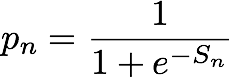Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cómo funciona Información IP
Amazon SageMaker AI IP Insights es un algoritmo no supervisado que consume los datos observados en forma de pares (entidad, IPv4 dirección) que asocian entidades con direcciones IP. Información IP determina qué probabilidades hay de que una entidad utilice una determinada dirección IP mediante el aprendizaje de las representaciones vectoriales latentes para ambas partes y direcciones IP. La distancia entre estas dos representaciones puede servir como factor para determinar la probabilidad de esta asociación.
El algoritmo Información IP utiliza una red neuronal latente para conocer las representaciones vectoriales latentes para las entidades y las direcciones IP. Las entidades son en primer lugar formuladas con hash a un espacio de hash amplio pero fijo y, a continuación, son codificadas por una capa de integración sencilla. Las cadenas de caracteres, como los nombres de usuario o las cuentas, se IDs pueden introducir directamente en IP Insights tal como aparecen en los archivos de registro. No es necesario volver a procesar los datos para la entidad identificadores. Puede proporcionar entidades como un valor de cadena arbitrario durante tareas de capacitación e inferencia. El tamaño del hash se debe configurar con un valor que sea lo suficientemente alto como para garantizar que el número de colisiones, que se producen cuando entidades diferentes se asignan al mismo vector latente, siga siendo insignificante. Para obtener más información acerca de cómo seleccionar los tamaños de hash adecuados, consulte Función de hash para aprendizaje multitarea a gran escala
Durante la capacitación, Información IP genera automáticamente muestras negativas emparejando aleatoriamente entidades y direcciones IP. Estas muestras negativas representan datos que es menos probable que se producen en realidad. El modelo se capacita para distinguir entre muestras positivas que son observadas en los datos de capacitación y estas muestras negativas generadas. En concreto, el modelo es capacitado para minimizar la entropía cruzada, que también se conoce como pérdida de registro, definido como se indica a continuación:
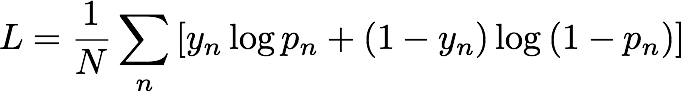
yn es la etiqueta que indica si la muestra procede de la distribución real que controla los datos observados (yn=1) o de la distribución que genera muestras negativas (yn=0). pn es la probabilidad de que la muestra sea de la distribución real, tal como lo predice el modelo.
La generación de muestras negativas es un importante proceso que se utiliza para conseguir un modelo preciso de los datos observados. Si las muestras negativas son muy poco probables, por ejemplo, si todas las direcciones IP en muestras negativas son 10.0.0.0, entonces el modelo aprende trivialmente a distinguir muestras negativas y no consigue a caracterizar con exactitud el conjunto de datos realmente observado. Para mantener muestras negativas más realistas, Información IP genera muestras negativas de forma aleatoria generando las direcciones IP y de forma aleatoria eligiendo direcciones IP de datos de capacitación. Puede configurar el tipo de muestreo negativo y la velocidad a la que se generan muestras negativas con los hiperparámetros random_negative_sampling_rate y shuffled_negative_sampling_rate.
Dada una entidad/par de dirección IP número n, el modelo de IP Insights genera una puntuación, Sn, que indica el grado de compatibilidad de la entidad con la dirección IP. Esta puntuación se corresponde con la probabilidad de registro para una determinada (entidad, dirección IP) del par procedente de una distribución real en comparación con las procedentes de una distribución negativa. Se define de la siguiente manera:
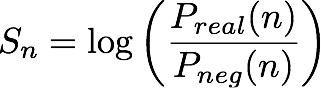
La puntuación es básicamente una medida de la similitud entre las representaciones vectoriales de la entidad enésima y la dirección IP. Se puede interpretar como cuánto más probable sería observar este evento en realidad que en un conjunto de datos generado de forma aleatoria. Durante el entrenamiento, el algoritmo utiliza esta puntuación para calcular una estimación de la probabilidad de una muestra procedente de la distribución real, pn, para el uso en la minimización de entropía cruzada.