Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Utilice Amazon SageMaker Profiler para perfilar las actividades en los AWS recursos informáticos
|
Amazon SageMaker Profiler se encuentra actualmente en versión preliminar y está disponible sin coste alguno si es compatible Regiones de AWS. La versión general de Amazon SageMaker Profiler (si existe) puede incluir funciones y precios diferentes a los que se ofrecen en la versión preliminar. |
Amazon SageMaker Profiler es una función de Amazon SageMaker que proporciona una vista detallada de los recursos AWS informáticos aprovisionados durante el entrenamiento de modelos de aprendizaje profundo. SageMaker Se centra en la creación de perfiles del GPU uso, la CPU ejecución del núcleo, el inicio del núcleoGPUs, la sincronización de las operacionesCPUs, las operaciones de memoria entre ellos, las latencias entre los lanzamientos del núcleo CPUs y GPUs las ejecuciones correspondientes, y la transferencia de datos entre y. CPUs GPUs SageMaker Profiler también ofrece una interfaz de usuario (UI) que visualiza el perfil, un resumen estadístico de los eventos perfilados y el cronograma de un trabajo de capacitación para rastrear y comprender la relación temporal de los eventos entre y. GPUs CPUs
nota
SageMaker Profiler admite PyTorch TensorFlow y está disponible en AWS Deep Learning Containers para SageMaker
Para científicos de datos
El entrenamiento de modelos de aprendizaje profundo en un clúster de computación grande suele tener problemas de optimización computacional, como cuellos de botella, latencias de lanzamiento del kernel, límite de memoria y bajo consumo de recursos.
Para identificar estos problemas de rendimiento computacional, es necesario analizar más a fondo los recursos de computación para comprender qué kernels introducen latencias y qué operaciones provocan cuellos de botella. Los científicos de datos pueden aprovechar la interfaz de usuario de SageMaker Profiler para visualizar el perfil detallado de los trabajos de formación. La interfaz de usuario proporciona un panel de control con gráficos resumidos y una interfaz de cronograma para realizar un seguimiento de todos los eventos de los recursos de computación. Los científicos de datos también pueden añadir anotaciones personalizadas para realizar un seguimiento de determinadas partes del trabajo de formación mediante los módulos SageMaker Profiler Python.
Para administradores
A través de la página de inicio de Profiler en la SageMaker consola o el SageMaker dominio, puede administrar los usuarios de la aplicación Profiler si es administrador de una AWS cuenta o dominio. SageMaker Cada usuario del dominio puede acceder a su propia aplicación Profiler con los permisos concedidos. Como SageMaker administrador y usuario del dominio, puede crear y eliminar la aplicación Profiler en función del nivel de permisos del que disponga.
Marcos, imágenes y tipos Regiones de AWS de instancias compatibles
Esta característica es compatible con los siguientes marcos de machine learning y Regiones de AWS.
nota
Para usar esta función, asegúrese de tener instalada al menos la versión 2.180.0
SageMaker imágenes de framework preinstaladas con Profiler SageMaker
SageMaker Profiler viene preinstalado en los siguientes AWS Deep Learning Containers para
PyTorchimágenes
| PyTorch versiones | AWS DLCimagen URI |
|---|---|
| 2.2.0 |
|
| 2.1.0 |
|
| 2.0.1 |
|
| 1.13.1 |
|
TensorFlow imágenes
| TensorFlow versiones | AWS DLCimagen URI |
|---|---|
| 2.13.0 |
|
| 2.12.0 |
|
| 2.11.0 |
|
importante
La distribución y el mantenimiento de los contenedores del marco de las tablas anteriores se rigen por la Política de soporte del marco gestionada por el servicio AWS Deep Learning Containers. Le recomendamos encarecidamente que actualice a las versiones de marco compatibles actualmente
nota
Si desea utilizar SageMaker Profiler para otras imágenes de framework o para sus propias imágenes de Docker, puede instalar SageMaker Profiler utilizando los archivos binarios del paquete Profiler SageMaker Python que se proporcionan en la siguiente sección.
SageMaker Archivos binarios del paquete Profiler Python
Si desea configurar su propio contenedor de Docker, usar SageMaker Profiler en otros contenedores prediseñados o instalar el paquete Profiler SageMaker Python de forma local TensorFlow, use uno de los siguientes archivos binarios. PyTorch En función de Python y de CUDA las versiones de su entorno, elija una de las siguientes opciones.
