Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Informe de exploración de datos de Piloto automático
Amazon SageMaker Autopilot limpia y preprocesa el conjunto de datos automáticamente. Los datos de alta calidad mejoran la eficiencia del machine learning y generan modelos que permiten realizar predicciones más precisas.
Algunos problemas relacionados con los conjuntos de datos proporcionados por los clientes no se pueden solucionar automáticamente sin contar con conocimientos sobre la materia. Los valores atípicos grandes en la columna objetivo para problemas de regresión, por ejemplo, pueden provocar predicciones subóptimas para los valores no atípicos. Es posible que sea necesario eliminar los valores atípicos según el objetivo del modelado. Si una columna objetivo se incluye por accidente como una de las características de entrada, el modelo final se validará bien, pero tendrá poco valor para futuras predicciones.
Para ayudar a los clientes a descubrir este tipo de problemas, Piloto automático proporciona un informe de exploración de datos que contiene información sobre los posibles problemas con sus datos. El informe también sugiere cómo abordar los problemas.
En todos los trabajos de Piloto automático, se genera un cuaderno de exploración de datos con dicho informe. El informe se almacena en un bucket de Amazon S3 y se puede acceder a él desde su ruta de salida. La ruta del informe de exploración de datos suele seguir el siguiente patrón.
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMaker AIAutopilotDataExplorationNotebook.ipynb
La ubicación del cuaderno de exploración de datos se puede obtener de la API del piloto automático mediante la respuesta de la DescribeAutoMLJoboperación, que se almacena en. DataExplorationNotebookLocation
Al ejecutar el piloto automático desde SageMaker Studio Classic, puede abrir el informe de exploración de datos siguiendo estos pasos:
-
Seleccione el icono
 de inicio en el panel de navegación izquierdo para ver el menú de navegación de nivel superior de Amazon SageMaker Studio Classic.
de inicio en el panel de navegación izquierdo para ver el menú de navegación de nivel superior de Amazon SageMaker Studio Classic. -
Seleccione la tarjeta AutoML en el área de trabajo principal. Se abrirá una nueva pestaña Piloto automático.
-
En la sección Nombre, seleccione el trabajo de Piloto automático que contiene el cuaderno de exploración de datos que desea examinar. Se abrirá una nueva pestaña Trabajo de piloto automático.
-
Seleccione Abrir cuaderno de exploración de datos en la sección superior derecha de la pestaña Trabajo de piloto automático.
El informe de exploración de datos se genera a partir de sus datos antes de que comience el proceso de entrenamiento. Esto le permite detener los trabajos de Piloto automático que podrían generar resultados irrelevantes. Del mismo modo, puede abordar cualquier problema o mejora en el conjunto de datos antes de volver a ejecutar Piloto automático. De esta forma, puede utilizar su experiencia para mejorar la calidad de los datos de forma manual y entrenar así al modelo con un conjunto de datos que esté más preparado.
El informe de datos solo contiene reducciones estáticas y se puede abrir en cualquier entorno de Jupyter. El cuaderno que contiene el informe se puede convertir a otros formatos, como PDF o HTML. Para obtener más información sobre las conversiones, consulte Using the nbconvert script to convert Jupyter notebooks to other formats
Temas
Resumen de conjunto de datos
Este Resumen de conjunto de datos proporciona estadísticas clave que caracterizan su conjunto de datos, como el número de filas, el número de columnas, el porcentaje de filas duplicadas y los valores objetivo que faltan. Su objetivo es proporcionarle una alerta rápida cuando haya algún problema con su conjunto de datos que Amazon SageMaker Autopilot haya detectado y que pueda requerir su intervención. La información se presenta como advertencias que se clasifican en gravedad “alta” o “baja”. La clasificación depende del nivel de confianza que existe en que el problema afectará negativamente al rendimiento del modelo.
