Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Introducción a Etiquetas personalizadas de Amazon Rekognition
Antes de empezar con la Introducción, le recomendamos que lea Qué es Etiquetas personalizadas de Amazon Rekognition.
Etiquetas personalizadas de Amazon Rekognition sirve para entrenar un modelo de machine learning. El modelo entrenado analiza las imágenes para encontrar objetos, escenas y objetos que son exclusivos de su empresa o negocio. Por ejemplo, puede entrenar un modelo para que clasifique imágenes de casas o busque la ubicación de los componentes electrónicos en una placa de circuito impreso.
Para ayudarle a empezar, hay disponibles tutoriales de vídeo y proyectos de ejemplo de Etiquetas personalizadas de Amazon Rekognition.
Tutoriales de vídeo
En los vídeos se explica cómo utilizar Etiquetas personalizadas de Amazon Rekognition para entrenar y utilizar un modelo.
Cómo ver los tutoriales de vídeo
Inicie sesión en la consola Amazon Rekognition AWS Management Console y ábrala en. https://console.aws.amazon.com/rekognition/
En el panel izquierdo, elija Usar etiquetas personalizadas. Se abrirá la página de inicio de Etiquetas personalizadas de Amazon Rekognition. Si no aparece la opción Utilizar etiquetas personalizadas, compruebe que la región de AWS que utiliza es compatible con Etiquetas personalizadas de Amazon Rekognition.
En el panel de navegación, elija Introducción.
En ¿Qué es Etiquetas personalizadas de Amazon Rekognition?, seleccione el vídeo para ver la introducción.
En el panel de navegación, elija Tutoriales.
En la página Tutoriales, elija los tutoriales de vídeo que desee ver.
Proyectos de ejemplo
Etiquetas personalizadas de Amazon Rekognition incluye los siguientes proyectos de ejemplo.
Clasificación de imágenes
El proyecto de clasificación de imágenes (habitaciones) entrena un modelo que busca una o varias ubicaciones de una casa en una imagen, como la terraza, la cocina y el patio. Las imágenes de entrenamiento y de prueba representan una única ubicación. Cada imagen está etiquetada con una única etiqueta de imagen, como cocina, patio o sala_estar. En el caso de una imagen analizada, el modelo entrenado devuelve una o varias etiquetas similares del conjunto de etiquetas de imagen utilizadas para el entrenamiento. Por ejemplo, el modelo podría encontrar la etiqueta sala_estar en la siguiente imagen. Para obtener más información, consulte Encontrar objetos, escenas y conceptos.

Clasificación de imágenes de etiquetas múltiples
El proyecto de clasificación de imágenes con etiquetas múltiples (flores) entrena un modelo que clasifica las imágenes de flores en tres conceptos (tipo de flor, presencia de hojas y fase de crecimiento).
Las imágenes de entrenamiento y de prueba tienen etiquetas de imagen por cada concepto, como camelia para un tipo de flor, con_hojas para una flor con hojas y floración_total para una flor que ya ha crecido.
En el caso de una imagen analizada, el modelo entrenado devuelve etiquetas similares del conjunto de etiquetas de imagen utilizadas para el entrenamiento. Por ejemplo, el modelo devuelve las etiquetas euforbio_mediterráneo y con_hojas para la siguiente imagen. Para obtener más información, consulte Encontrar objetos, escenas y conceptos.

