Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cree un modelo en Amazon SageMaker AI con ModelBuilder
La preparación del modelo para su implementación en un punto final de SageMaker IA requiere varios pasos, como elegir una imagen del modelo, configurar la configuración del punto final, codificar las funciones de serialización y deserialización para transferir datos hacia y desde el servidor y el cliente, identificar las dependencias del modelo y cargarlos en Amazon S3. ModelBuilderpuede reducir la complejidad de la configuración y el despliegue iniciales para ayudarle a crear un modelo desplegable en un solo paso.
ModelBuilder lleva a cabo las tareas siguientes por usted:
Convierte los modelos de aprendizaje automático entrenados con varios marcos, como XGBoost o PyTorch en modelos desplegables, en un solo paso.
Realiza una selección automática de contenedores en función del marco del modelo, por lo que no es necesario especificar el contenedor manualmente. Puede seguir usando su propio contenedor pasando su propio URI a
ModelBuilder.Se encarga de la serialización de los datos en el cliente antes de enviarlos al servidor para la inferencia y la deserialización de los resultados devueltos por el servidor. Los datos se formatean correctamente sin procesamiento manual.
Habilita la captura automática de las dependencias y empaqueta el modelo según las expectativas del servidor de modelos. La captura automática de
ModelBuilderde las dependencias es el enfoque del mejor esfuerzo para cargar las dependencias de manera dinámica. (Le recomendamos que pruebe la captura automática de manera local y actualice las dependencias para satisfacer sus necesidades).Para los casos de uso de modelos de lenguaje (LLM) de gran tamaño, opcionalmente realiza un ajuste local de los parámetros de las propiedades de servidor que se pueden implementar para mejorar el rendimiento cuando se alojan en un terminal de SageMaker IA.
Es compatible con la mayoría de los modelos de servidores y contenedores más populares TorchServe, como Triton DJLServing y TGI Container.
Cree su modelo con ModelBuilder
ModelBuilderes una clase de Python que toma un modelo de marco, como XGBoost o PyTorch, o una especificación de inferencia especificada por el usuario y lo convierte en un modelo desplegable. ModelBuilderproporciona una función de creación que genera los artefactos para su despliegue. El artefacto de modelo generado es específico del servidor de modelos, que también puede especificar como una de las entradas. Para obtener más información sobre la ModelBuilder clase, consulte ModelBuilder
En el siguiente diagrama se muestra el flujo de trabajo general de creación de modelos al usar ModelBuilder. ModelBuilder acepta un modelo o una especificación de inferencia junto con su esquema para crear un modelo implementable que pueda probarse localmente antes de la implementación.
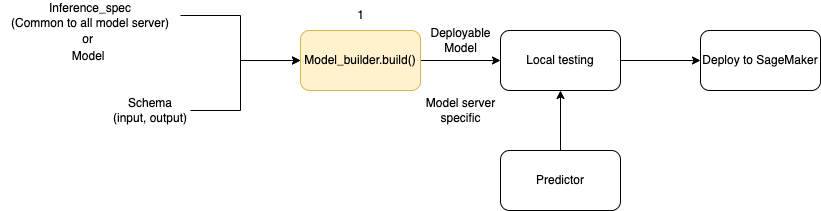
ModelBuilder puede gestionar cualquier personalización que desee aplicar. Sin embargo, para implementar un modelo de marco, el generador de modelos espera como mínimo un modelo, una entrada y salida de ejemplo, y el rol. En el siguiente ejemplo de código, se llama a ModelBuilder con un modelo de marco y una instancia de SchemaBuilder con argumentos mínimos (para inferir las funciones correspondientes para serializar y deserializar la entrada y la salida del punto de conexión). No se especifica ningún contenedor ni se transfiere ningún paquete de dependencias: la SageMaker IA deduce automáticamente estos recursos cuando se crea el modelo.
from sagemaker.serve.builder.model_builder import ModelBuilder from sagemaker.serve.builder.schema_builder import SchemaBuilder model_builder = ModelBuilder( model=model, schema_builder=SchemaBuilder(input, output), role_arn="execution-role", )
En el siguiente ejemplo de código, se invoca ModelBuilder con una especificación de inferencia (como una instancia InferenceSpec) en lugar de un modelo, con una personalización adicional. En este caso, la llamada al generador de modelos incluye una ruta para almacenar los artefactos del modelo y también activa la captura automática de todas las dependencias disponibles. Para obtener más información sobre InferenceSpec, consulte Personalización de la carga del modelo y la gestión de las solicitudes.
