Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Utilice el algoritmo de SageMaker previsión AI DeepAR
El algoritmo de previsión Amazon SageMaker AI DeepAR es un algoritmo de aprendizaje supervisado para pronosticar series temporales escalares (unidimensionales) mediante redes neuronales recurrentes (RNN). Los métodos de previsión clásicos, como el modelo autorregresivo integrado de media móvil (ARIMA) o el suavizamiento exponencial (ETS), encajan en un solo modelo para cada serie temporal individual. A continuación, utilizan ese modelo para extrapolar la serie temporal en el futuro.
En muchas aplicaciones, sin embargo, disponen de muchas series temporales similares en un conjunto de unidades transversales. Por ejemplo, es posible que tenga agrupaciones de series de tiempo para la demanda de diferentes productos, cargas del servidor y solicitudes de páginas web. Para este tipo de aplicación, puede beneficiarse de un único modelo de capacitación conjuntamente a lo largo de toda la serie temporal. DeepAR toma este enfoque. Cuando el conjunto de datos contiene cientos de series temporales relacionadas, DeepAR supera el estándar ARIMA y los métodos ETS. También puede utilizar el modelo capacitado para generar previsiones para series temporales nuevas que son similares a aquellas para las que ha recibido capacitación.
La entrada de capacitación para el algoritmo DeepAR consta de una o, preferiblemente, más series temporales target generadas por el mismo proceso o por procesos similares. En función de este conjunto de datos de entrada, el algoritmo capacita un modelo que aprende una aproximación de estos procesos y la utiliza para predecir cómo evolucionan las series temporales de destino. Si lo desea, puede asociar cada una de las series temporales de destino a un vector de características categóricas estáticas (independiente del tiempo) proporcionado por el campo cat y a un vector de serie temporal dinámica (dependiente del tiempo) proporcionado por el campo dynamic_feat. SageMaker La IA entrena el modelo DeepAR muestreando aleatoriamente ejemplos de entrenamiento de cada serie temporal objetivo del conjunto de datos de entrenamiento. Cada ejemplo de capacitación se compone de un par de ventanas adyacentes de contexto y predicción con longitudes predefinidas fijas. Para controlar hasta dónde en el pasado puede ver la red, utilice el hiperparámetro context_length. Para controlar hasta dónde en el futuro pueden hacerse predicciones, utilice el hiperparámetro prediction_length. Para obtener más información, consulte ¿Cómo funciona el algoritmo DeepAR?.
Temas
Interfaz de entrada/salida para el algoritmo DeepAR
DeepAR admite dos canales de datos. El canal train obligatorio describe el conjunto de datos de capacitación. El canal test opcional describe un conjunto de datos que el algoritmo utiliza para evaluar la precisión del modelo después de la capacitación. Puede proporcionar capacitación y conjuntos de datos de prueba en el formato de líneas de JSON
Al especificar las rutas para la capacitación y los datos de prueba, puede especificar un solo archivo o un directorio que contiene varios archivos, que se pueden almacenar en subdirectorios. Si especifica un directorio, DeepAR utiliza todos los archivos en el directorio como entradas para el canal correspondiente, excepto los que comienzan con un punto (.) y los denominados _SUCCESS. De este modo, se garantiza que pueda usar directamente las carpetas de salida producidas por trabajos de Spark como canales de entrada para sus trabajos de capacitación de DeepAR.
