Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Análisis y visualización
Amazon SageMaker Data Wrangler incluye análisis integrados que le ayudan a generar visualizaciones y análisis de datos con unos pocos clics. También puede crear análisis personalizados con su propio código.
Para agregar un análisis a un marco de datos, seleccione un paso del flujo de datos y, a continuación, elija Agregar análisis. Para acceder a un análisis que haya creado, seleccione el paso que contiene el análisis y seleccione el análisis.
Todos los análisis se generan con 100 000 filas de su conjunto de datos.
Puede agregar los análisis siguientes a un marco de datos:
-
Visualizaciones de datos, incluidos histogramas y gráficos de dispersión.
-
Un resumen rápido del conjunto de datos, que incluye el número de entradas, los valores mínimo y máximo (para los datos numéricos) y las categorías más y menos frecuentes (para los datos categóricos).
-
Un modelo rápido del conjunto de datos, que se puede utilizar para generar una puntuación de importancia para cada característica.
-
Un informe de fuga de objetivos, que puede utilizar para determinar si una o más características están estrechamente correlacionadas con la característica objetivo.
-
Una visualización personalizada con su propio código.
Utilice las siguientes secciones para obtener más información sobre estas opciones.
Histograma
Utilice los histogramas para ver los recuentos de los valores de las características de una característica específica. Puede examinar las relaciones entre las características mediante la opción Colorear por. Por ejemplo, el siguiente histograma muestra la distribución de las valoraciones de los usuarios de los libros más vendidos en Amazon entre 2009 y 2019, coloreadas por género.

Puede usar la característica Facetas para crear histogramas de una columna para cada valor de otra columna. Por ejemplo, en el siguiente diagrama se muestran histogramas de las reseñas de los usuarios de los libros más vendidos en Amazon si se clasifican por año.