Los datos de gravedad alta y baja aparecen en el resumen en forma de ventanas emergentes. Para la mayoría de los datos, se ofrecen recomendaciones sobre cómo confirmar que existe un problema con el conjunto de datos que requiere su atención. También hay propuestas sobre cómo resolver los problemas.
Piloto automático proporciona estadísticas adicionales sobre los valores objetivo que faltan o no son válidos en nuestro conjunto de datos, para ayudarle a detectar otros problemas que tal vez no se capten con información de gravedad alta. Un número inesperado de columnas de un tipo concreto podría indicar que es posible que algunas columnas que desee utilizar no estén incluidas en el conjunto de datos. También podría indicar que hubo un problema con la forma en que se prepararon o almacenaron los datos. Si se solucionan los problemas de datos detectados por Piloto automático, se puede mejorar el rendimiento de los modelos de machine learning basados en los datos.
La información sobre gravedad alta se muestra en la sección de resumen y en otras secciones relevantes del informe. Por lo general, se proporcionan ejemplos de información de gravedad alta y baja según la sección del informe de datos.
Análisis de objetivos
En esta sección, se muestran varios datos de gravedad alta y baja relacionados con la distribución de los valores en la columna objetivo. Compruebe que la columna objetivo contenga los valores correctos. Los valores incorrectos en la columna objetivo probablemente den como resultado un modelo de machine learning que no sirva para el propósito comercial previsto. En esta sección, se incluyen varios datos de alta y baja gravedad. A continuación, se presentan varios ejemplos.
-
Valores objetivo atípicos: distribución objetivo asimétrica o sesgada para la regresión, como los lugares con una alta probabilidad de valores atípicos.
-
Cardinalidad objetivo alta o baja: número poco frecuente de etiquetas de clase o un gran número de clases únicas para la clasificación.
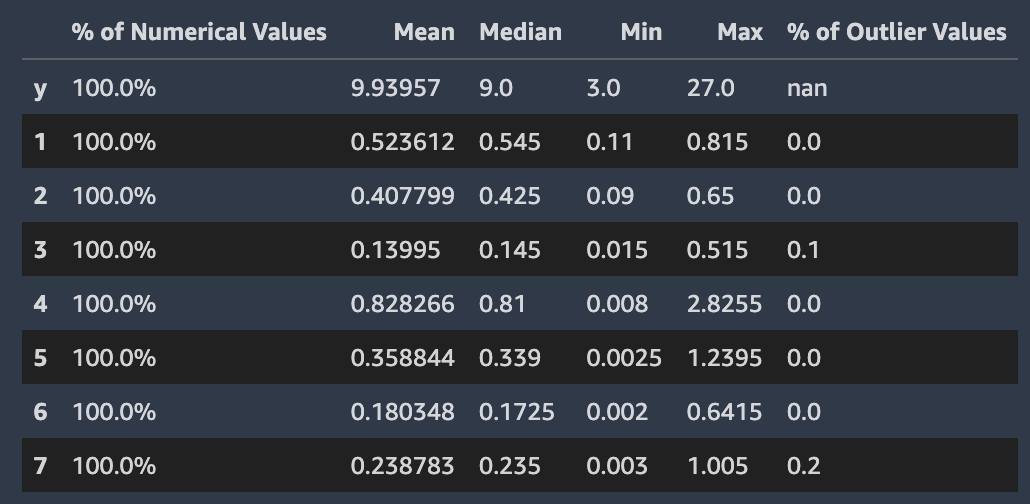
Tanto para los tipos de problemas de regresión como los de clasificación, aparecen valores no válidos, como el infinito numérico, NaN o un espacio vacío en la columna de destino. Según el tipo de problema, se presentan diferentes estadísticas del conjunto de datos. Una distribución de los valores de las columnas objetivo para un problema de regresión le permite verificar si la distribución es la que esperaba.