De forma predeterminada, el modelo DeepAR determina el formato de entrada a partir de la extensión del archivo (.json, .json.gz o .parquet) en la ruta de entrada especificada. Si la ruta no termina en una de estas extensiones, debe especificar de forma explícita el formato en el SDK para Python. Utilice el parámetro content_type de la clase s3_input
Los registros en sus archivos de entrada deben contener los siguientes campos:
-
start: una cadena con el formatoYYYY-MM-DD HH:MM:SS. La marca temporal de inicio no puede contener información sobre la zona horaria. -
target: una matriz de valores de punto flotante o enteros que representan la serie temporal. Puede codificar los valores que faltan como literalesnullo como cadenas"NaN"en JSON o como los valores de coma flotantenanen Parquet. -
dynamic_feat(opcional): una matriz de matrices de valores de punto flotante o enteros que representa el vector de series temporales de características personalizadas (características dinámicas). Si configura este campo, todos los registros deben tener el mismo número de matrices internas (el mismo número de serie temporal de características). Además, cada matriz interna debe tener la misma longitud que el valortargetasociado más laprediction_length. Las características no se admiten en los valores que faltan. Por ejemplo, si la serie temporal de destino representa la demanda de diferentes productos, un campodynamic_featasociado podría ser una serie temporal booleana que indique si se ha aplicado una promoción (1) al producto en concreto o no (0):{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(opcional): una matriz de características categóricas que se puede usar para codificar los grupos a los que pertenece el registro. Las características categóricas deben codificarse como una secuencia de números enteros positivos basada en 0. Por ejemplo, el dominio categórico {R, G B} puede ser codificarse como {0, 1, 2}. Todos los valores de cada dominio categórico debe estar representado en el conjunto de datos de capacitación. Esto se debe a que el algoritmo DeepAR puede hacer predicciones solo para las categorías que se han observado durante la capacitación. Además, cada característica categórica está integrada en un espacio de baja dimensión cuya dimensionalidad se controla mediante el hiperparámetroembedding_dimension. Para obtener más información, consulte Hiperparámetros de DeepAR.
Si utiliza un archivo JSON, debe tener el formato de líneas de JSON
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
En este ejemplo, cada serie temporal tiene dos características categóricas asociadas y una característica de serie temporal.
Para Parquet, utilice los mismos tres campos como columnas. Además, "start" puede ser el tipo datetime. Puede comprimir archivos Parquet con gzip (gzip) o la biblioteca de compresión Snappy (snappy).
Si el algoritmo se ha capacitado sin los campos cat y dynamic_feat, aprenderá un modelo "global", es decir, un modelo que es independiente de la identidad específica de la serie temporal de destino en el tiempo de inferencia y que solo está condicionado por su forma.
Si el modelo está condicionado por los datos de características cat y dynamic_feat que proporciona cada serie temporal, es probable que la predicción esté influenciada por el carácter de la serie temporal con las características cat correspondientes. Por ejemplo, si la serie temporal target representa la demanda de prendas de ropa, puede asociar un vector cat bidimensional que codifique el tipo de prenda (p. ej. 0 = zapatos, 1 = vestido) en el primer componente y el color de la prenda (p. ej. 0 = rojo, 1 = azul) en el segundo componente. Una entrada de muestra tendría el siguiente aspecto:
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
En tiempo de inferencia, puede solicitar predicciones para destinos con valores cat que sean combinaciones de los valores cat observados en los datos de capacitación, por ejemplo:
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
Las siguientes directrices son aplicables a los datos de capacitación:
-
La hora de inicio y longitud de la serie temporal pueden diferir. Por ejemplo, en marketing, los productos a menudo se incorporan a los catálogos de venta en fechas diferentes, por lo que sus fechas de inicio difieren de forma natural. Sin embargo, todas las series deben tener la misma frecuencia, el mismo número de características categóricas y el mismo número de características dinámicas.
-
Mezcle el archivo de capacitación con respecto a la posición de la serie temporal en el archivo. Es decir, la serie temporal debe producirse en orden aleatorio en el archivo.