PyTorch
-
Python 3.8, 11.3: CUDA
https://smppy.s3.amazonaws.com/pytorch/cu113/smprof-0.3.334-cp38-cp38-linux_x86_64.whl -
Python 3.9, 11.7: CUDA
https://smppy.s3.amazonaws.com/pytorch/cu117/smprof-0.3.334-cp39-cp39-linux_x86_64.whl -
Python 3.10, 11.8: CUDA
https://smppy.s3.amazonaws.com/pytorch/cu118/smprof-0.3.334-cp310-cp310-linux_x86_64.whl -
Python 3.10, CUDA 12.1:
https://smppy.s3.amazonaws.com/pytorch/cu121/smprof-0.3.334-cp310-cp310-linux_x86_64.whl
TensorFlow
-
Python 3.9, CUDA 11.2:
https://smppy.s3.amazonaws.com/tensorflow/cu112/smprof-0.3.334-cp39-cp39-linux_x86_64.whl -
Python 3.10, 11.8: CUDA
https://smppy.s3.amazonaws.com/tensorflow/cu118/smprof-0.3.334-cp310-cp310-linux_x86_64.whl
Para obtener más información sobre cómo instalar SageMaker Profiler mediante los archivos binarios, consulte. (Opcional) Instale el paquete SageMaker Profiler Python
Compatible Regiones de AWS
SageMaker El generador de perfiles está disponible en las siguientes Regiones de AWS versiones.
-
Este de EE. UU. (Norte de Virginia) (
us-east-1) -
Este de EE. UU. (Ohio) (
us-east-2) -
Oeste de EE. UU. (Oregón) (
us-west-2) -
Europa (Fráncfort) (
eu-central-1) -
Europa (Irlanda) (
eu-west-1)
Tipos de instancias admitidas
SageMaker Profiler admite la creación de perfiles de los trabajos de formación en los siguientes tipos de instancias.
CPUy creación de perfiles GPU
-
ml.g4dn.12xlarge -
ml.g5.24xlarge -
ml.g5.48xlarge -
ml.p3dn.24xlarge -
ml.p4de.24xlarge -
ml.p4d.24xlarge -
ml.p5.48xlarge
GPUsolo elaboración de perfiles
-
ml.g5.2xlarge -
ml.g5.4xlarge -
ml.g5.8xlarge -
ml.g5.16.xlarge
Requisitos previos
La siguiente lista muestra los requisitos previos para empezar a utilizar SageMaker Profiler.
-
Un SageMaker dominio configurado con Amazon VPC en tu AWS cuenta.
Para obtener instrucciones sobre cómo configurar un dominio, consulta Cómo incorporar un SageMaker dominio de Amazon mediante una configuración rápida. También debes añadir perfiles de usuario de dominio para que los usuarios individuales puedan acceder a la aplicación de interfaz de usuario Profiler. Para obtener más información, consulte Añadir y eliminar perfiles de usuario de SageMaker dominio.
-
La siguiente lista es el conjunto mínimo de permisos para usar la aplicación de interfaz de usuario Generador de perfiles.
-
sagemaker:CreateApp -
sagemaker:DeleteApp -
sagemaker:DescribeTrainingJob -
sagemaker:Search -
s3:GetObject -
s3:ListBucket
-
Prepare y ejecute un trabajo de formación con SageMaker Profiler
La configuración para ejecutar un trabajo de formación con el SageMaker Profiler consta de dos pasos: adaptar el guion de formación y configurar el lanzador de tareas de SageMaker formación.
Temas
Paso 1: Adapte su script de entrenamiento con los módulos SageMaker Profiler Python
Para empezar a capturar las ejecuciones del núcleo GPUs mientras se ejecuta el trabajo de entrenamiento, modifique el script de entrenamiento mediante los módulos Python de SageMaker Profiler. Importe la biblioteca y añada los métodos start_profiling() y stop_profiling() para definir el principio y el final de la creación de perfiles. También puede utilizar anotaciones personalizadas opcionales para añadir marcadores en el script de entrenamiento a fin de visualizar las actividades del hardware durante determinadas operaciones de cada paso.