La siguiente captura de pantalla muestra un informe de datos de Piloto automático, que incluye estadísticas como la media, la mediana, el mínimo, el máximo y el porcentaje de valores atípicos del conjunto de datos. La captura de pantalla también incluye un histograma que muestra la distribución de las etiquetas en la columna de destino. En el histograma, se muestran los valores de la columna objetivo en el eje horizontal y el recuento en el eje vertical. Un cuadro resalta la sección Porcentaje de valores atípicos de la captura de pantalla para indicar dónde aparece esta estadística.
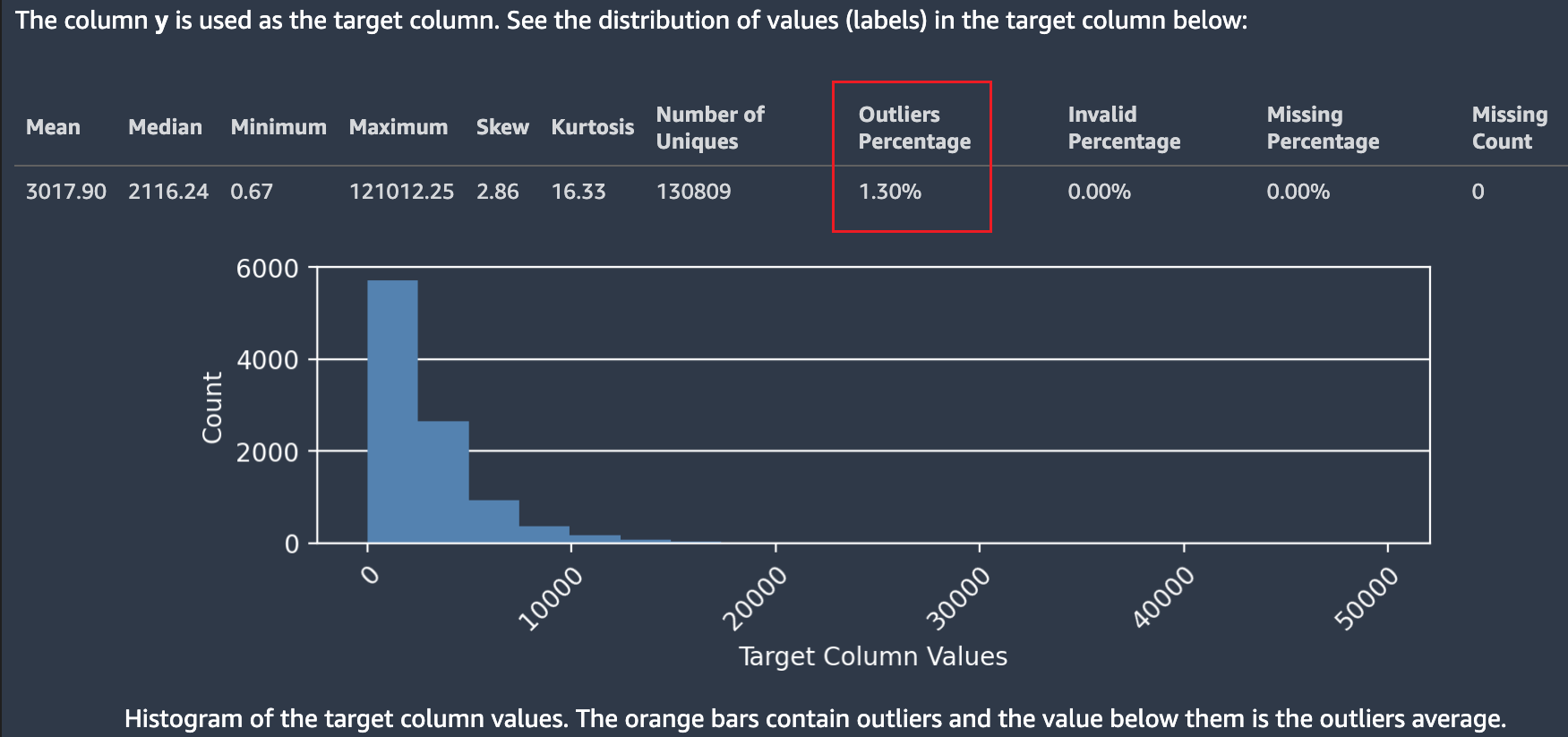
Hay varias estadísticas sobre los valores objetivo y su distribución. Si alguno de los valores atípicos, valores no válidos o porcentajes faltantes es superior a cero, estos valores aparecen para que pueda investigar por qué sus datos contienen valores objetivo inutilizables. Algunos valores objetivo inutilizables aparecen resaltados como una advertencia de gravedad baja.