-
Asegúrese de que establece el campo
startcorrectamente. El algoritmo utiliza la marca temporalstartpara obtener las características internas. -
Si utiliza características categóricas (
cat), todas las series temporales deben tener el mismo número de características categóricas. Si el conjunto de datos contiene el campocat, el algoritmo lo utiliza y extrae la cardinalidad de los grupos del conjunto de datos. Por defecto,cardinalityes"auto". Si el conjunto de datos contiene el campocat, pero no desea utilizarlo, puede desactivarlo definiendocardinalitycomo"". Si se ha capacitado un modelo utilizando una característicacat, debe incluirlo para realizar inferencias. -
Si el conjunto de datos contiene el campo
dynamic_feat, el algoritmo lo utiliza de forma automática. Todas las series temporales tienen que tener el mismo número de series temporales de características. Los puntos temporales de cada una de las series temporales de las características corresponden one-to-one a los puntos temporales del objetivo. Además, la entrada en el campodynamic_featdebe tener la misma longitud que el campotarget. Si el conjunto de datos contiene el campodynamic_feat, pero no desea utilizarlo, puede desactivarlo definiendonum_dynamic_featcomo"". Si se ha capacitado el modelo con el campodynamic_feat, debe proporcionar este campo para realizar inferencias. Además, cada una de las características debe tener la longitud del destino proporcionado además deprediction_length. En otras palabras, debe proporcionar el valor de la característica en el futuro.
Si especifica datos de canal de prueba opcionales, el algoritmo de DeepAR evalúa el modelo de capacitación con diferentes métricas de precisión. El algoritmo calcula la desviación cuadrática media (RMSE) en los datos de prueba de la siguiente forma:
-y(i,t))^2))](images/deepar-1.png)
yi,t es el valor verdadero de la serie temporal i en el momento t. ŷi,t es la predicción media. La suma supera a todas las series temporales n en el conjunto de pruebas y es superior a los últimos puntos temporales para cada serie temporal, donde T se corresponde con el horizonte de predicción. Especifique la longitud del horizonte de previsión configurando el prediction_length hiperparámetro. Para obtener más información, consulte Hiperparámetros de DeepAR.
Además, el algoritmo evalúa la precisión de la distribución prevista mediante la pérdida de cuantil ponderada. Para obtener un cuantil en el rango [0, 1], la pérdida de cuantil ponderada se define de la siguiente forma:
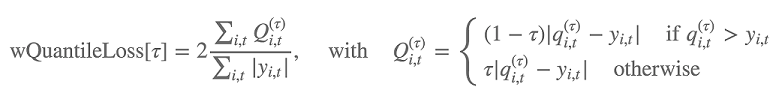
qi,t(τ) es el cuantil τ de la distribución que predice el modelo. Para especificar para qué cuantiles calcular la pérdida, establezca el hiperparámetro test_quantiles. Además de estos, el promedio de las pérdidas de cuantiles prescritos se informa como parte de los registros de capacitación. Para obtener más información, consulte Hiperparámetros de DeepAR.
Para la inferencia, DeepAR acepta el formato JSON y los siguientes campos:
-
"instances", que incluye una o más series temporales en formato de líneas JSON -
Un nombre de
"configuration", que incluye parámetros para generar la previsión
Para obtener más información, consulte Formatos de inferencia de DeepAR.
