Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cómo funciona Object2Vec
Al utilizar el algoritmo Object2Vec de Amazon SageMaker AI, se sigue el flujo de trabajo estándar: se procesan los datos, se entrena el modelo y se producen inferencias.
Paso 1: Procesar datos
Durante el procesamiento previo, convierta los datos al formato de archivo de texto Líneas de JSONnp.random.shuffle; para Unix, shuf.
Paso 2: Capacitar un modelo
El algoritmo SageMaker AI Object2Vec tiene los siguientes componentes principales:
-
Dos canales de entrada: los canales de entrada toman como entradas un par de objetos del mismo tipo o de tipos diferentes y los pasan a codificadores independientes y personalizables.
-
Dos codificadores: los codificadores enc0 y enc1 convierten cada uno de los objetos en un vector de integración de longitud fija. Luego las integraciones codificadas de los objetos del par se transfieren a un comparador.
-
Un comparador: el comparador compara las incrustaciones de diferentes maneras y genera puntuaciones que indican la fuerza de la relación entre los objetos emparejados. En la puntuación obtenida para un par de frases. Por ejemplo, 1 indica una relación estrecha entre un par de frases y 0 representa una relación menos fuerte.
Durante la capacitación, el algoritmo acepta pares de objetos y sus etiquetas de relación o puntuaciones como entradas. Los objetos de cada par pueden ser de diferentes tipos, tal y como se ha descrito anteriormente. Si las entradas a ambos codificadores están compuestas por las mismas unidades de nivel de token, puede utilizar una capa de integración de token compartida estableciendo el hiperparámetro tied_token_embedding_weight en True al crear el trabajo de capacitación. Esto es posible, por ejemplo, al comparar frases que tienen ambas unidades de nivel de token de palabra. Para generar muestras negativas a una velocidad especificada, establezca el hiperparámetro negative_sampling_rate en la proporción deseada de muestras negativas a positivas. Este hiperparámetro acelera el aprendizaje de cómo distinguir entre las muestras positivas observada en los datos de capacitación y las muestras negativas que no es probable que se observen.
Se pasan pares de objetos a través de codificadores personalizables e independientes que son compatibles con los tipos de entrada de objetos correspondientes. Los codificadores convierten cada uno de los objetos de un par en un vector de integración de longitud fija de igual longitud. El par de vectores se transfieren a un operador comparador, que combina los vectores en un solo vector con el valor especificado en el hiperparámetro comparator_list. Luego, el vector montado pasa por una capa perceptron multicapa (MLP), que produce una salida que la función de pérdida compara con las etiquetas que se han proporcionado. Esta comparación evalúa la fuerza de la relación entre los objetos del par, según prevé el modelo. En la siguiente figura se muestra este flujo de trabajo.
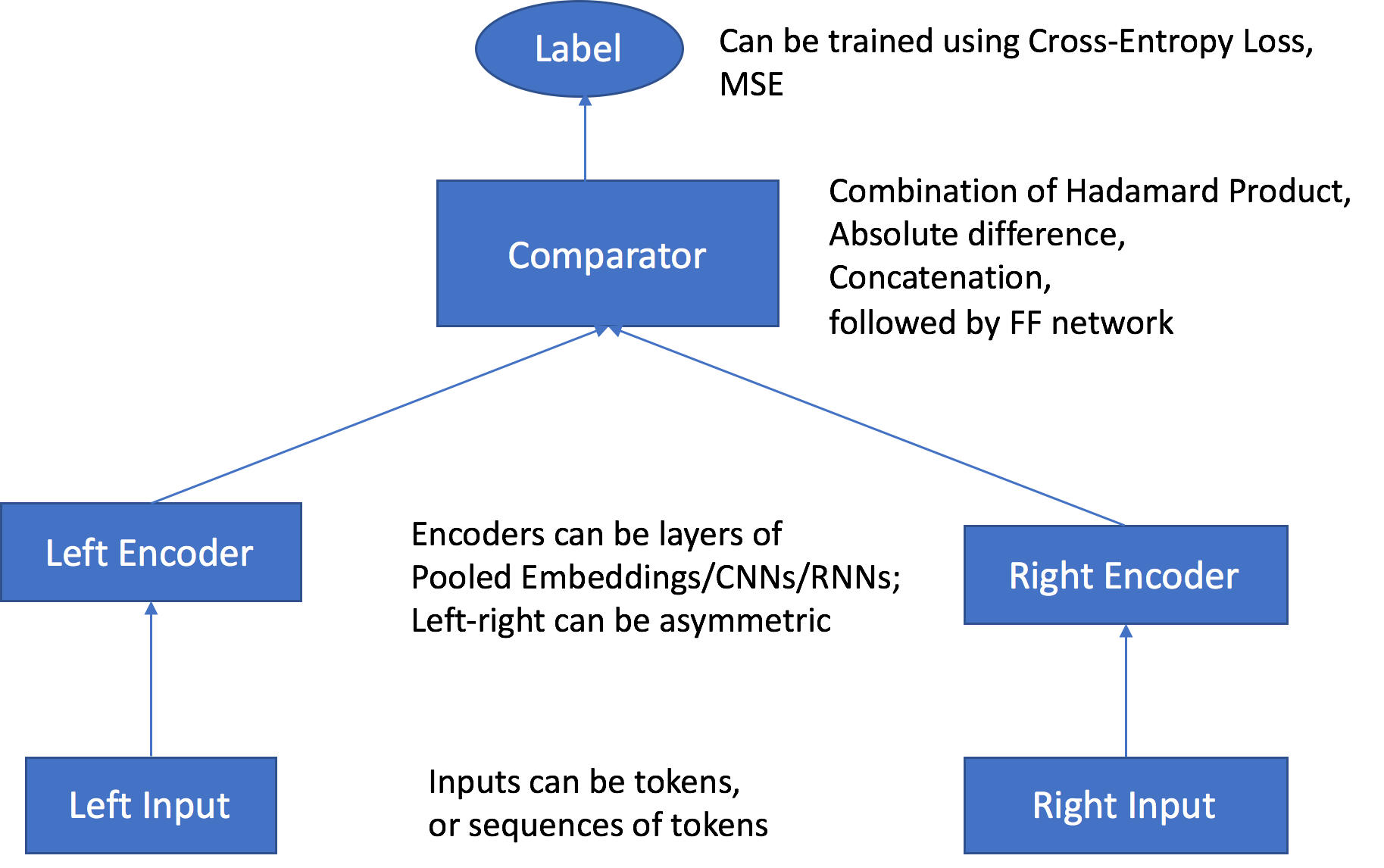
Arquitectura del algoritmo Object2Vec desde entradas de datos hasta puntuaciones
Paso 3: Producir inferencias
Una vez que el modelo está capacitado, puede utilizar el codificador capacitado para preprocesar los objetos de entrada o para realizar dos tipos de inferencia:
-
Para convertir objetos de entrada de singleton en integraciones de longitud fija mediante el codificador correspondiente
-
Para predecir la etiqueta de relación o puntuación entre un par de objetos de entrada
El servidor de inferencia descubre automáticamente cuál de los tipos es solicitado en función de los datos de entrada. Para obtener las integraciones como salida, proporcione una única entrada. Para predecir la etiqueta de relación o puntuación, proporcione ambas entradas del par.