En la siguiente captura de pantalla, se ha añadido accidentalmente un símbolo ` a la columna de destino, lo que impidió analizar el valor numérico del objetivo. Aparece el aviso Datos de gravedad baja: “Valores objetivo no válidos”. La advertencia de este ejemplo dice lo siguiente: “El 0,14 % de las etiquetas de la columna de destino no se ha podido convertir a valores numéricos. Los valores no numéricos más comunes son ["-3,8e-05","-9-05","-4,7e-05","-1,4999999999999999e-05","-4,3e-05"]. Esto suele indicar que hay problemas con la recopilación o el procesamiento de los datos. Amazon SageMaker Autopilot ignora todas las observaciones cuya etiqueta de destino no sea válida».

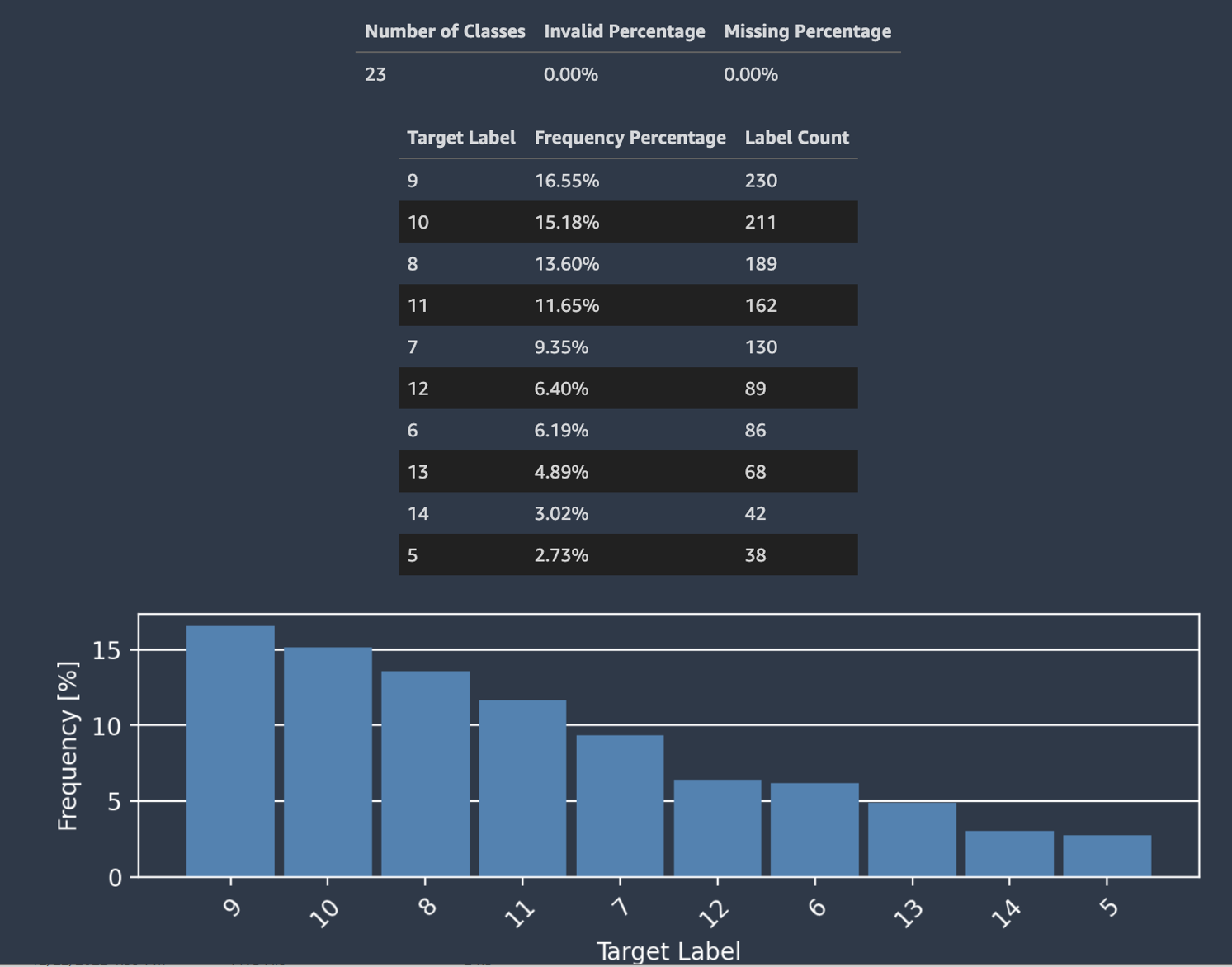
Piloto automático también proporciona un histograma que muestra la distribución de las etiquetas para su clasificación.
La siguiente captura de pantalla muestra un ejemplo de estadísticas proporcionadas para la columna de destino, incluido el número de clases y los valores faltantes o no válidos. Un histograma con la etiqueta de destino en el eje horizontal y la frecuencia en el eje vertical muestra la distribución de cada categoría de etiquetas.
nota
Puede encontrar las definiciones de todos los términos presentados en esta y otras secciones en la sección Definiciones, en la parte inferior del cuaderno de informes.
