Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Resultados de recomendaciones
El resultado de cada trabajo del Recomendador de inferencias incluye InstanceTypeInitialInstanceCount, y EnvironmentParameters, que son parámetros variables de entorno ajustados para su contenedor a fin de mejorar su latencia y rendimiento. Los resultados también incluyen métricas de rendimiento y costes, como MaxInvocations, ModelLatency, CostPerHour, CostPerInference, CpuUtilization y MemoryUtilization.
En la siguiente tabla, ofrecemos una descripción de estas métricas. Estas métricas pueden ayudarle a reducir la búsqueda de la mejor configuración de punto de conexión que se adapte a su caso de uso. Por ejemplo, si su motivación es la relación precio-rendimiento general con un énfasis en el rendimiento, entonces debería centrarse en CostPerInference.
| Métrica | Descripción | Caso de uso |
|---|---|---|
|
|
El intervalo de tiempo que tarda un modelo en responder visto desde la SageMaker IA. Este intervalo incluye el tiempo de comunicación local empleado en el envío de la solicitud y la recuperación de la respuesta del contenedor de un modelo, así como el tiempo que se tarda en completar la inferencia en el contenedor. Unidades: milisegundos |
Cargas de trabajo sensibles a la latencia, como la publicación de anuncios y el diagnóstico médico |
|
|
El número máximo de solicitudes Unidades: ninguna |
Cargas de trabajo centradas en el rendimiento, como el procesamiento de vídeo o la inferencia por lotes |
|
|
El coste estimado por hora del punto de conexión en tiempo real. Unidades: dólares estadounidenses |
Cargas de trabajo sensibles a los costes sin plazos de latencia |
|
|
El coste estimado por llamada de inferencia para el punto de conexión en tiempo real. Unidades: dólares estadounidenses |
Maximizar el rendimiento general de los precios centrándose en el rendimiento |
|
|
El uso esperado de la CPU con un máximo de invocaciones por minuto para la instancia de punto de conexión. Unidad: porcentaje |
Entender el estado de la instancia durante la evaluación comparativa al tener visibilidad del uso de la CPU principal de la instancia |
|
|
El uso de memoria esperado con un máximo de invocaciones por minuto para la instancia de punto de conexión. Unidad: porcentaje |
Entender el estado de la instancia durante la evaluación comparativa al tener visibilidad del uso de la memoria principal de la instancia |
En algunos casos, es posible que desees explorar otras métricas de SageMaker IA Endpoint Invocation, como CPUUtilization El resultado de cada trabajo del Recomendador de inferencias incluye los nombres de los puntos de conexión generados durante la prueba de carga. Puedes utilizarlos CloudWatch para revisar los registros de estos puntos finales incluso después de haberlos eliminado.
La siguiente imagen es un ejemplo de CloudWatch métricas y gráficos que puede revisar para un único punto final a partir del resultado de su recomendación. El resultado de esta recomendación proviene de un trabajo predeterminado. La forma de interpretar los valores escalares a partir de los resultados de la recomendación es basarlos en el momento en que el gráfico de invocaciones comienza a estabilizarse por primera vez. Por ejemplo, el valor ModelLatency registrado se encuentra al principio de la estabilización alrededor de 03:00:31.
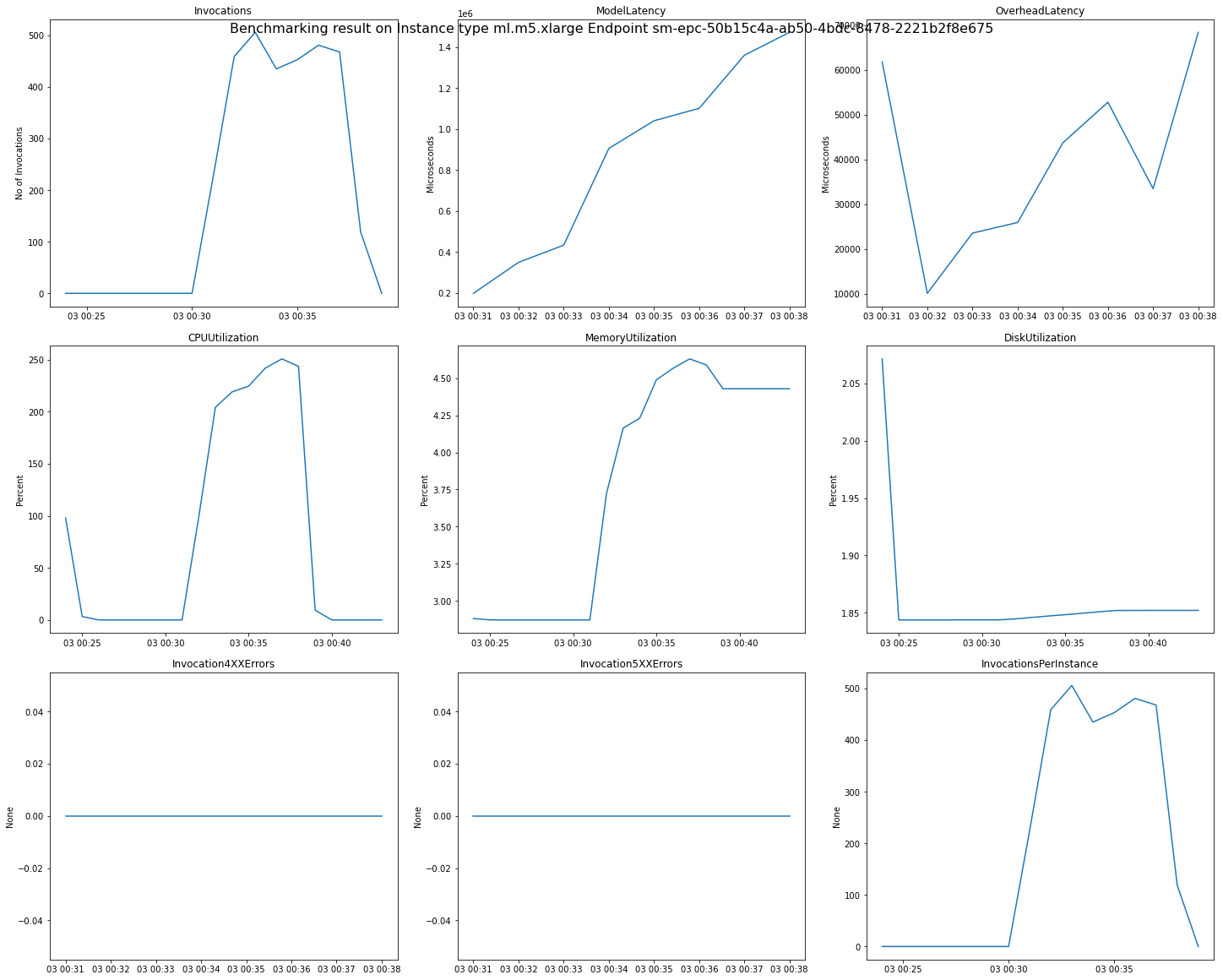
Para obtener una descripción completa de las CloudWatch métricas utilizadas en los gráficos anteriores, consulte las métricas de SageMaker AI Endpoint Invocation.
También puede ver métricas de rendimiento, como ClientInvocations y NumberOfUsers publicadas por el Recomendador de inferencias en el espacio de nombres /aws/sagemaker/InferenceRecommendationsJobs. Para obtener una lista completa de las métricas y descripciones publicadas por el Recomendador de inferencias, consulte SageMaker Métricas de trabajos de Inference Recommender.
Consulte el cuaderno Amazon SageMaker Inference Recommender: CloudWatch Metrics
