Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Arquitectura Amazon SageMaker Debugger
En este tema se presenta una descripción general de alto nivel del flujo de trabajo de Amazon SageMaker Debugger.
El depurador admite la funcionalidad de creación de perfiles para optimizar el desempeño a fin de identificar problemas de cálculo, como los cuellos de botella del sistema y la infrautilización, además de para ayudar a optimizar la utilización de los recursos de hardware a gran escala.
La funcionalidad de depuración de depurador para la optimización de modelos consiste en analizar los problemas de entrenamiento no convergentes que puedan surgir y, al mismo tiempo, minimizar las funciones de pérdida mediante algoritmos de optimización, como el descenso de gradientes y sus variaciones.
El siguiente diagrama muestra la arquitectura de SageMaker Debugger. Los bloques con líneas de límite en negrita son los elementos que el depurador consigue analizar en tu trabajo de entrenamiento.
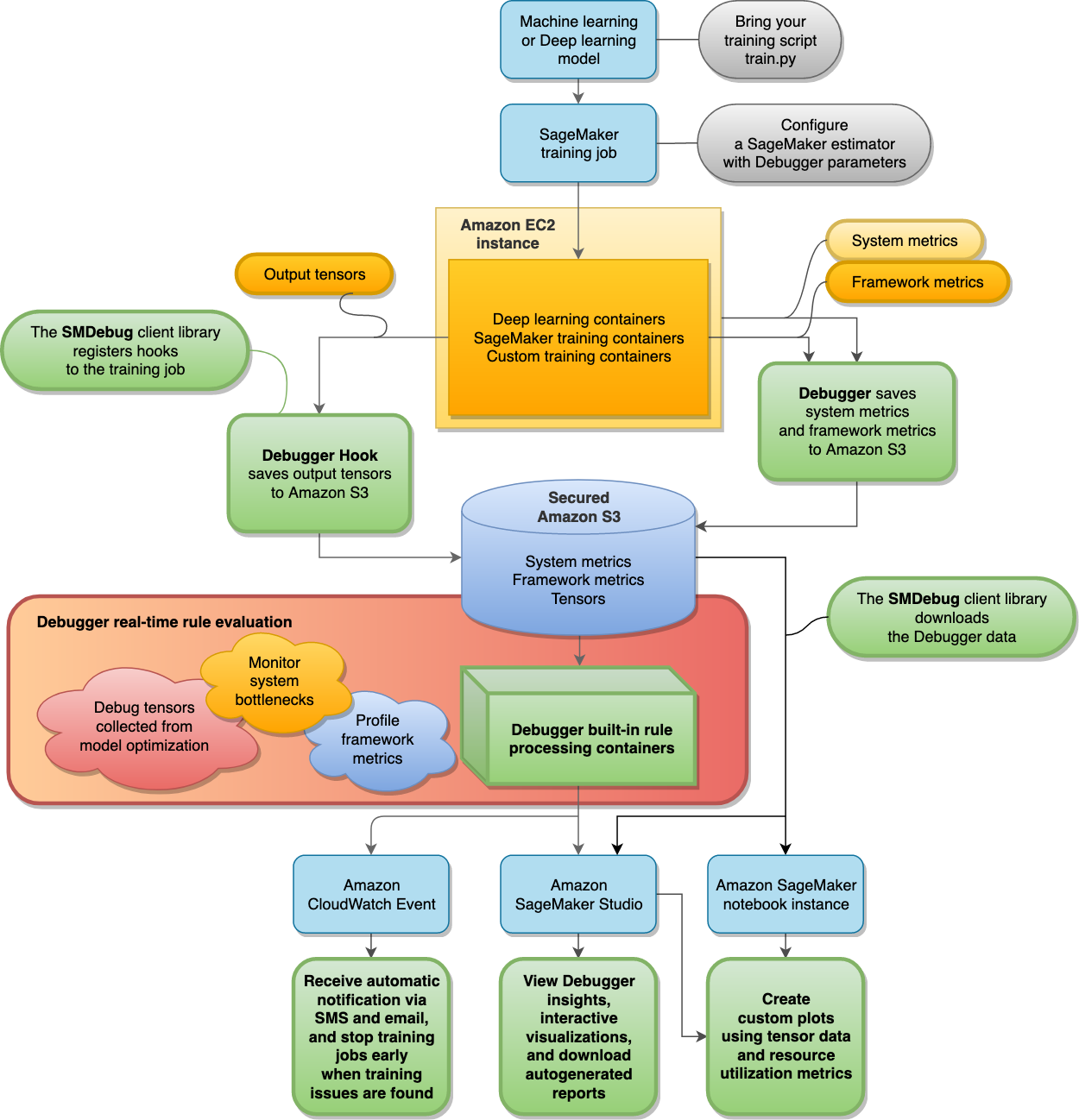
El depurador almacena los siguientes datos de sus trabajos de entrenamiento en su bucket protegido de Amazon S3:
-
Tensores de salida: colecciones de escalares y parámetros del modelo que se actualizan continuamente durante las pasadas hacia adelante y hacia atrás mientras se entrenan los modelos de machine learning. Los tensores de salida incluyen valores escalares (precisión y pérdida) y matrices (pesos, gradientes, capas de entrada y capas de salida).
nota
De forma predeterminada, Debugger supervisa y depura los trabajos de SageMaker entrenamiento sin ningún parámetro específico de Debugger configurado en los estimadores de IA. SageMaker El depurador recopila las métricas del sistema cada 500 milisegundos y los tensores de salida básicos (resultados escalares como la pérdida y la precisión) cada 500 pasos. También ejecuta la regla
ProfilerReportpara analizar las métricas del sistema y agregar el panel de información del depurador de Studio y un informe de creación de perfiles. El depurador guarda los datos de salida en su bucket de Amazon S3 protegido.
Las reglas integradas del depurador se ejecutan en contenedores de procesamiento, que han sido diseñados para evaluar los modelos de machine learning mediante el procesamiento de los datos de entrenamiento recopilados en su bucket S3 (consulte Procesar datos y evaluar modelos). El depurador gestiona completamente las reglas integradas. También puede crear sus propias reglas personalizadas para vigilar cualquier problema que tenga su modelo.