Ejemplo de datos
Piloto automático presenta una muestra real de sus datos para ayudarte a detectar problemas en el conjunto de datos. La tabla de muestra se desplaza horizontalmente. Inspeccione los datos de muestra para verificar que todas las columnas necesarias estén presentes en el conjunto de datos.
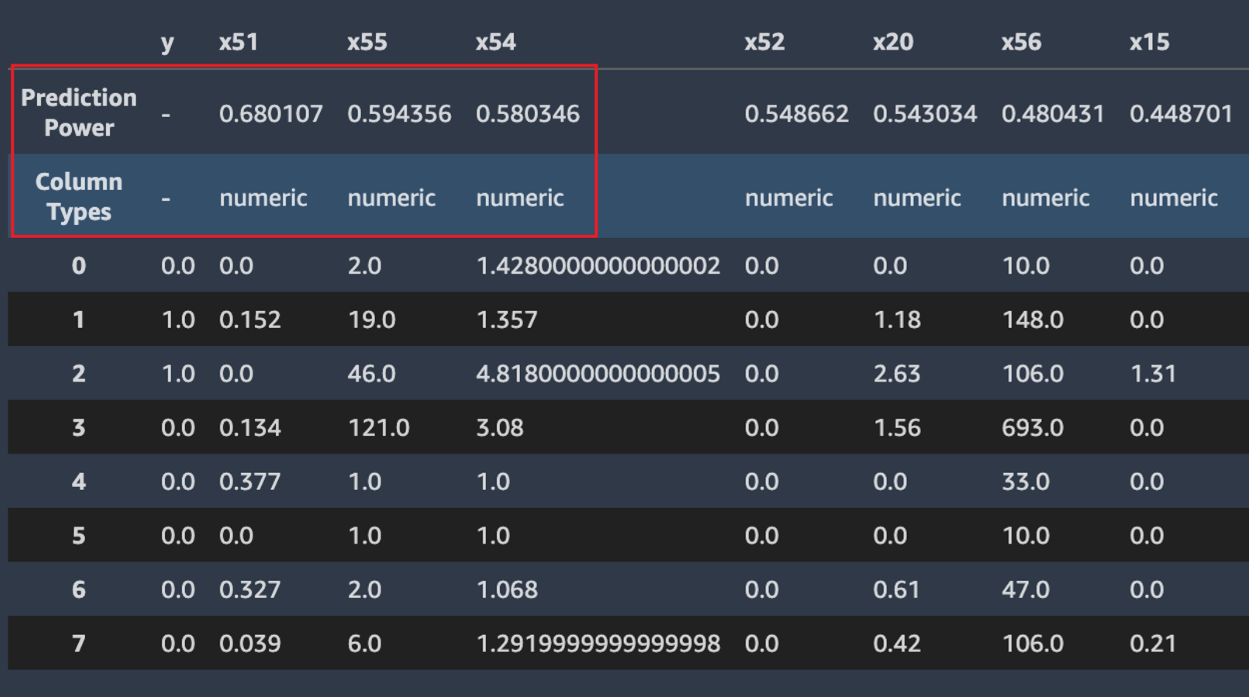
Piloto automático también calcula una medida de la potencia predictiva, que se puede utilizar para identificar una relación lineal o no lineal entre una característica y la variable objetivo. El valor 0 indica que la característica no tiene ningún valor predictivo para predecir la variable objetivo. Un valor 1 indica la potencia predictiva más alta para la variable objetivo. Para obtener más información sobre la potencia predictiva, consulte la sección Definiciones.
nota
No es recomendable utilizar la potencia predictiva como sustituto de la importancia de las características. Úsela solo si está seguro de que la potencia predictiva es una medida adecuada para el caso de uso en particular.
En la siguiente captura de pantalla, se ve un ejemplo de muestra de datos. La fila superior contiene la potencia predictiva de cada columna del conjunto de datos. La segunda fila contiene el tipo de datos de la columna. Las filas siguientes contienen las etiquetas. Las