Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Utilice el aprendizaje por refuerzo con Amazon SageMaker AI
El aprendizaje por refuerzo (RL) combina campos como la informática, la neurociencia y la psicología para determinar cómo se asignan situaciones a acciones para maximizar una señal de recompensa numérica. Esta noción de señal de recompensa en RL proviene de investigaciones neurocientíficas sobre cómo el cerebro humano toma decisiones para maximizar la recompensa y minimizar el castigo. En la mayoría de las situaciones, los seres humanos no reciben instrucciones explícitas sobre las acciones que deben realizar, sino que aprenden qué acciones producen recompensas más inmediatas y cómo esas acciones influyen en las situaciones y consecuencias futuras.
El problema del RL se formaliza mediante procesos de decisión de Markov (MDPs) que se originan en la teoría de sistemas dinámicos. MDPs tienen como objetivo capturar detalles de alto nivel sobre un problema real al que se enfrenta un agente de aprendizaje durante un período de tiempo al intentar lograr algún objetivo final. El agente de aprendizaje debe determinar el estado actual de su entorno e identificar las posibles acciones que afectan al estado actual del agente de aprendizaje. Además, los objetivos del agente de aprendizaje deben estar estrechamente relacionados con el estado del entorno. Una solución a un problema formulada de este modo se denomina método de aprendizaje por refuerzo.
¿Cuáles son las diferencias entre los paradigmas de aprendizaje por refuerzo, supervisado y no supervisado?
Machine learning se puede dividir en tres paradigmas de aprendizaje distintos: supervisado, no supervisado y por refuerzo.
En aprendizaje supervisado, un supervisor externo ofrece un conjunto de entrenamiento de ejemplos etiquetados. Cada ejemplo contiene información sobre una situación, pertenece a una categoría y tiene una etiqueta que identifica la categoría a la que pertenece. El objetivo del aprendizaje supervisado es generalizar para predecir correctamente situaciones que no están presentes en los datos de entrenamiento.
Por su parte, RL se ocupa de problemas interactivos, lo que hace inviable recopilar todos los ejemplos posibles de situaciones con las etiquetas correctas que pueda encontrar un agente. Este tipo de aprendizaje es más prometedor cuando un agente puede aprender con precisión de su propia experiencia y ajustarse en consecuencia.
En el aprendizaje no supervisado, un agente aprende descubriendo una estructura en datos no etiquetados. Si bien un agente de RL podría beneficiarse de descubrir una estructura basada en sus experiencias, el único propósito de RL es maximizar una señal de recompensa.
¿Por qué es importante el aprendizaje por refuerzo?
RL es idóneo para resolver problemas grandes y complejos, por ejemplo, gestión de la cadena de suministro, sistemas de climatización, robótica industrial, inteligencia artificial para videojuegos, sistemas de diálogo y vehículos autónomos. Dado que los modelos de RL aprenden mediante un proceso continuo de recepción de recompensas y penalizaciones por cada acción realizada por el agente, es posible entrenar a los sistemas para que tomen decisiones en entornos inciertos y dinámicos.
Proceso de decisión de Markov (MDP)
El RL se basa en modelos denominados Procesos de decisión de Markov (MDPs). Un MDP se compone de una serie de pasos temporales. Cada paso temporal consta de los elementos siguientes:
- Entorno
-
Define el espacio en el que el funciona el modelo de RL. Puede ser un entorno del mundo real o un simulador. Por ejemplo, si entrena un vehículo autónomo en una carretera física, se trataría de un entorno del mundo real. Si entrena un programa informático que modela la conducción de vehículos autónomos en una carretera, se trataría de un simulador.
- Estado
-
Especifica toda la información sobre el entorno y los pasos anteriores que son pertinentes para el futuro. Por ejemplo, en un modelo de RL en el que un robot puede moverse en cualquier dirección, en cualquier paso temporal, la posición del robot en el paso temporal actual es el estado, ya que si sabemos dónde está el robot, no es necesario conocer los pasos que siguió para llegar ahí.
- Acción
-
Lo que hace el agente. Por ejemplo, el robot avanza un paso.