Tenga en cuenta que los anotadores extraen las operaciones de. GPUs Para realizar operaciones de creación de perfilesCPUs, no es necesario añadir ninguna anotación adicional. CPULa creación de perfiles también se activa al especificar la configuración de creación de perfiles, con la que practicará. Paso 2: Cree un estimador de SageMaker marcos y active Profiler SageMaker
nota
Elaborar un perfil de todo un trabajo de entrenamiento no es el uso más eficiente de los recursos. Recomendamos perfilar un máximo de 300 pasos de un trabajo de entrenamiento.
importante
La versión en curso 14 de diciembre de 2023 implica un cambio radical. El nombre del paquete SageMaker Profiler Python se cambia de smppy asmprof. Esto es efectivo en los contenedores de SageMaker Framework
Si utiliza una de las versiones anteriores de SageMaker Framework Containerssmppy Si no está seguro de qué versión o del nombre del paquete debe utilizar, sustituya la declaración de importación del paquete SageMaker Profiler por el siguiente fragmento de código.
try: import smprof except ImportError: # backward-compatability for TF 2.11 and PT 1.13.1 images import smppy as smprof
Método 1. Utilice el administrador de contexto smprof.annotate para anotar todas las funciones
Puede agrupar todas las funciones con el smprof.annotate() administrador de contexto. Se recomienda utilizar este contenedor si desea crear perfiles por funciones en lugar de por líneas de código. El siguiente script de ejemplo muestra cómo implementar el administrador de contexto para encapsular el ciclo de entrenamiento y todas las funciones en cada iteración.
import smprof SMProf = smprof.SMProfiler.instance() config = smprof.Config() config.profiler = { "EnableCuda": "1", } SMProf.configure(config) SMProf.start_profiling() for epoch in range(args.epochs): if world_size > 1: sampler.set_epoch(epoch) tstart = time.perf_counter() for i, data in enumerate(trainloader, 0): with smprof.annotate("step_"+str(i)): inputs, labels = data inputs = inputs.to("cuda", non_blocking=True) labels = labels.to("cuda", non_blocking=True) optimizer.zero_grad() with smprof.annotate("Forward"): outputs = net(inputs) with smprof.annotate("Loss"): loss = criterion(outputs, labels) with smprof.annotate("Backward"): loss.backward() with smprof.annotate("Optimizer"): optimizer.step() SMProf.stop_profiling()
Método 1. Utilice smprof.annotation_begin() y smprof.annotation_end() anote una línea de código específica en funciones
También puede definir anotaciones para perfilar líneas de código específicas. Puede establecer el punto de inicio y el punto de conexión exactos de la creación de perfiles a nivel de líneas de código individuales, no mediante las funciones. Por ejemplo, en el siguiente script, el step_annotator se define el al principio de cada iteración y termina al final de la iteración. Mientras tanto, se definen otros anotadores detallados para cada operación y encapsulan las operaciones objetivo a lo largo de cada iteración.
import smprof SMProf = smprof.SMProfiler.instance() config = smprof.Config() config.profiler = { "EnableCuda": "1", } SMProf.configure(config) SMProf.start_profiling() for epoch in range(args.epochs): if world_size > 1: sampler.set_epoch(epoch) tstart = time.perf_counter() for i, data in enumerate(trainloader, 0): step_annotator = smprof.annotation_begin("step_" + str(i)) inputs, labels = data inputs = inputs.to("cuda", non_blocking=True) labels = labels.to("cuda", non_blocking=True) optimizer.zero_grad() forward_annotator = smprof.annotation_begin("Forward") outputs = net(inputs) smprof.annotation_end(forward_annotator) loss_annotator = smprof.annotation_begin("Loss") loss = criterion(outputs, labels) smprof.annotation_end(loss_annotator) backward_annotator = smprof.annotation_begin("Backward") loss.backward() smprof.annotation_end(backward_annotator) optimizer_annotator = smprof.annotation_begin("Optimizer") optimizer.step() smprof.annotation_end(optimizer_annotator) smprof.annotation_end(step_annotator) SMProf.stop_profiling()
Tras anotar y configurar los módulos de iniciación del generador de perfiles, guarde el guion para enviarlo mediante un lanzador de tareas de SageMaker formación en el siguiente paso 2. En el ejemplo del lanzador se presupone que el script de entrenamiento se llama train_with_profiler_demo.py.
Paso 2: Cree un estimador de SageMaker marcos y active Profiler SageMaker
El siguiente procedimiento muestra cómo preparar un estimador de SageMaker marco para el entrenamiento con Python SageMaker . SDK
-
Configure un objeto
profiler_configmediante los módulosProfilerConfigyProfilerde la siguiente manera.from sagemaker import ProfilerConfig, Profiler profiler_config = ProfilerConfig( profile_params = Profiler(cpu_profiling_duration=3600) )La siguiente es la descripción del módulo
Profilery su argumento.-
Profiler: El módulo para activar SageMaker Profiler con el trabajo de formación.-
cpu_profiling_duration(int): especifique la duración en segundos para activar la creación de perfiles. CPUs El valor predeterminado es de 3600 segundos.