columnas contienen la columna de destino seguida de cada columna de características. Cada columna de características tiene una potencia predictiva asociada (resaltada en esta captura de pantalla con un recuadro). En este ejemplo, la columna que contiene la característica x51 tiene una potencia predictiva de 0.68 para la variable objetivo y. La característica x55 es ligeramente menos predictiva: tiene una potencia predictiva de 0.59.
Filas duplicadas
Si hay filas duplicadas en el conjunto de datos, Amazon SageMaker Autopilot muestra una muestra de ellas.
nota
No se recomienda equilibrar un conjunto de datos con un sobremuestreo antes de proporcionárselo a Piloto automático. Esto puede provocar que las puntuaciones de validación de los modelos entrenados con Piloto automático sean inexactas y que los modelos que se produzcan queden inutilizables.
Correlaciones entre columnas
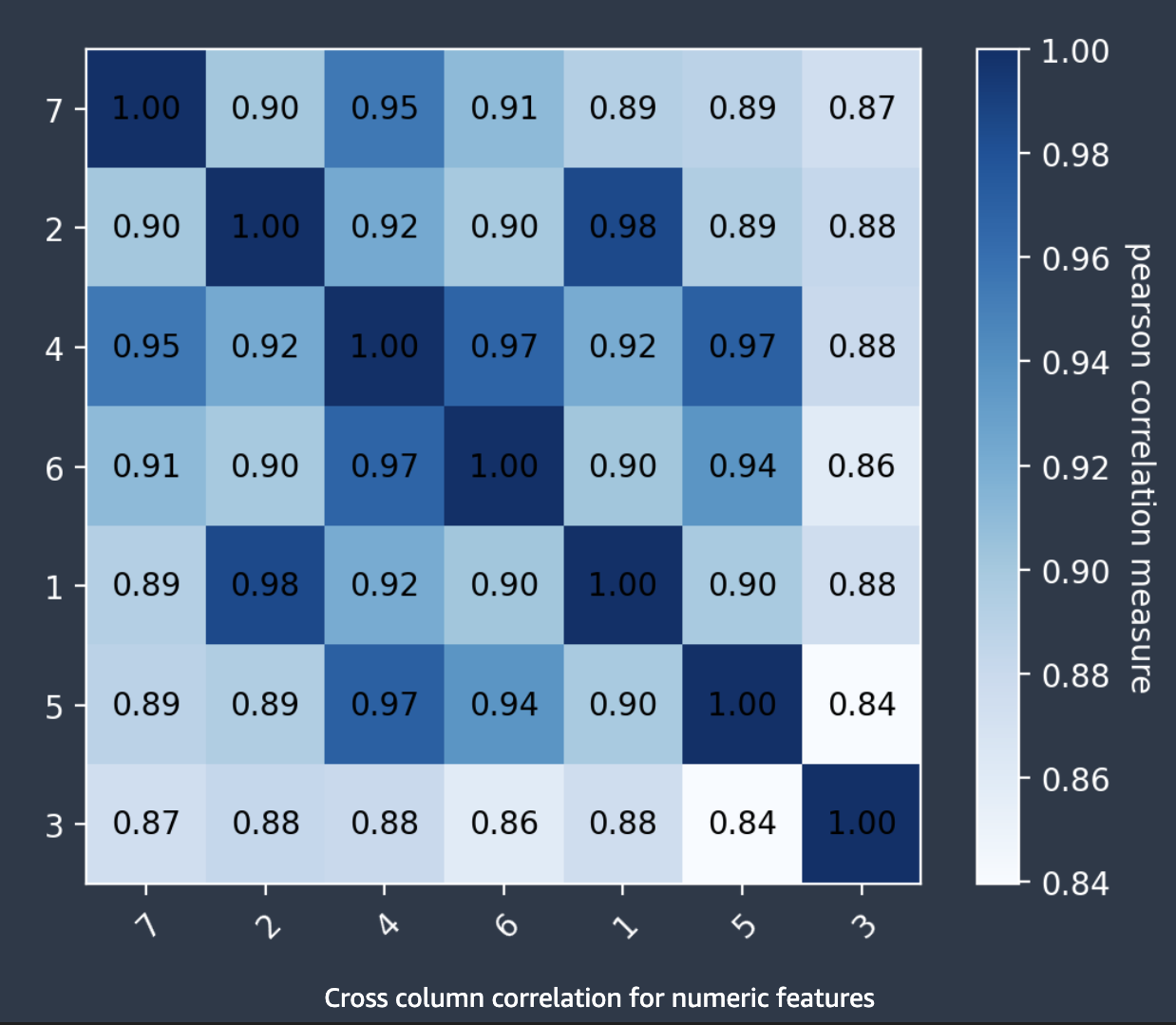
Piloto automático utiliza el coeficiente de correlación de Pearson, una medida de la correlación lineal entre dos características, para rellenar una matriz de correlación. En la matriz de correlación, las características numéricas se representan en los ejes horizontal y vertical, y el coeficiente de correlación de Pearson se representa en sus intersecciones. Cuanto mayor sea la correlación entre dos características, mayor será el coeficiente, con un valor máximo de |1|.
-
Un valor de
-1indica que las características están perfectamente correlacionadas negativamente. -
Un valor de
1, que ocurre cuando una característica está correlacionada consigo misma, indica una correlación positiva perfecta.
Puede utilizar la información de la matriz de correlación para eliminar las características con un nivel alto de correlación. Un número menor de características reduce las posibilidades de sobreajustar un modelo; además, puede contribuir a abaratar los costes de producción de dos maneras. Reduce el tiempo de ejecución de Piloto automático necesario y, en el caso de algunas aplicaciones, puede abaratar los procedimientos de recopilación de datos.
En la siguiente captura de pantalla, se muestra un ejemplo de matriz de correlación entre 7 características. Cada característica se muestra en una matriz en los ejes horizontal y vertical. El coeficiente de correlación de Pearson se muestra en la intersección entre dos características. Cada intersección de características tiene un tono de color asociado. Cuanto mayor sea la correlación, más oscuro será el tono. Los tonos más oscuros ocupan la diagonal de la matriz, donde cada característica se correlaciona consigo misma, lo que representa una correlación perfecta.