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": True} )
Definición de los métodos de serialización y deserialización
Al invocar un punto final de SageMaker IA, los datos se envían a través de cargas HTTP con diferentes tipos de MIME. Por ejemplo, una imagen enviada al punto de conexión para su inferencia debe convertirse en bytes en el cliente y enviarse a través de una carga útil HTTP al punto de conexión. Cuando el punto de conexión recibe la carga útil, debe deserializar la cadena de bytes para devolverla al tipo de datos que el modelo espera (también conocida como deserialización del servidor). Una vez que el modelo finalice la predicción, los resultados también deben serializarse en bytes que se pueden devolver al usuario o al cliente a través de la carga útil HTTP. Una vez que el cliente recibe los datos de bytes de respuesta, debe realizar una deserialización del cliente para volver a convertir los datos de bytes al formato de datos esperado, como JSON. Como mínimo, tiene que convertir los datos para las siguientes tareas:
Serialización de la solicitud de inferencias (gestionada por usted)
Deserialización de la solicitud de inferencias (gestionada por el servidor o el algoritmo)
Invocación del modelo contra la carga útil y devolución de la carga útil de respuesta
Serialización de la respuesta de inferencias (gestionada por el servidor o el algoritmo)
Deserialización de la respuesta de inferencias (gestionada por el cliente)
En el siguiente diagrama se muestra los procesos de serialización y deserialización que se producen al invocar el punto de conexión.
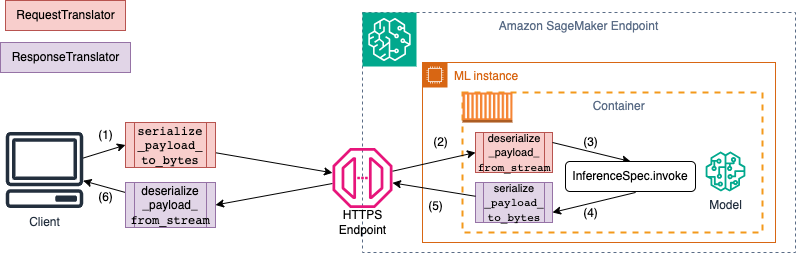
Al proporcionar entrada y salida de ejemplo a SchemaBuilder, el generador de esquemas genera las funciones de clasificación correspondientes para serializar y deserializar la entrada y la salida. Puede personalizar aún más sus funciones de serialización con CustomPayloadTranslator. Pero, en la mayoría de los casos, funcionaría un serializador sencillo como el siguiente:
input = "How is the demo going?" output = "Comment la démo va-t-elle?" schema = SchemaBuilder(input, output)
Para obtener más información al respecto, consulteSchemaBuilder. SchemaBuilder
En el siguiente fragmento de código se describe un ejemplo en el que se desea personalizar las funciones de serialización y deserialización en el cliente y el servidor. Puede definir sus propios traductores de solicitudes y respuestas con CustomPayloadTranslator y pasar estos traductores a SchemaBuilder.
Al incluir las entradas y salidas con los traductores, el generador de modelos puede extraer el formato de datos que el modelo espera. Por ejemplo, supongamos que la entrada de ejemplo es una imagen sin procesar y sus traductores personalizados recortan la imagen y la envían al servidor como tensor. ModelBuilder necesita tanto la entrada sin procesar como cualquier código personalizado de preprocesamiento o posprocesamiento para obtener un método que convierta los datos tanto en el cliente como en el servidor.
from sagemaker.serve import CustomPayloadTranslator # request translator class MyRequestTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on client side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the input payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on server side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object # response translator class MyResponseTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on server side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the response payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on client side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object
Al crear el objeto SchemaBuilder, pasa la entrada y salida de ejemplo junto con los traductores personalizados previamente definidos, como se muestra en el siguiente ejemplo:
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
A continuación, pasa al objeto SchemaBuilder la entrada y salida de ejemplo, junto con los traductores personalizados definidos anteriormente.
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
En las siguientes secciones se explica en detalle cómo crear el modelo con ModelBuilder y usar sus clases auxiliares para personalizar la experiencia según su caso de uso.