Prácticas recomendadas para utilizar el algoritmo DeepAR
Al preparar sus datos de serie temporal, siga estas prácticas recomendadas para conseguir los mejores resultados:
-
Excepto en lo tocante a la división de su conjunto de datos para la capacitación y las pruebas, proporcione siempre toda la serie temporal para la capacitación, las pruebas y cuándo llamar al modelo para realizar inferencias. Independientemente de cómo establezca
context_length, no divida la serie temporal ni proporcione solo una parte. El modelo utiliza puntos de datos que van más allá del valor establecido encontext_lengthpara la característica de valores con retraso. -
Al ajustar un modelo DeepAR, puede dividir el conjunto de datos para crear un conjunto de datos de capacitación y un conjunto de datos de prueba. En una evaluación típica, se prueba el modelo en la misma serie temporal utilizada para la capacitación, pero en los puntos temporales
prediction_lengthfuturos que siguen inmediatamente después del último punto temporal visible durante la capacitación. Puede crear conjuntos de datos de capacitación y de prueba que satisfagan estos criterios mediante todo el conjunto de datos (la longitud total de todas las series temporales que están disponibles) como conjunto de prueba y eliminar los últimos puntosprediction_lengthde cada serie temporal para la capacitación. Durante la capacitación, el modelo no ve los valores de destino para puntos de tiempo en los que se evalúa durante las pruebas. Durante las pruebas, el algoritmo retiene los últimos puntosprediction_lengthde cada serie temporal del conjunto de pruebas y se genera una predicción. A continuación, compara la previsión con los valores retenidos. Puede crear evaluaciones más complejas repitiendo series temporales varias veces en el conjunto de pruebas pero cortándolas en puntos de enlace diferentes. Con este enfoque, se realiza un promedio de métricas de precisión en diferentes previsiones de diferentes puntos temporales. Para obtener más información, consulte Ajustar un modelo DeepAR. -
Evite utilizar valores muy grandes (> 400) para
prediction_lengthya que hace que el modelo sea lento y menos preciso. Si desea realizar una previsión que vaya más allá en el futuro, puede agregar los datos con una frecuencia inferior. Por ejemplo, utilice5minen lugar de1min. -
Dado que se utilizan réplicas, un modelo puede retroceder más allá en la serie temporal del valor especificado para
context_length. Por lo tanto, no es necesario establecer este parámetro en un valor grande. Le recomendamos que comience con el valor que utilizó paraprediction_length. -
Le recomendamos realizar la capacitación de un modelo DeepAR en tantas series temporales como sea posible. Aunque un modelo DeepAR capacitado en una sola serie temporal podría funcionar bien, los algoritmos de previsión estándar, como, por ejemplo, ARIMA o ETS, podrían proporcionar resultados más precisos. El algoritmo DeepAR comienza a superar los métodos estándar cuando el conjunto de datos contiene cientos de series temporales relacionadas. En la actualidad, DeepAR requiere que el número total de observaciones disponibles en todas las series temporales de capacitación sea al menos 300.
EC2 Recomendaciones de instancias para el algoritmo DeepAR
Puede realizar la capacitación de DeepAR en instancias de GPU y CPU en la configuración de una máquina o de varias máquinas. Le recomendamos comenzar por una única instancia de CPU (por ejemplo, ml.c4.2xlarge o ml.c4.4xlarge) y cambiar a instancias de GPU y varias máquinas solo si es necesario. El uso GPUs de varias máquinas mejora el rendimiento solo en modelos más grandes (con muchas celdas por capa y muchas capas) y en minilotes grandes (por ejemplo, más de 512).
Para la inferencia, DeepAR solo admite instancias de CPU.
Especificar valores grandes para context_length, prediction_length, num_cells, num_layers o mini_batch_size puede crear modelos que son demasiado grandes para instancias pequeñas. En este caso, utilice un tipo de instancia mayor o reduzca los valores de estos parámetros. Este problema también se produce con frecuencia al ejecutar trabajos de ajuste de hiperparámetros. En ese caso, utilice un tipo de instancia lo suficientemente grande para el trabajo de ajuste de modelos y considere la posibilidad de limitar los valores superiores de los parámetros críticos para evitar errores de trabajo.
Cuadernos de ejemplos de DeepAR
Para ver un ejemplo de cuaderno que muestra cómo preparar un conjunto de datos de series temporales para entrenar el algoritmo DeepAR de SageMaker IA y cómo implementar el modelo entrenado para realizar inferencias, consulte la demostración de DeepAR sobre un conjunto de datos de electricidad, que ilustra las funciones avanzadas de DeepAR en un conjunto
Para obtener más información sobre el algoritmo Amazon SageMaker AI DeepAR, consulta las siguientes entradas de blog:
