon Redshift se basa en PostgreSQL. Amazon Redshift y PostgreSQL tienen una serie de diferencias muy importantes que debe tener en cuenta al diseñar y desarrollar aplicaciones de almacenamiento de datos. Para obtener más información acerca de las diferencias entre Amazon Redshift SQL y PostgreSQL, consulte Amazon Redshift y PostgreSQL.