Temas
Personalización de la carga del modelo y la gestión de las solicitudes
Al proporcionar su propio código de inferencia a través de InferenceSpec, se ofrece una capa adicional de personalización. Con InferenceSpec, puede personalizar la manera en que se carga el modelo y la forma en que gestiona las solicitudes de inferencia entrantes, al omitir sus mecanismos predeterminados de gestión de inferencias y carga. Esta flexibilidad es especialmente beneficiosa al trabajar con modelos no estándar o canalizaciones de inferencia personalizadas. Puede personalizar el método invoke para controlar la manera en que el modelo preprocesa y posprocesa las solicitudes entrantes. El método invoke garantiza que el modelo gestione las solicitudes de inferencia correctamente. El siguiente ejemplo se utiliza InferenceSpec para generar un modelo con la HuggingFace canalización. Para obtener más información al respectoInferenceSpec, consulte la InferenceSpec
from sagemaker.serve.spec.inference_spec import InferenceSpec from transformers import pipeline class MyInferenceSpec(InferenceSpec): def load(self, model_dir: str): return pipeline("translation_en_to_fr", model="t5-small") def invoke(self, input, model): return model(input) inf_spec = MyInferenceSpec() model_builder = ModelBuilder( inference_spec=your-inference-spec, schema_builder=SchemaBuilder(X_test, y_pred) )
En el siguiente ejemplo, se muestra una variante más personalizada de un ejemplo anterior. Un modelo se define con una especificación de inferencia que tiene dependencias. En este caso, el código de la especificación de inferencia depende del paquete lang-segment. El argumento para dependencies contiene una instrucción que indica al generador que instale lang-segment mediante Git. Dado que el usuario indica al generador de modelos que instale una dependencia de manera personalizada, la clave auto es False para desactivar la captura automática de las dependencias.
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": False, "custom": ["-e git+https://github.com/luca-medeiros/lang-segment-anything.git#egg=lang-sam"],} )
Creación del modelo e implementación
Llame a la función build para crear su modelo implementable. En este paso, se crean códigos de inferencia (como inference.py) en el directorio de trabajo con el código necesario para crear el esquema, ejecutar la serialización y deserialización de las entradas y salidas, y ejecutar otras lógicas personalizadas especificadas por el usuario.
Como control de integridad, SageMaker AI empaqueta y selecciona los archivos necesarios para la implementación como parte de la función de ModelBuilder compilación. Durante este proceso, la SageMaker IA también crea una firma HMAC para el archivo pickle y añade la clave secreta a la CreateModelAPI como variable de entorno durante deploy (o). create Al iniciar el punto de conexión, se utiliza la variable de entorno para validar la integridad del archivo pickle.
# Build the model according to the model server specification and save it as files in the working directory model = model_builder.build()
Implemente su modelo con el método deploy existente del modelo. En este paso, la SageMaker IA configura un punto final para alojar el modelo a medida que comienza a hacer predicciones sobre las solicitudes entrantes. Aunque ModelBuilder infiere los recursos de punto de conexión necesarios para implementar el modelo, puede anular esas estimaciones con los valores de sus propios parámetros. En el siguiente ejemplo, se indica a SageMaker AI que implemente el modelo en una sola ml.c6i.xlarge instancia. Un modelo construido a partir de ModelBuilder habilita el registro en directo durante la implementación como característica adicional.
predictor = model.deploy( initial_instance_count=1, instance_type="ml.c6i.xlarge" )
Si desea tener un control más preciso sobre los recursos de punto de conexión asignados a su modelo, puede utilizar un objeto ResourceRequirements. Con el ResourceRequirements objeto, puede solicitar un número mínimo de CPUs aceleradores y copias de los modelos que desee implementar. También puede solicitar un límite de memoria mínimo y máximo (en MB). Para utilizar esta característica, debe especificar el tipo de punto de conexión como EndpointType.INFERENCE_COMPONENT_BASED. En el siguiente ejemplo, se solicitan cuatro aceleradores, un tamaño de memoria mínimo de 1024 MB y una copia del modelo que se implementará en un punto de conexión del tipo EndpointType.INFERENCE_COMPONENT_BASED.
resource_requirements = ResourceRequirements( requests={ "num_accelerators": 4, "memory": 1024, "copies": 1, }, limits={}, ) predictor = model.deploy( mode=Mode.SAGEMAKER_ENDPOINT, endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED, resources=resource_requirements, role="role" )
Utilice su propio contenedor (BYOC)
Si quieres traer tu propio contenedor (derivado de un contenedor de SageMaker IA), también puedes especificar el URI de la imagen, tal y como se muestra en el siguiente ejemplo. También debe identificar el servidor de modelos que corresponde a la imagen para que ModelBuilder genere artefactos específicos del servidor de modelos.