Gráfico de dispersión
Use la característica Gráfico de dispersión para examinar la relación entre las características. Para crear un gráfico de dispersión, seleccione una característica para representarla en el eje X y el eje Y. Ambas columnas deben ser columnas de tipo numérico.
Puede colorear los gráficos de dispersión mediante una columna adicional. Por ejemplo, en el siguiente ejemplo se muestra un gráfico de dispersión que compara el número de reseñas con las valoraciones de los usuarios de los libros más vendidos en Amazon entre 2009 y 2019. El gráfico de dispersión está coloreado por género literario.
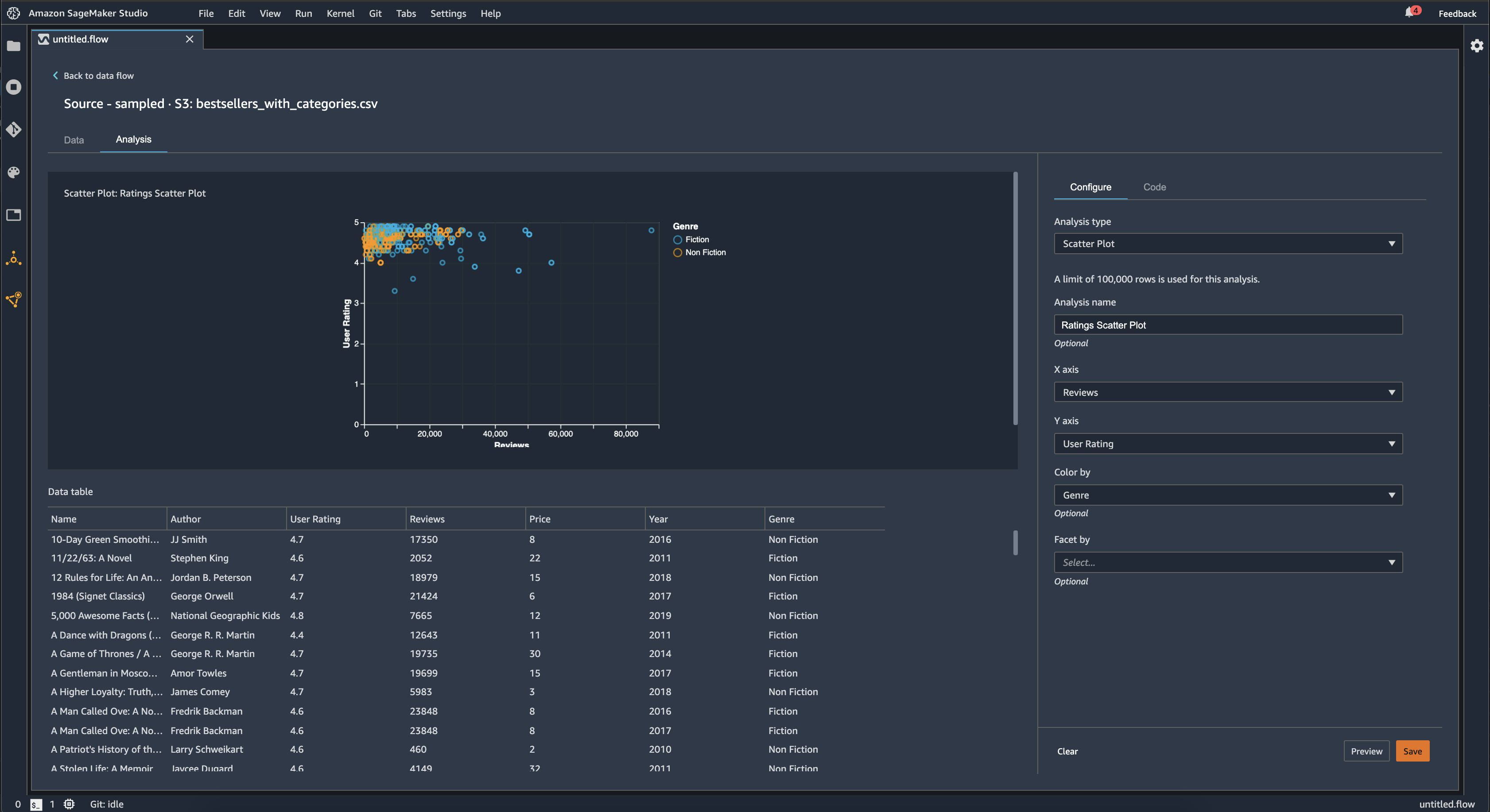
Además, puede ordenar los gráficos de dispersión por características. Por ejemplo, en la siguiente imagen se muestra un ejemplo del mismo gráfico de dispersión de reseñas frente a valoraciones de los usuarios, clasificado por año.

Resumen de la tabla
Utilice el análisis Resumen de la tabla para resumir rápidamente los datos.
Para las columnas con datos numéricos, incluidos los logarítmicos y datos flotantes, el resumen de la tabla indica el número de entradas (recuento), mínimo (mín.), máximo (máx.), media y desviación estándar (DE) de cada columna.
Para las columnas con datos no numéricos, incluidas las columnas con datos de cadena, booleanos o de fecha y hora, el resumen de la tabla indica el número de entradas (recuento), el valor menos frecuente (mín.) y el valor más frecuente (máx.).
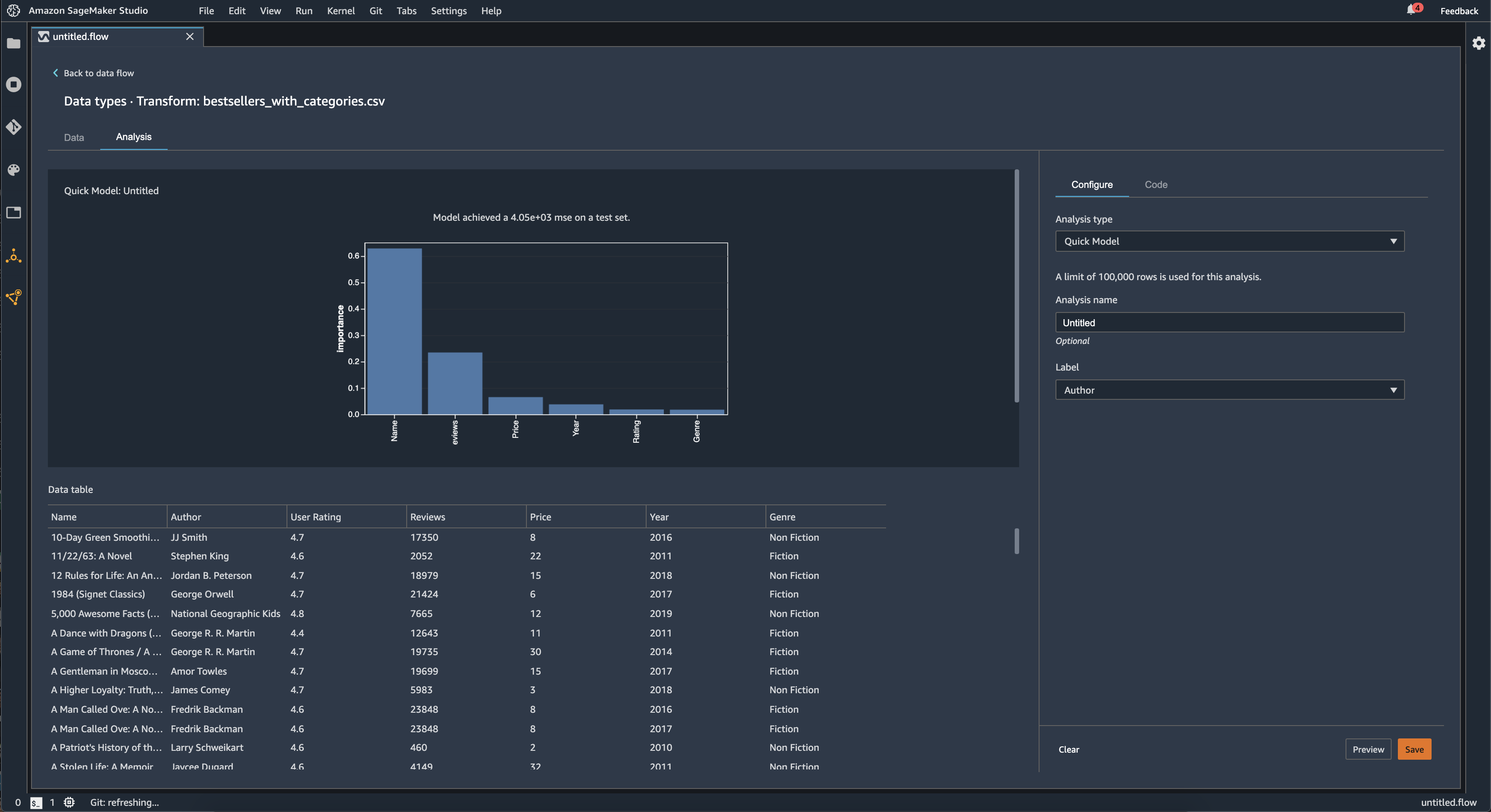
Modelo rápido
Utilice la visualización Modelo rápido para evaluar rápidamente los datos y generar puntuaciones de importancia para cada característica. Una Puntuación de importancia de la característica
Cuando crea un gráfico de modelo rápido, selecciona el conjunto de datos que desea evaluar y una etiqueta objetivo con la que desea comparar la importancia de las características. Data Wrangler hace lo siguiente:
-
Infiere los tipos de datos de la etiqueta objetivo y de cada característica del conjunto de datos seleccionado.
-
Determina el tipo de problema. En función del número de valores distintos de la columna de etiquetas, Data Wrangler determina si se trata de un problema de regresión o clasificación. Data Wrangler establece un umbral categórico en 100. Si hay más de 100 valores distintos en la columna de etiquetas, Data Wrangler lo clasifica como un problema de regresión; de lo contrario, se clasifica como un problema de clasificación.
-
Preprocesa las características y etiqueta los datos para el entrenamiento. El algoritmo utilizado requiere codificar las características con un tipo vectorial y codificar las etiquetas con un tipo doble.
-
Entrena un algoritmo de bosque aleatorio con un 70 % de datos. El RandomForestregresor
de Spark se utiliza para entrenar un modelo para problemas de regresión. El RandomForestclasificador se utiliza para entrenar un modelo para problemas de clasificación. -
Evalúa un modelo de bosque aleatorio con el 30 % restante de los datos. Data Wrangler evalúa los modelos de clasificación con una puntuación F1 y evalúa los modelos de regresión con una puntuación MSE.
-
Calcula la importancia de cada característica mediante el método de importancia de Gini.
En la imagen siguiente, se muestra la interfaz de usuario de la característica de modelo rápido.
Fuga de objetivos
La fuga de objetivos se produce cuando hay datos en un conjunto de datos de entrenamiento de machine learning que están estrechamente correlacionados con la etiqueta objetivo, pero que no están disponibles en los datos de la vida real. Por ejemplo, es posible que tenga una columna en su conjunto de datos que sirva como proxy de la columna que desea predecir con su modelo.
Al utilizar el análisis Fuga de objetivos, especifica lo siguiente:
-
Objetivo: esta es la característica sobre la que desea que su modelo de machine learning pueda realizar predicciones.
-
Tipo de problema: este es el tipo de problema de machine learning en el que está trabajando. El tipo de problema puede ser de clasificación o regresión.
-
(Opcional) Características máximas: es la cantidad máxima de características que se pueden presentar en la visualización, que muestra las características clasificadas según su riesgo de convertirse en una fuga de objetivos.
Para la clasificación, el análisis de fuga de objetivos utiliza el área bajo la curva de la característica operativa de receptor, o curva AUC-ROC para cada columna, hasta las Características máximas. Para la regresión, utiliza un coeficiente de determinación o métrica R2.
La curva AUC-ROC proporciona una métrica predictiva, calculada individualmente para cada columna mediante la validación cruzada, en una muestra de hasta 1000 filas aproximadamente. Una puntuación de 1 indica una capacidad predictiva perfecta, lo que a menudo es señal de una fuga de objetivos. Una puntuación igual o inferior a 0,5 indica que la información de la columna no puede proporcionar, por sí sola, ninguna información útil para predecir el objetivo. Aunque puede ocurrir que una columna no sea informativa por sí sola, pero que sea útil para predecir el objetivo cuando se utiliza junto con otras características, una puntuación baja podría indicar que la característica es redundante.
Por ejemplo, en la siguiente imagen se muestra un informe de fuga de objetivos para un problema de clasificación de la diabetes, es decir, para predecir si una persona tiene diabetes o no. Se utiliza una curva AUC–OC para calcular la capacidad predictiva de cinco características, y se determina que todas están a salvo de la fuga de objetivos.

Multicolinealidad
La multicolinealidad es una circunstancia en la que dos o más variables predictoras están relacionadas entre sí. Las variables predictoras son características del conjunto de datos que se utilizan para predecir una variable objetivo. Cuando tiene multicolinealidad, las variables predictoras no solo predicen la variable objetivo, sino que también se predicen entre sí.
Puede utilizar el factor de inflación de la varianza (VIF), el análisis de componentes principales (PCA) o la selección de características Lasso como medidas de la multicolinealidad de los datos. Para obtener más información, consulte lo siguiente.
Detección de anomalías en los datos de serie temporal
Puede utilizar la visualización de la detección de anomalías para ver los valores atípicos en los datos de serie temporal. Para entender qué es lo que determina una anomalía, debe entender que descomponemos la serie temporal en un término predicho y un término de error. La estacionalidad y la tendencia de la serie temporal se consideran el término predicho. Los residuos se tratan como el término de error.
Para el término de error, se especifica un umbral como el número de desviaciones estándar que el residuo puede alejarse de la media para que se considere una anomalía. Por ejemplo, puede especificar un umbral de 3 desviaciones estándar. Cualquier residuo que esté a más de 3 desviaciones estándar de la media es una anomalía.
Puede utilizar el siguiente procedimiento para realizar un análisis de Detección de anomalías.
-
Abra el flujo de datos de Data Wrangler.
-
En el flujo de datos, en Tipos de datos, elija el signo + y seleccione Agregar análisis.
-
En Tipo de análisis, elija Serie temporal.
-
En Visualización, elija Detección de anomalías.
-
En Umbral de anomalía, elija el umbral para que un valor se considera una anomalía.
-
Elija Vista previa para generar una vista previa del análisis.
-
Elija Agregar para agregar la transformación al flujo de datos de Data Wrangler.
Descomposición de tendencias estacionales en datos de serie temporal
Puede determinar si hay estacionalidad en sus datos de serie temporal mediante la visualización de la descomposición de tendencias estacionales. Para realizar la descomposición, se usa el método STL (descomposición de tendencias estacionales mediante LOESS). La serie temporal se descompone en sus componentes estacionales, tendenciales y residuales. La tendencia refleja la progresión a largo plazo de la serie. El componente estacional es una señal que se repite en un período de tiempo. Tras eliminar los componentes estacionales y tendenciales de la serie temporal, se obtiene el residuo.
Puede utilizar el siguiente procedimiento para realizar un análisis de descomposición de la tendencia estacional.
-
Abra el flujo de datos de Data Wrangler.
-
En el flujo de datos, en Tipos de datos, elija el signo + y seleccione Agregar análisis.
-
En Tipo de análisis, elija Serie temporal.
-
En Visualización, elija Descomposición de tendencias estacionales.
-
En Umbral de anomalía, elija el umbral para que un valor se considera una anomalía.
-
Elija Vista previa para generar una vista previa del análisis.
-
Elija Agregar para agregar la transformación al flujo de datos de Data Wrangler.