- Recompensa
-
Número que representa el valor del estado que se ha producido como consecuencia de la última acción que ejecutó el agente. Por ejemplo, si el objetivo es que un robot encuentre un tesoro, la recompensa por encontrar el tesoro podría ser 5 y la recompensa por no encontrarlo podría ser 0. El modelo de RL intenta encontrar una estrategia que optimice la recompensa acumulada a largo plazo. Esta estrategia se denomina política.
- Observación
-
Información sobre el estado del entorno que está disponible para el agente en cada paso. Puede ser todo el estado o solo una parte del estado. Por ejemplo, el agente de un modelo de partida de ajedrez podría observar todo el estado del tablero en cualquier paso, pero un robot en un laberinto podría observar solo la pequeña parte del laberinto que ocupa en ese momento.
Normalmente, el entrenamiento en RL se compone de muchos episodios. Un episodio se compone de todos los pasos temporales de un MDP, desde el estado inicial hasta que el entorno llega al estado terminal.
Características principales de Amazon SageMaker AI RL
Para entrenar modelos RL en SageMaker AI RL, utilice los siguientes componentes:
-
Un fotograma de aprendizaje profundo (DL). Actualmente, SageMaker AI admite RL en TensorFlow Apache MXNet.
-
Un conjunto de herramientas de RL. Un conjunto de herramientas de RL administra la interacción entre el agente y el entorno, y proporciona una amplia selección de los algoritmos de RL más avanzados. SageMaker La IA es compatible con los RLlib kits de herramientas Intel Coach y Ray. Para obtener información acerca de Intel Coach, consulte https://nervanasystems.github.io/coach/
. Para obtener información sobre Ray RLlib, consulte https://ray.readthedocs.io/en/latest/rllib.html . -
Un entorno de RL. Puede utilizar entornos personalizados, de código abierto o comerciales. Para obtener más información, consulte Entornos de RL en Amazon SageMaker AI.
El siguiente diagrama muestra los componentes de RL compatibles con SageMaker AI RL.
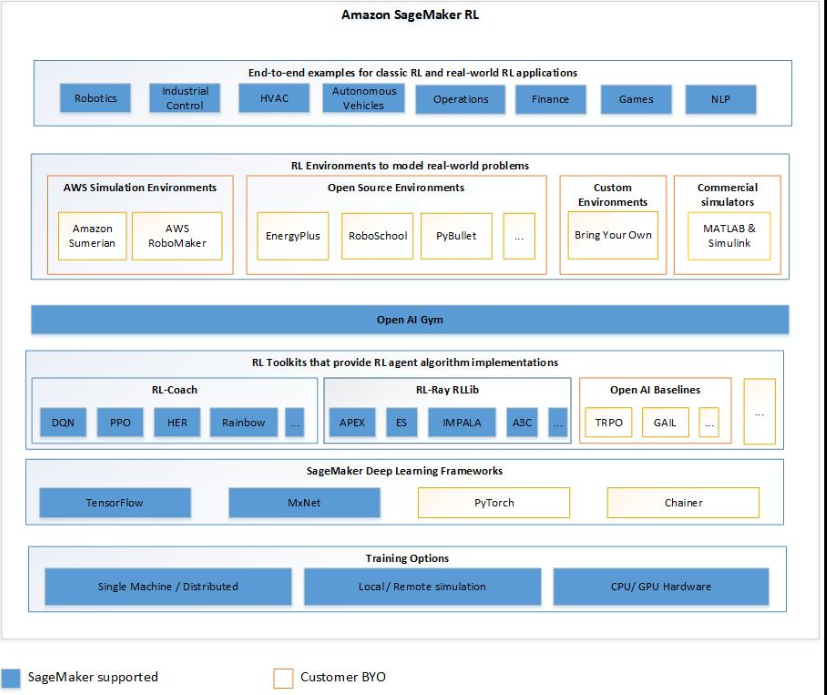
Cuadernos de ejemplo para aprendizaje por refuerzo
Para ver ejemplos de código completos, consulta los cuadernos de muestra de aprendizaje por refuerzo