model_builder = ModelBuilder( model=model, model_server=ModelServer.TORCHSERVE, schema_builder=SchemaBuilder(X_test, y_pred), image_uri="123123123123.dkr.ecr.ap-southeast-2.amazonaws.com/byoc-image:xgb-1.7-1") )
ModelBuilder Utilizándolo en modo local
Puede implementar su modelo localmente mediante el argumento mode para pasar de las pruebas locales a la implementación en un punto de conexión. Debe almacenar los artefactos del modelo en el directorio de trabajo, tal y como se muestra en el siguiente fragmento de código:
model = XGBClassifier() model.fit(X_train, y_train) model.save_model(model_dir + "/my_model.xgb")
Pase el objeto de modelo, una instancia SchemaBuilder y establezca el modo en Mode.LOCAL_CONTAINER. Al llamar a la función build, ModelBuilder identifica automáticamente el contenedor del marco admitido y busca las dependencias. El siguiente ejemplo muestra la creación de un modelo con un XGBoost modelo en modo local.
model_builder_local = ModelBuilder( model=model, schema_builder=SchemaBuilder(X_test, y_pred), role_arn=execution-role, mode=Mode.LOCAL_CONTAINER ) xgb_local_builder = model_builder_local.build()
Llame a la función deploy para implementarla localmente, tal y como se muestra en el siguiente fragmento de código. Si especifica parámetros para el tipo o recuento de instancias, se ignoran estos argumentos.
predictor_local = xgb_local_builder.deploy()
Solución de problemas en modo local
En función de su configuración local individual, es posible que tenga dificultades para ejecutar ModelBuilder sin problemas en su entorno. Consulte la lista siguiente para ver algunos problemas a los que se puede enfrentar y cómo resolverlos.
Ya está en uso: es posible que se produzca un error
Address already in use. En este caso, es posible que un contenedor de Docker se esté ejecutando en ese puerto o que otro proceso lo esté utilizando. Puede seguir el enfoque descrito en la documentación de Linuxpara identificar el proceso y redirigir sin problemas el proceso local del puerto 8080 a otro puerto o limpiar la instancia de Docker. Problema de permiso de IAM: es posible que se produzca un problema de permiso al intentar extraer una imagen de Amazon ECR o acceder a Amazon S3. En este caso, diríjase al rol de ejecución del bloc de notas o de la instancia de Studio Classic para comprobar la política para
SageMakerFullAccesso los permisos de API respectivos.Problema de capacidad de volumen de EBS: si implementa un modelo de lenguaje grande (LLM), es posible que se quede sin espacio al ejecutar Docker en modo local o que tenga limitaciones de espacio en la caché de Docker. En este caso, puede intentar mover el volumen de Docker a un sistema de archivos que tenga espacio suficiente. Para mover el volumen de Docker, complete los siguientes pasos:
Abra un terminal y ejecute
dfpara mostrar el uso del disco, como se muestra en la siguiente salida:(python3) sh-4.2$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 195928700 0 195928700 0% /dev tmpfs 195939296 0 195939296 0% /dev/shm tmpfs 195939296 1048 195938248 1% /run tmpfs 195939296 0 195939296 0% /sys/fs/cgroup /dev/nvme0n1p1 141545452 135242112 6303340 96% / tmpfs 39187860 0 39187860 0% /run/user/0 /dev/nvme2n1 264055236 76594068 176644712 31% /home/ec2-user/SageMaker tmpfs 39187860 0 39187860 0% /run/user/1002 tmpfs 39187860 0 39187860 0% /run/user/1001 tmpfs 39187860 0 39187860 0% /run/user/1000Mueva el directorio Docker predeterminado de
/dev/nvme0n1p1a para/dev/nvme2n1poder utilizar al máximo el volumen SageMaker AI de 256 GB. Para obtener más información, consulte la documentación sobre cómo mover el directorio de Docker. Detenga Docker con el siguiente comando:
sudo service docker stopAgregue
daemon.jsona/etc/dockero anexe el siguiente blob de JSON al existente.{ "data-root": "/home/ec2-user/SageMaker/{created_docker_folder}" }Mueva el directorio de Docker de
/var/lib/dockera/home/ec2-user/SageMaker AIcon el siguiente comando:sudo rsync -aP /var/lib/docker/ /home/ec2-user/SageMaker/{created_docker_folder}Inicie el agente con el comando siguiente.
sudo service docker startLimpie la papelera con el siguiente comando:
cd /home/ec2-user/SageMaker/.Trash-1000/files/* sudo rm -r *Si utilizas una instancia de SageMaker notebook, puedes seguir los pasos del archivo de preparación de Docker
para preparar Docker para el modo local.
ModelBuilder ejemplos
Para ver más ejemplos de uso ModelBuilder para crear modelos, consulta los ModelBuilderejemplos de libretas