Filas anómalas
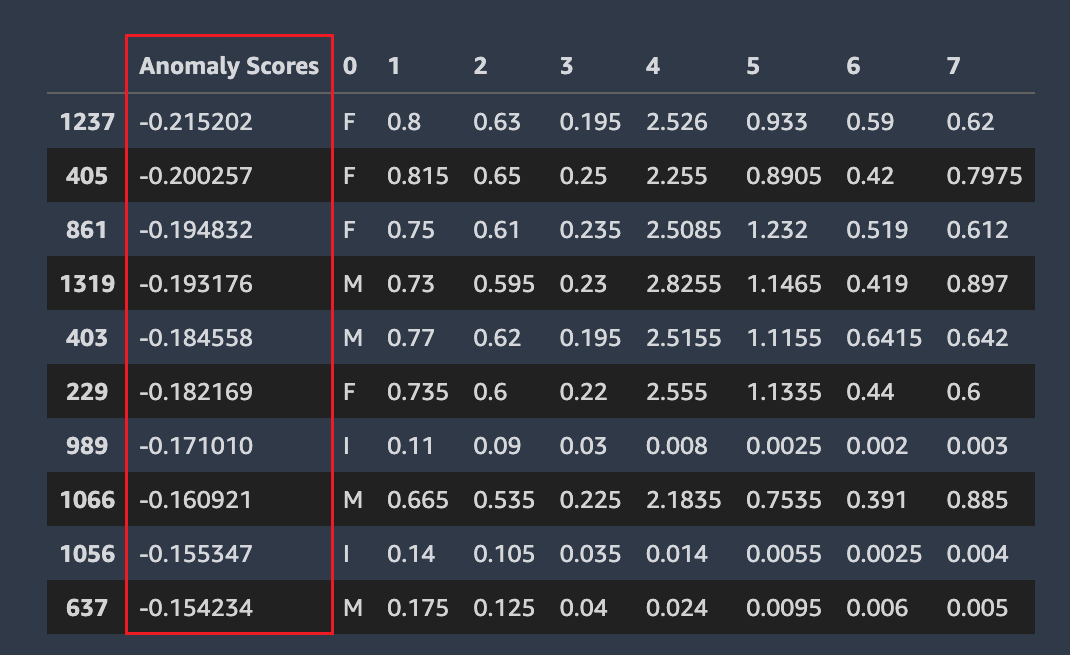
Amazon SageMaker Autopilot detecta qué filas del conjunto de datos pueden ser anómalas. A continuación, asigna una puntuación de anomalía a cada fila. Las filas con puntuaciones de anomalía negativas se consideran anómalas.
La siguiente captura de pantalla muestra el resultado de un análisis de Piloto automático para las filas que contienen anomalías. Junto a las columnas del conjunto de datos de cada fila, aparece una columna que contiene una puntuación anómala.
Valores que faltan, cardinalidad y estadísticas descriptivas
Amazon SageMaker Autopilot examina e informa sobre las propiedades de las columnas individuales de su conjunto de datos. En cada sección del informe de datos que presenta este análisis, el contenido está organizado. De este modo, puede comprobar primero los valores más “sospechosos”. Con estas estadísticas, puede mejorar el contenido de las columnas individuales y la calidad del modelo producido por Piloto automático.
Piloto automático calcula varias estadísticas sobre los valores categóricos en las columnas que los contienen. Esto incluye el número de entradas únicas y, para texto, el número de palabras únicas.
Piloto automático calcula varias estadísticas estándar sobre los valores numéricos en las columnas que los contienen. La siguiente imagen muestra estas estadísticas, lo que incluye los valores medio, mediano, mínimo y máximo, así como los porcentajes de los tipos numéricos y de los valores atípicos.