Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ejercicio 1: Detectar objetos y escenas (consola)
En esta sección se explica de manera muy general cómo funciona la capacidad de detección de objetos y escenas de Amazon Rekognition. Cuando especifica una imagen como entrada, el servicio detecta los objetos y las escenas de la imagen y los devuelve junto con una puntuación de porcentaje de confianza en forma de porcentaje de cada objeto y escena.
Por ejemplo, Amazon Rekognition detecta los siguientes objetos y escenas en la imagen de muestra: skateboard, deporte, persona, auto, coche y vehículo.

Amazon Rekognition devuelve también una puntuación de confianza para cada objeto detectado en la imagen de ejemplo, como se muestra en la siguiente respuesta de ejemplo.
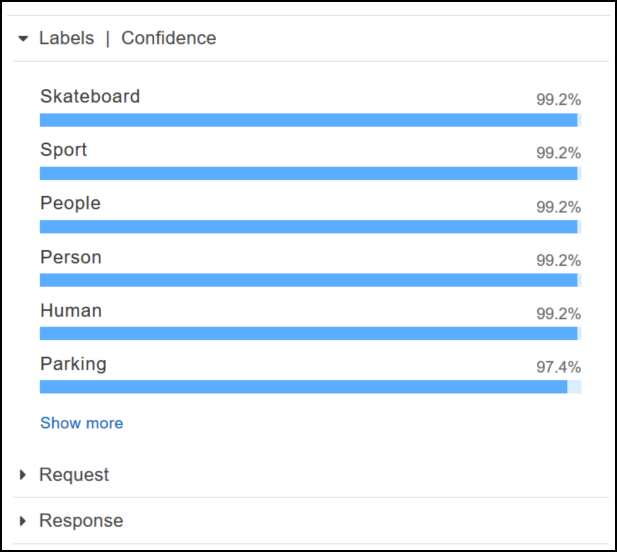
Para ver todas las puntuaciones de confianza que se muestran en esta respuesta, elija Show more (Mostrar más) en el panel Labels | Confidence (Etiquetas | Confianza).
También puedes ver la solicitud API y la respuesta del mismo API como referencia.
Solicitud
{ "contentString":{ "Attributes":[ "ALL" ], "Image":{ "S3Object":{ "Bucket":"console-sample-images", "Name":"skateboard.jpg" } } } }
Respuesta
{ "Labels":[ { "Confidence":99.25359344482422, "Name":"Skateboard" }, { "Confidence":99.25359344482422, "Name":"Sport" }, { "Confidence":99.24723052978516, "Name":"People" }, { "Confidence":99.24723052978516, "Name":"Person" }, { "Confidence":99.23908233642578, "Name":"Human" }, { "Confidence":97.42484283447266, "Name":"Parking" }, { "Confidence":97.42484283447266, "Name":"Parking Lot" }, { "Confidence":91.53300476074219, "Name":"Automobile" }, { "Confidence":91.53300476074219, "Name":"Car" }, { "Confidence":91.53300476074219, "Name":"Vehicle" }, { "Confidence":76.85114288330078, "Name":"Intersection" }, { "Confidence":76.85114288330078, "Name":"Road" }, { "Confidence":76.21503448486328, "Name":"Boardwalk" }, { "Confidence":76.21503448486328, "Name":"Path" }, { "Confidence":76.21503448486328, "Name":"Pavement" }, { "Confidence":76.21503448486328, "Name":"Sidewalk" }, { "Confidence":76.21503448486328, "Name":"Walkway" }, { "Confidence":66.71541595458984, "Name":"Building" }, { "Confidence":62.04711151123047, "Name":"Coupe" }, { "Confidence":62.04711151123047, "Name":"Sports Car" }, { "Confidence":61.98909378051758, "Name":"City" }, { "Confidence":61.98909378051758, "Name":"Downtown" }, { "Confidence":61.98909378051758, "Name":"Urban" }, { "Confidence":60.978023529052734, "Name":"Neighborhood" }, { "Confidence":60.978023529052734, "Name":"Town" }, { "Confidence":59.22066116333008, "Name":"Sedan" }, { "Confidence":56.48063278198242, "Name":"Street" }, { "Confidence":54.235477447509766, "Name":"Housing" }, { "Confidence":53.85226058959961, "Name":"Metropolis" }, { "Confidence":52.001792907714844, "Name":"Office Building" }, { "Confidence":51.325313568115234, "Name":"Suv" }, { "Confidence":51.26075744628906, "Name":"Apartment Building" }, { "Confidence":51.26075744628906, "Name":"High Rise" }, { "Confidence":50.68067932128906, "Name":"Pedestrian" }, { "Confidence":50.59548568725586, "Name":"Freeway" }, { "Confidence":50.568580627441406, "Name":"Bumper" } ] }
Para obtener más información, consulte Cómo funciona Amazon Rekognition.
Detectar objetos y escenas en una imagen proporcionada por el usuario
Puede cargar una imagen de su propiedad o proporcionarla URL a una imagen como entrada en la consola de Amazon Rekognition. Amazon Rekognition devuelve el objeto y las escenas y las puntuaciones de confianza de cada objeto y escena que detecta en la imagen proporcionada.
nota
La imagen debe tener un tamaño inferior a 5 MB y debe tener un formato similar. JPEG PNG
Para detectar objetos y escenas en una imagen proporcionada por el usuario
Abra la consola Amazon Rekognition en. https://console.aws.amazon.com/rekognition/
Elija Detección de etiquetas.
Realice una de las siguientes acciones siguientes:
Suba una imagen: elija Upload, vaya a la ubicación donde guardó la imagen y selecciónela.
Use unaURL: escriba la URL en el cuadro de texto y, a continuación, elija Ir.
Consulte la puntuación de confianza de cada etiqueta detectada en el panel Labels | Confidence.
Para obtener más opciones de análisis de imágenes, consulte Trabajar con imágenes.
Detecte personas y objetos en un vídeo que proporcione
Puede subir un vídeo que proporciona como entrada en la consola de Amazon Rekognition. Amazon Rekognition devuelve las personas, los objetos y las etiquetas detectadas en el vídeo.
nota
El vídeo de demostración no debe tener más de un minuto de duración ni más de 30 MB. Debe estar en formato de MP4 archivo y estar codificado con el códec H.264.
Para detectar personas y objetos en un vídeo que proporcione
Abra la consola Amazon Rekognition en. https://console.aws.amazon.com/rekognition/
Seleccione Análisis de vídeo almacenado en la barra de navegación.
En Elija una muestra o cargue la suya propia, seleccione Su propio vídeo en el menú desplegable.
Arrastre y suelte el vídeo o selecciónelo en la ubicación en la que lo guardó.
Para obtener más opciones de análisis de vídeo, consulte Trabaje con operaciones de análisis de vídeo almacenado o Trabajar con eventos de vídeo en streaming.
