Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Finalidad de los conjuntos de datos
La forma en que etiquete los conjuntos de datos de entrenamiento y prueba de su proyecto determina el tipo de modelo que se va a crear. Con Etiquetas personalizadas de Amazon Rekognition, puede crear modelos que hagan lo siguiente.
Encontrar objetos, escenas y conceptos
El modelo clasifica los objetos, las escenas y los conceptos que están asociados a una imagen completa.
Puede crear dos tipos de modelo de clasificación: clasificación de imágenes y clasificación de etiquetas múltiples. Para ambos tipos de modelo de clasificación, el modelo busca una o varias etiquetas que coincidan del conjunto entero de etiquetas utilizado para realizar el entrenamiento. Tanto los conjuntos de datos de entrenamiento como los de prueba necesitan al menos dos etiquetas.
Clasificación de imágenes
El modelo clasifica las imágenes como pertenecientes a un conjunto de etiquetas predefinidas. Por ejemplo, si desea un modelo que determine si en la imagen hay una sala de estar. La siguiente imagen puede tener una etiqueta de imagen sala_estar.

Para este tipo de modelo, agregue una sola etiqueta de imagen a cada una de las imágenes del conjunto de datos de entrenamiento y prueba. Para ver un objeto de ejemplo, consulte Clasificación de imágenes.
Clasificación de etiquetas múltiples
El modelo clasifica las imágenes en varias categorías, como por ejemplo, el tipo de flor y si tiene hojas o no. Por ejemplo, la imagen siguiente puede tener las etiquetas de imagen euforbio_mediterráneo y sin_hojas.

Para este tipo de modelo, asigne etiquetas de imagen por cada categoría a las imágenes del conjunto de datos de entrenamiento y prueba. Para ver un objeto de ejemplo, consulte Clasificación de imágenes de etiquetas múltiples.
Asignación de etiquetas de imagen
Si las imágenes están almacenadas en un bucket de Amazon S3, puede utilizar los nombres de las carpetas para agregar automáticamente etiquetas de imagen. Para obtener más información, consulte Importar imágenes desde un bucket de Amazon S3. También puede agregar etiquetas de imagen a las imágenes después de crear un conjunto de datos. Para obtener más información, consulte Asignación de etiquetas de imagen a una imagen. Puede agregar etiquetas nuevas cada vez que las necesite. Para obtener más información, consulte Administración de etiquetas.
Encontrar ubicaciones de objetos
Para crear un modelo que prediga la ubicación de los objetos en las imágenes, defina los cuadros delimitadores de la ubicación de los objetos y las etiquetas para las imágenes en los conjuntos de datos de entrenamiento y prueba. Un cuadro delimitador es un cuadro que rodea ajustadamente un objeto. Por ejemplo, en la siguiente imagen se ven unos cuadros delimitadores alrededor de un Amazon Echo y un Amazon Echo Dot. Cada cuadro delimitador tiene una etiqueta asignada (Amazon Echo o Amazon Echo Dot).

Para encontrar las ubicaciones de los objetos, los conjuntos de datos necesitan al menos una etiqueta. Mientras se entrena el modelo, se crea automáticamente otra etiqueta que representa el área situada fuera de los cuadros delimitadores de una imagen.
Asignación de cuadros delimitadores
Al crear el conjunto de datos, puede incluir información sobre los cuadros delimitadores de las imágenes. Por ejemplo, puedes importar un archivo de manifiesto en formato SageMaker AI Ground Truth que contenga cuadros delimitadores. También puede agregar cuadros delimitadores después de crear un conjunto de datos. Para obtener más información, consulte Etiquetado de objetos con cuadros delimitadores. Puede agregar etiquetas nuevas cada vez que las necesite. Para obtener más información, consulte Administración de etiquetas.
Encontrar ubicaciones de marcas
Si quiere encontrar la ubicación de marcas, como logotipos y personajes animados, puede usar dos tipos diferentes de imágenes para las imágenes del conjunto de datos de entrenamiento.
Imágenes que son solo de logotipo. Cada imagen necesita una única etiqueta de imagen que represente el nombre del logotipo. Por ejemplo, la etiqueta de imagen de la siguiente imagen podría ser Lambda.

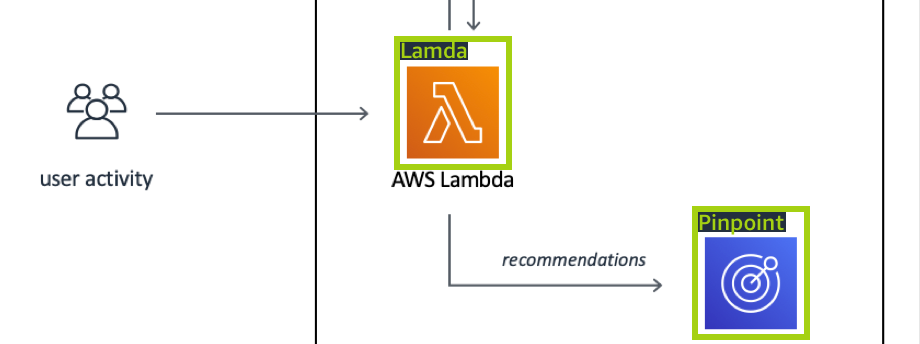
Imágenes con el logotipo en ubicaciones naturales, como un partido de fútbol o un diagrama arquitectónico. Cada imagen de entrenamiento necesita cuadros delimitadores que rodeen cada instancia del logotipo. Por ejemplo, en la siguiente imagen se muestra un diagrama de arquitectura con recuadros delimitadores etiquetados que rodean los logotipos de AWS Lambda y Amazon Pinpoint.
Le recomendamos que no mezcle etiquetas de imagen y cuadros delimitadores en las imágenes de entrenamiento.
Las imágenes de prueba deben tener cuadros delimitadores alrededor de las imágenes de la marca que quiera encontrar. Puede dividir el conjunto de datos de entrenamiento para crear el conjunto de datos de prueba, solo si las imágenes de entrenamiento incluyen cuadros delimitadores etiquetados. Si las imágenes de entrenamiento solo tienen etiquetas de imagen, debe crear un conjunto de conjuntos de datos de prueba que incluya imágenes con cuadros delimitadores etiquetados. Si se entrena un modelo para que busque ubicaciones de marcas, haga Etiquetado de objetos con cuadros delimitadores y Asignación de etiquetas de imagen a una imagen según la forma en que etiquete las imágenes.
En el proyecto de ejemplo Detección de marcas, se ve cómo Etiquetas personalizadas de Amazon Rekognition utiliza cuadros delimitadores etiquetados para entrenar un modelo que busca ubicaciones de objetos.
Requisitos de etiquetado de tipos de modelos
Use la siguiente tabla para determinar cómo etiquetar las imágenes.
Puede combinar etiquetas de imagen e imágenes etiquetadas con cuadros delimitadores en un único conjunto de datos. En este caso, Etiquetas personalizadas de Amazon Rekognition elige si desea crear un modelo de imagen o un modelo de ubicación de objetos.
| Ejemplo | Imágenes de entrenamiento | Imágenes de prueba |
|---|---|---|
|
1 etiqueta de imagen por imagen |
1 etiqueta de imagen por imagen |
|
|
Etiquetas múltiples de imagen por imagen |
Etiquetas múltiples de imagen por imagen |
|
|
Etiquetas de imagen (también puede utilizar cuadros delimitadores etiquetados) |
Cuadros delimitadores etiquetados |
|
|
Cuadros delimitadores etiquetados |
Cuadros delimitadores etiquetados |
