Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Asociar los resultados de la predicción con registros de entrada
Al hacer predicciones sobre un conjunto de datos de gran tamaño, podrá excluir los atributos que no sean necesarios para la predicción. Una vez que se hayan hecho las predicciones, podrá asociar algunos de los atributos excluidos con esas predicciones o con los datos de entrada del informe. Al usar la transformación por lotes para seguir estos pasos de procesamiento de datos, a menudo podrá eliminar el procesamiento previo o posterior adicional. Solo podrá usar archivos de entrada en formato JSON y CVS.
Temas
Flujo de trabajo de asociación de inferencias a registros de entrada
En el siguiente diagrama se muestra el flujo de trabajo de asociación de inferencias a registros de entrada.
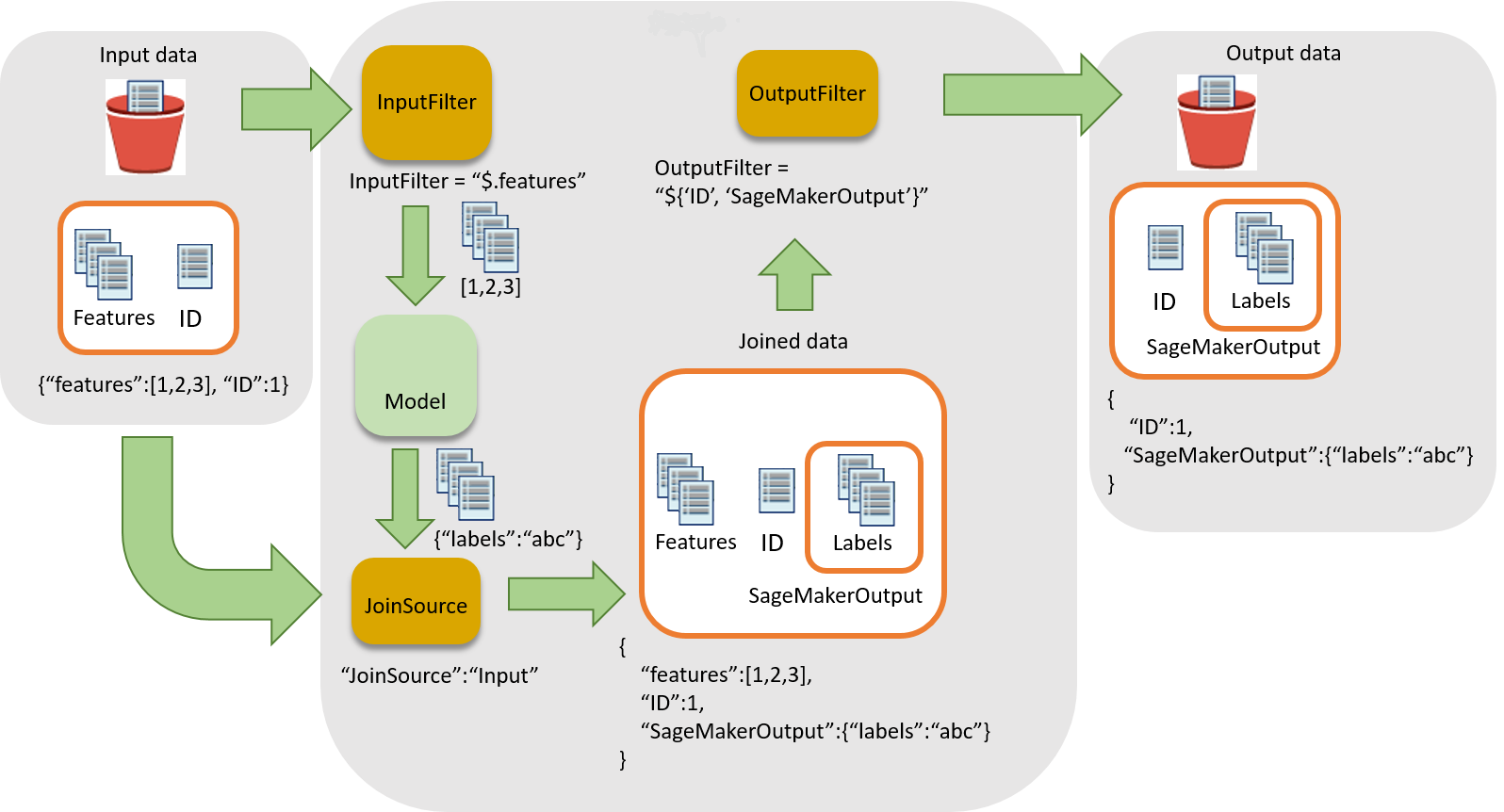
Para asociar inferencias a datos de entrada, existen tres pasos principales:
-
Filtre los datos de entrada que no sean necesarios para la inferencia antes de transferirlos al trabajo de transformación por lotes. Use el parámetro
InputFilterpara determinar qué atributos se deben usar como entrada para el modelo. -
Asocie los datos de entrada con los resultados de la inferencia. Use el parámetro
JoinSourcepara combinar los datos de entrada con la inferencia. -
Filtre los datos unidos a fin de conservar las entradas necesarias para proporcionar contexto para la interpretación de las predicciones en los informes. Use
OutputFilterpara almacenar la parte especificada del conjunto de datos unido en el archivo de salida.
Uso del procesamiento de datos en los trabajos de transformación por lotes
Al crear un trabajo de transformación por lotes con CreateTransformJob para procesar datos:
-
Especifique la parte de la entrada que se va a transferir al modelo con el parámetro
InputFilteren la estructura de datosDataProcessing. -
Una los datos de entrada sin procesar con los datos transformados con el parámetro
JoinSource. -
Especifique qué parte de los datos transformados y de entrada unidos del trabajo de transformación por lotes se va a incluir en el archivo de salida con el parámetro
OutputFilter. -
Elija archivos JSON o CSV-formatted archivos para la entrada:
-
En el caso de los archivos Lines-formatted de entrada JSON o JSON, la SageMaker IA añade el
SageMakerOutputatributo al archivo de entrada o crea un nuevo archivo de salida JSON con losSageMakerOutputatributosSageMakerInputy. Para obtener más información, consulteDataProcessing. -
En el CSV-formatted caso de los archivos de entrada, los datos de entrada unidos van seguidos de los datos transformados y la salida es un archivo CSV.
-
Si usa un algoritmo con la estructura DataProcessing, debe admitir su formato elegido tanto para los archivos de entrada como para los de salida. Por ejemplo, con el campo TransformOutput de la API CreateTransformJob, debe establecer los parámetros ContentType y Accept a uno de los siguientes valores: text/csv, application/json o application/jsonlines. La sintaxis para especificar columnas en un archivo CSV es distinta de la sintaxis para especificar atributos en un archivo JSON. El uso de la sintaxis incorrecta provoca un error. Para obtener más información, consulte Ejemplos de transformación por lotes. Para obtener más información acerca de los formatos de archivo de entrada y salida para los algoritmos integrados, consulte Built-in algoritmos y modelos previamente entrenados en Amazon SageMaker.
Los delimitadores de registro para la entrada y la salida también deben ser consistentes con su entrada de archivo elegida. El parámetro SplitType indica cómo dividir los registros en el conjunto de datos de entrada. El parámetro AssembleWith indica cómo volver a ensamblar los registros para la salida. Si establece formatos de entrada y salida en text/csv, también deberá establecer los parámetros SplitType y AssembleWith en line. Si define los formatos de entrada y salida en application/jsonlines, podrá establecer SplitType y AssembleWith en line.
En el caso de los archivos CSV, no puede utilizar caracteres de nueva línea incrustados. Para los archivos JSON, el nombre de atributo SageMakerOutput se reserva para la salida. El archivo de entrada JSON no puede tener un atributo con este nombre. Si lo tiene, los datos del archivo de entrada podrían sobrescribirse.
Operadores JSONPath admitidos
Para filtrar y unir los datos de entrada y la inferencia, use una subexpresión JSONPath. SageMaker AI solo admite un subconjunto de los operadores JSONPath definidos. En la siguiente tabla se muestran los operadores JSONPath admitidos. Para los datos CSV, cada fila se considera como una matriz JSON, de manera que solo se puede aplicar JSONPaths basados en índices, como por ejemplo $[0], $[1:]. Los datos CSV también deben seguir el formato RFC
| Operador JSONPath | Description (Descripción) | Ejemplo |
|---|---|---|
$ |
El elemento raíz para una consulta. Este operador es necesario al principio de todas las expresiones de ruta. |
$ |
. |
Un elemento secundario con notación de puntos. |
|
* |
Un comodín. Úselo en lugar de un nombre de atributo o valor numérico. |
|
[' |
Un elemento con notación de corchete o varios elementos secundarios. |
|
[ |
Un índice o una matriz de índices. También se admiten valores de índice negativos. Un índice |
|
[ |
Un operador Slice de la matriz. El método Slice() de la matriz extrae una sección de una matriz y devuelve una nueva matriz. Si se omite |
|
Cuando se utiliza la notación de corchetes para especificar varios elementos secundarios de un campo determinado, no se permite el anidamiento adicional de elementos secundarios dentro de los corchetes. Por ejemplo, $.field1.['child1','child2'] sí se admite, pero $.field1.['child1','child2.grandchild'] no.
Para obtener más información sobre los operadores de JSONPath, consulte. JsonPath
Ejemplos de transformación por lotes
En los siguientes ejemplos se muestran algunas formas habituales de unir los datos de entrada con los resultados de la predicción.
Temas
Ejemplo: generación de inferencias solamente
De forma predeterminada, el parámetro DataProcessing no une los resultados de la inferencia con la entrada. Solo genera los resultados de la inferencia.
Si desea especificar de forma explícita que no se unan los resultados con la entrada, utilice el SDK de Amazon SageMaker Python
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
Para generar inferencias con el AWS SDK para Python, agrega el siguiente código a tu CreateTransformJob solicitud. El siguiente código imita el comportamiento predeterminado.
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
Ejemplo: inferencias de salida unidas a datos de entrada
Si utiliza el SDK de Amazon SageMaker Pythonaccept parámetros assemble_with y al inicializar el objeto transformador. Cuando utilice la llamada de transformación, especifique Input para el parámetro join_source y especifique también los parámetros split_type y content_type. El parámetro split_type debe tener el mismo valor que assemble_with, y el parámetro content_type debe tener el mismo valor que accept. Para obtener más información sobre los parámetros y sus valores aceptados, consulte la página Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
Si utilizas el AWS SDK para Python (Boto 3), une todos los datos de entrada con la inferencia añadiendo el siguiente código a tu CreateTransformJobsolicitud. Los valores de Accept y ContentType deben coincidir, y los valores de AssembleWith y SplitType también deben coincidir.
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Para los archivos de entrada JSON o de líneas de JSON, los resultados están en la clave SageMakerOutput del archivo JSON de entrada. Por ejemplo, si la entrada es un archivo JSON que incluye el par clave-valor {"key":1}, el resultado de la transformación de los datos puede ser {"label":1}.
SageMaker AI almacena ambos en el archivo de entrada de la SageMakerInput clave.
{ "key":1, "SageMakerOutput":{"label":1} }
nota
El resultado unido para JSON debe ser un objeto de par clave-valor. Si la entrada no es un objeto de par clave-valor, SageMaker AI crea un nuevo archivo JSON. En el nuevo archivo JSON, los datos de entrada se almacenan en la clave SageMakerInput, mientras que los resultados se almacenan como el valor SageMakerOutput.
Para un archivo CSV, por ejemplo, si el registro es [1,2,3] y el resultado de la etiqueta es [1], el archivo de salida incluiría [1,2,3,1].
Ejemplo: inferencias de salida unidas a datos de entrada y exclusión de la columna de ID de la entrada (CSV)
Si utiliza el SDK de Amazon SageMaker Pythoninput_filter in your transformer. Por ejemplo, si en sus datos de entrada se incluyen cinco columnas y la primera es la columna ID, use la siguiente solicitud del transformador para seleccionar todas las columnas excepto la columna ID como características. El transformador sigue emitiendo todas las columnas de entrada unidas a las inferencias. Para obtener más información sobre los parámetros y sus valores aceptados, consulte la página Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
Si utilizas el AWS SDK para Python (Boto 3), añade el siguiente código a tu
CreateTransformJob solicitud.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Para especificar columnas en SageMaker AI, usa el índice de los elementos de la matriz. La primera columna es el índice 0, la segunda columna es el índice 1 y la sexta columna es el índice 5.
Para excluir la primera columna de la entrada, establezca InputFilter en "$[1:]". Los dos puntos (:) indican a SageMaker AI que incluya todos los elementos entre dos valores, ambos inclusive. Por ejemplo, $[1:4] especifica de la segunda a la quinta columnas.
Si omite el número después de los dos puntos, por ejemplo, [5:], el subconjunto incluye todas las columnas desde la sexta hasta la última columna. Si omite el número antes de los dos puntos, por ejemplo, [:5], el subconjunto incluye todas las columnas desde la primera columna (índice 0) hasta la sexta columna.
Ejemplo: inferencias de salida unidas con una columna ID y exclusión de la columna ID de la entrada (CSV)
Si utiliza el SDK de Amazon SageMaker Pythonoutput_filter en la llamada al transformador. El output_filter utiliza una subexpresión de JSONPath para especificar qué columnas se devolverán como salida después de unir los datos de entrada con los resultados de la inferencia. La siguiente solicitud muestra cómo hacer predicciones excluyendo una columna de ID y, a continuación, uniendo la columna de ID a las inferencias. Tenga en cuenta que, en el siguiente ejemplo, la última columna (-1) de la salida contiene las inferencias. Si utiliza archivos JSON, la SageMaker IA almacena los resultados de la inferencia en el atributo. SageMakerOutput Para obtener más información sobre los parámetros y sus valores aceptados, consulte la página Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
Si utilizas el AWS SDK para Python (Boto 3), añade el siguiente código a tu CreateTransformJobsolicitud para unir solo la columna ID con las inferencias.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
aviso
Si utilizas un archivo de JSON-formatted entrada, el archivo no puede contener el nombre del atributo. SageMakerOutput Este nombre de atributo se reserva para las inferencias en el archivo de salida. Si el archivo JSON-formatted de entrada contiene un atributo con este nombre, es posible que los valores del archivo de entrada se sobrescriban con la inferencia.
