Administración del volumen de filas fusionadas
Si una operación de limpieza necesita fusionar filas nuevas en la región ordenada de una tabla, el tiempo requerido para una limpieza aumentará a medida que la tabla aumente. Puede mejorar el rendimiento de la limpieza al reducir la cantidad de filas que deben fusionarse.
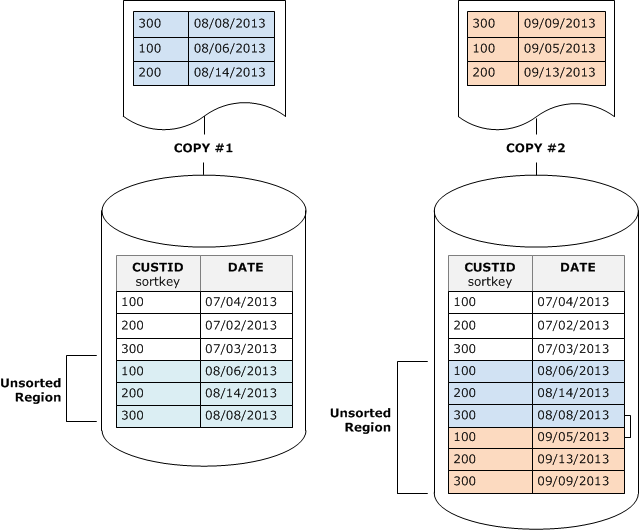
Antes de una limpieza, una tabla consta de una región ordenada en la parte superior, seguida de una región no ordenada que aumenta cada vez que se agregan o actualizan filas. Cuando se agrega un conjunto de filas mediante una operación COPY, el conjunto nuevo de filas se ordena en la clave de ordenación a medida que se agrega a la región no ordenada que se encuentra al final de la tabla. Las filas nuevas se ordenan dentro de su propio conjunto, pero no dentro de la región no ordenada.
En el siguiente diagrama, se ilustra la región no ordenada luego de dos operaciones COPY sucesivas, donde la clave de ordenación es CUSTID. Para mayor simpleza, en este ejemplo se muestra una clave de ordenación compuesta, pero los mismos principios se aplican a las claves de ordenación intercaladas, excepto que, para las tablas intercaladas, el impacto de la región no ordenada es mayor.
Una operación de limpieza restaura el orden de la tabla en dos fases:
-
Ordena la región no ordenada en una región recién ordenada.
La primera fase es relativamente poco costosa, porque solo se rescribe la región no ordenada. Si el rango de valores de clave de clasificación de la región recién ordenada es mayor que el rango existente, solo se deben rescribir las filas nuevas y la limpieza se completa. Por ejemplo, si la región ordenada tiene valores de ID de 1 a 500 y las operaciones de copia subsecuentes agregan valores de clave mayores que 500, solo se debe rescribir la región no ordenada.
-
Fusiona la región recién ordenada con la región anteriormente ordenada.
Si las claves de la región recién ordenada se superponen con las claves de la región ordenada, VACUUM necesita fusionar las filas. Desde el comienzo de la región recién ordenada (en la clave de ordenación más baja), la limpieza escribe las filas fusionadas de las regiones anteriormente y recién ordenadas en un nuevo conjunto de bloques.
El grado de superposición del nuevo rango de claves de ordenación en relación con las claves de ordenación existentes determina hasta dónde es necesario rescribir la región antes ordenada. Si las claves no ordenadas se encuentran esparcidas por todo el rango de ordenación existente, podría necesitarse una limpieza que rescriba partes de la tabla.
En el siguiente diagrama, se muestra cómo una limpieza ordenaría y fusionaría las filas agregadas a una tabla en la que CUSTID es la clave de ordenación. Como cada operación de COPY agrega un nuevo conjunto de filas con valores de clave que se superponen con las claves existentes, se debe rescribir casi toda la tabla. En el diagrama, se muestra una única ordenación y fusión, pero, en la práctica, una operación de limpieza grande consiste en una serie de pasos incrementales de ordenación y fusión.

Si el rango de las claves de ordenación en un conjunto de filas nuevas se superpone con el rango de claves existentes, el costo de la fase de fusión continúa aumentando de manera proporcional al tamaño de la tabla, a medida que la tabla aumenta mientras el costo de la fase de ordenación se mantiene proporcional al tamaño de la región no ordenada. En tal caso, el costo de la fase de fusión supera el costo de la fase de ordenación, como lo muestra el diagrama a continuación.

Para determinar qué proporción de una tabla se volvió a fusionar, ejecute una consulta SVV_VACUUM_SUMMARY una vez terminada la operación de limpieza. La siguiente consulta muestra el efecto de seis limpiezas consecutivas, a medida que CUSTSALES aumenta cada vez más con el paso del tiempo.
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
La columna merge_increments indica la cantidad de datos fusionados en cada operación de limpieza. Si la cantidad de incrementos de fusión durante las limpiezas consecutivas aumenta de manera proporcional al crecimiento en el tamaño de la tabla, indica que cada operación de limpieza vuelve a fusionar una cantidad cada vez mayor de filas en la tabla, debido a que las regiones ordenadas ya existentes y las nuevas se superponen.