-
-
-
Cree un estimador de SageMaker marco con el
profiler_configobjeto creado en el paso anterior. El código siguiente muestra un ejemplo de creación de un PyTorch estimador. Si desea crear un TensorFlow estimador, impórtelosagemaker.tensorflow.TensorFlowen su lugar y especifique una de TensorFlowlas versiones compatibles con Profiler. SageMaker Para obtener más información sobre los tipos de instancias admitidos, consulte SageMaker imágenes de framework preinstaladas con Profiler SageMaker .import sagemaker from sagemaker.pytorch import PyTorch estimator = PyTorch( framework_version="2.0.0", role=sagemaker.get_execution_role(), entry_point="train_with_profiler_demo.py", # your training job entry point source_dir=source_dir, # source directory for your training script output_path=output_path, base_job_name="sagemaker-profiler-demo", hyperparameters=hyperparameters, # if any instance_count=1, # Recommended to test with < 8 instance_type=ml.p4d.24xlarge, profiler_config=profiler_config) -
Inicie el trabajo de entrenamiento ejecutando el método
fit. Conwait=False, puede silenciar los registros de los trabajos de entrenamiento y dejar que se ejecuten en segundo plano.estimator.fit(wait=False)
Mientras ejecuta el trabajo de entrenamiento o una vez finalizado el trabajo, puede pasar al tema siguiente en Abre la aplicación de interfaz de SageMaker usuario Profiler y empezar a explorar y visualizar los perfiles guardados.
Si desea acceder directamente a los datos del perfil guardados en el bucket de Amazon S3, utilice el siguiente script para recuperar el S3URI.
import os # This is an ad-hoc function to get the S3 URI # to where the profile output data is saved def get_detailed_profiler_output_uri(estimator): config_name = None for processing in estimator.profiler_rule_configs: params = processing.get("RuleParameters", dict()) rule = config_name = params.get("rule_to_invoke", "") if rule == "DetailedProfilerProcessing": config_name = processing.get("RuleConfigurationName") break return os.path.join( estimator.output_path, estimator.latest_training_job.name, "rule-output", config_name, ) print( f"Profiler output S3 bucket: ", get_detailed_profiler_output_uri(estimator) )
(Opcional) Instale el paquete SageMaker Profiler Python
Para usar SageMaker Profiler en imágenes de TensorFlow marcos PyTorch o marcos que no figuran en SageMaker imágenes de framework preinstaladas con Profiler SageMaker él o en su propio contenedor Docker personalizado con fines de formación, puede instalar SageMaker Profiler mediante uno de los. SageMaker Archivos binarios del paquete Profiler Python
Opción 1: Instale el paquete SageMaker Profiler al iniciar un trabajo de formación
Si desea utilizar SageMaker Profiler para realizar tareas de formación con TensorFlow imágenes PyTorch o imágenes que no aparecen en ellasSageMaker imágenes de framework preinstaladas con Profiler SageMaker , cree un requirements.txt archivo y ubíquelo en la ruta que especifique para el source_dir parámetro del estimador de SageMaker marcos en el paso 2. Para obtener más información sobre la configuración de un requirements.txt archivo en general, consulte Uso de bibliotecas de tercerosrequirements.txt archivo, añada una de las rutas de bucket de S3 paraSageMaker Archivos binarios del paquete Profiler Python.
# requirements.txt https://smppy.s3.amazonaws.com/tensorflow/cu112/smprof-0.3.332-cp39-cp39-linux_x86_64.whl
Opción 2: instale el paquete SageMaker Profiler en sus contenedores Docker personalizados
Si utilizas un contenedor Docker personalizado para la formación, añade uno de ellos SageMaker Archivos binarios del paquete Profiler Python a tu Dockerfile.
# Install the smprof package version compatible with your CUDA version RUN pip install https://smppy.s3.amazonaws.com/tensorflow/cu112/smprof-0.3.332-cp39-cp39-linux_x86_64.whl
Para obtener información sobre cómo ejecutar un contenedor Docker personalizado para el entrenamiento SageMaker en general, consulta Cómo adaptar tu propio contenedor de entrenamiento.
Abre la aplicación de interfaz de SageMaker usuario Profiler
Puede acceder a la aplicación de interfaz de usuario SageMaker Profiler a través de las siguientes opciones.