Informe de sesgo
Puede utilizar el informe de sesgo de Data Wrangler para detectar posibles sesgos en sus datos. Para generar un informe de sesgo, debe especificar la columna objetivo, o Etiqueta, que desea predecir y una Faceta, o la columna que desea inspeccionar para detectar sesgos.
Etiqueta: la característica sobre la que desea que un modelo haga predicciones. Por ejemplo, si predice la conversión de clientes, puede seleccionar una columna que contenga datos sobre si un cliente ha realizado un pedido o no. También debes especificar si esta característica es una etiqueta o un umbral. Si especifica una etiqueta, debe especificar qué aspecto tendría un resultado positivo en sus datos. En el ejemplo de conversión de clientes, un resultado positivo puede ser un 1 en la columna de pedidos, que representa el resultado positivo de un cliente que ha realizado un pedido en los últimos tres meses. Si especifica un umbral, debe especificar un límite inferior que defina un resultado positivo. Por ejemplo, si las columnas de pedidos de los clientes contienen el número de pedidos realizados el año pasado, podría especificar 1.
Faceta: la columna que desea inspeccionar para detectar sesgos. Por ejemplo, si intenta predecir la conversión de clientes, la faceta podría ser la edad del cliente. Podría elegir esta faceta porque cree que los datos están sesgados hacia un grupo de edad determinado. Debe definir si la faceta se mide como un valor o un umbral. Por ejemplo, si desea inspeccionar una o más edades específicas, seleccione Valor y especifique esas edades. Si desea analizar un grupo de edad, seleccione Umbral y especifique el umbral de edades que desea inspeccionar.
Tras seleccionar la característica y la etiqueta, seleccione los tipos de métricas de sesgo que quiera calcular.
Para obtener más información, consulte Generate reports for bias in pre-training data.
Creación de visualizaciones personalizadas
Puede agregar un análisis al flujo de Data Wrangler para crear una visualización personalizada. Tu conjunto de datos, con todas las transformaciones que has aplicado, está disponible como DataFramePandasdf para almacenar el marco de datos. Para acceder al marco de datos, debe llamar a la variable.
Debe proporcionar la variable de salida, chart, para almacenar un gráfico de salida de Altair
import altair as alt df = df.iloc[:30] df = df.rename(columns={"Age": "value"}) df = df.assign(count=df.groupby('value').value.transform('count')) df = df[["value", "count"]] base = alt.Chart(df) bar = base.mark_bar().encode(x=alt.X('value', bin=True, axis=None), y=alt.Y('count')) rule = base.mark_rule(color='red').encode( x='mean(value):Q', size=alt.value(5)) chart = bar + rule
Para crear una visualización personalizada:
-
Junto al nodo que contiene la transformación que quiere visualizar, elija el signo +.
-
Elija Agregar análisis.
-
En Tipo de análisis, elija Visualización personalizada.
-
En Nombre del análisis, especifique un nombre.
-
Introduzca el código en el cuadro de códigos.
-
Elija Vista previa para obtener una vista previa de la visualización.
-
Elija Guardar para agregar la visualización.

Si no sabe cómo usar el paquete de visualización de Altair en Python, puede usar fragmentos de código personalizados para ayudarle a empezar.
Data Wrangler tiene una colección de fragmentos de visualización con capacidad de búsqueda. Para utilizar un fragmento de visualización, elija Buscar fragmentos de ejemplo y especifique una consulta en la barra de búsqueda.
En el siguiente ejemplo, se utiliza el fragmento de código Gráfico de dispersión discretizado. Traza un histograma para 2 dimensiones.
Los fragmentos incluyen comentarios para ayudarle a entender los cambios que debe realizar en el código. Por lo general, es necesario especificar los nombres de las columnas del conjunto de datos en el código.
import altair as alt # Specify the number of top rows for plotting rows_number = 1000 df = df.head(rows_number) # You can also choose bottom rows or randomly sampled rows # df = df.tail(rows_number) # df = df.sample(rows_number) chart = ( alt.Chart(df) .mark_circle() .encode( # Specify the column names for binning and number of bins for X and Y axis x=alt.X("col1:Q", bin=alt.Bin(maxbins=20)), y=alt.Y("col2:Q", bin=alt.Bin(maxbins=20)), size="count()", ) ) # :Q specifies that label column has quantitative type. # For more details on Altair typing refer to # https://altair-viz.github.io/user_guide/encoding.html#encoding-data-types