Detección de marcas
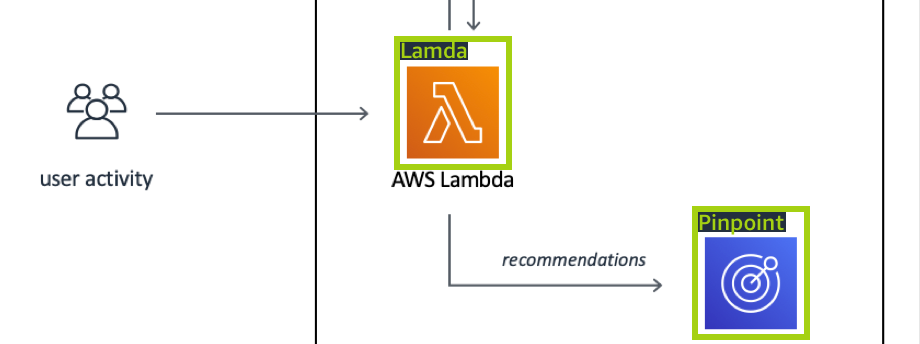
El proyecto de detección de marcas (Logos) entrena a un modelo que encuentra la ubicación de determinados AWS logotipos, como Amazon Textract y AWS lambda. Las imágenes de entrenamiento son solo de logotipo y tienen una única etiqueta de imagen, como lambda o textract. También es posible entrenar un modelo de detección de marcas con imágenes de entrenamiento que tengan cuadros delimitadores para las ubicaciones de las marcas. Las imágenes de prueba tienen cuadros delimitadores etiquetados que representan la ubicación de los logotipos en ubicaciones naturales, como un diagrama arquitectónico. El modelo entrenado busca los logotipos y devuelve un cuadro delimitador etiquetado por cada logotipo encontrado. Para obtener más información, consulte Encontrar ubicaciones de marcas.
Localización de objetos
El proyecto de localización de objetos (placas de circuito) entrena un modelo que busca la ubicación de las piezas en una placa de circuito impreso, como un comparador o un diodo emisor de luz infrarroja. Las imágenes de entrenamiento y prueba incluyen cuadros delimitadores que rodean los componentes de la placa de circuito y una etiqueta que identifica la pieza dentro del cuadro delimitador. En la siguiente imagen de ejemplo, los nombres de las etiquetas son fototransistor_ir, led_ir, pot_resistor y comparator. El modelo entrenado busca los componentes de la placa de circuito y devuelve un cuadro delimitador etiquetado por cada pieza del circuito encontrada. Para obtener más información, consulte Encontrar ubicaciones de objetos.

Aplicación de los proyectos de ejemplo
Estas instrucciones de primeros pasos le explican cómo entrenar un modelo mediante proyectos de ejemplo que Etiquetas personalizadas de Amazon Rekognition crea para usted. También le indica cómo iniciar el modelo y usarlo para analizar una imagen.
Creación del proyecto de ejemplo
Para empezar, decida qué proyecto usar. Para obtener más información, consulte Paso 1: Elegir un proyecto de ejemplo.
Etiquetas personalizadas de Amazon Rekognition utiliza conjuntos de datos para entrenar y evaluar (probar) un modelo. Un conjunto de datos administra las imágenes y las etiquetas que identifican el contenido de las imágenes. Los proyectos de ejemplo incluyen un conjunto de datos de entrenamiento y un conjunto de datos de prueba en los que se etiquetan todas las imágenes. No es necesario hacer ningún cambio antes de entrenar el modelo. En los proyectos de ejemplo se dan las dos formas en que Etiquetas personalizadas de Amazon Rekognition utiliza etiquetas para entrenar distintos tipos de modelos.
image-level: la etiqueta identifica un objeto, escena o concepto que representa la imagen completa.
bounding box: la etiqueta identifica el contenido de un cuadro delimitador. Un cuadro delimitador es un conjunto de coordenadas de imagen que rodean el objeto de una imagen.
Más adelante, cuando cree un proyecto con sus propias imágenes, deberá crear conjuntos de datos de entrenamiento y prueba y también etiquetar las imágenes. Para obtener más información, consulte Cómo decidir el tipo de modelo.
Entrenamiento de un modelo
Una vez que Etiquetas personalizadas de Amazon Rekognition haya creado el proyecto de ejemplo, puede entrenar el modelo. Para obtener más información, consulte Paso 2: Entrenar un modelo. Una vez finalizado el entrenamiento, normalmente se evalúa el rendimiento del modelo. Las imágenes del conjunto de datos de ejemplo ya crean un modelo de alto rendimiento y no es necesario evaluarlo antes de ejecutarlo. Para obtener más información, consulte Mejora de un modelo de Etiquetas personalizadas de Amazon Rekognition.
Uso del modelo
A continuación, inicie el modelo. Para obtener más información, consulte Paso 3: Ejecutar el modelo.
Después de empezar a ejecutar el modelo, puede usarlo para analizar nuevas imágenes. Para obtener más información, consulte Paso 4: Analizar una imagen con su modelo.
Se le cobrará por la cantidad de tiempo de ejecución del modelo. Cuando termine de usar el modelo de ejemplo, deberá detenerlo. Para obtener más información, consulte Paso 5: Detener el modelo.
Pasos a seguir a continuación
Cuando lo tenga todo listo, puede crear e implementar sus propios proyectos. Para obtener más información, consulte Paso 6: Siguientes pasos.