Temas
- Opción 1: inicie la interfaz de usuario del SageMaker generador de perfiles desde la página de detalles del dominio
- Opción 2: inicie la aplicación de interfaz de usuario de SageMaker Profiler desde la página de inicio de SageMaker Profiler de la consola SageMaker
- Opción 3: usar la función de inicio de aplicaciones en Python SageMaker SDK
Opción 1: inicie la interfaz de usuario del SageMaker generador de perfiles desde la página de detalles del dominio
Si tiene acceso a la SageMaker consola, puede utilizar esta opción.
Ve a la página de detalles del dominio
El siguiente procedimiento muestra cómo ir a la página de detalles del dominio.
-
Abre la SageMaker consola de Amazon en https://console.aws.amazon.com/sagemaker/
. -
En el panel de navegación izquierdo, selecciona dominios.
-
En la lista de dominios, seleccione el dominio en el que desee iniciar la aplicación SageMaker Profiler.
Inicie la aplicación de interfaz de SageMaker usuario Profiler
El siguiente procedimiento muestra cómo iniciar la aplicación SageMaker Profiler que está relacionada con un perfil de usuario.
-
En la página de detalles del dominio, seleccione la pestaña Perfiles de usuario.
-
Identifique el perfil de usuario para el que desea iniciar la aplicación de interfaz de usuario SageMaker Profiler.
-
Elija Launch (Lanzar) para el perfil de usuario seleccionado y elija Profiler (Generador de perfiles).
Opción 2: inicie la aplicación de interfaz de usuario de SageMaker Profiler desde la página de inicio de SageMaker Profiler de la consola SageMaker
El siguiente procedimiento describe cómo iniciar la aplicación de interfaz de usuario de SageMaker Profiler desde la página de inicio de SageMaker Profiler de la consola. SageMaker Si tiene acceso a la SageMaker consola, puede utilizar esta opción.
-
Abre la SageMaker consola de Amazon en https://console.aws.amazon.com/sagemaker/
. -
En el panel de navegación izquierdo, seleccione Profiler (Generador de perfiles).
-
En Comenzar, selecciona el dominio en el que quieres lanzar la aplicación Studio Classic. Si su perfil de usuario solo pertenece a un dominio, no verá la opción para seleccionar un dominio.
-
Seleccione el perfil de usuario para el que desea iniciar la aplicación de interfaz de usuario SageMaker Profiler. Si no hay ningún perfil de usuario en el dominio, elija Crear perfil de usuario. Para obtener más información sobre la creación de un nuevo perfil de usuario, consulte Añadir y eliminar perfiles de usuario.
-
Seleccione Open Profiler (Abrir generador de perfiles).
Opción 3: usar la función de inicio de aplicaciones en Python SageMaker SDK
Si es un usuario de SageMaker dominio y solo tiene acceso a SageMaker Studio, puede acceder a la aplicación de interfaz de usuario SageMaker Profiler a través de SageMaker Studio Classic ejecutando la sagemaker.interactive_apps.detail_profiler_app.DetailProfilerApp
Ten en cuenta que SageMaker Studio Classic es la experiencia anterior a la interfaz de usuario de Studio antes de re:Invent 2023 y se migrará como aplicación a una interfaz de usuario de Studio de nuevo diseño en re:Invent 2023. La aplicación de interfaz de usuario SageMaker Profiler está disponible a nivel de SageMaker dominio y, por lo tanto, requiere tu ID de dominio y tu nombre de perfil de usuario. Actualmente, la DetailedProfilerApp función solo funciona en la aplicación SageMaker Studio Classic; la función recoge correctamente la información del dominio y del perfil de usuario de SageMaker Studio Classic.
Para dominios, usuarios de dominios y Studio creados antes de re:Invent 2023, Studio Classic sería la experiencia predeterminada, a menos que la hayas actualizado siguiendo las instrucciones de Migración desde Amazon SageMaker Studio Classic. Si este es tu caso, no es necesario realizar ninguna otra acción y puedes iniciar directamente la aplicación de interfaz de usuario SageMaker Profiler ejecutando la función. DetailProfilerApp
Si has creado un dominio y Studio nuevos después de re:Invent 2023, inicia la aplicación Studio Classic en la interfaz de usuario de Studio y, a continuación, ejecuta la DetailProfilerApp función para iniciar la aplicación de interfaz de usuario de Profiler. SageMaker
Ten en cuenta que la DetailedProfilerApp función no funciona en otras instancias de aprendizaje SageMaker automáticoIDEs, como la aplicación Studio, la JupyterLab aplicación SageMaker SageMaker Studio Code Editor y SageMaker las instancias de Notebook. Si ejecutas la DetailedProfilerApp función en ellasIDEs, volverá URL a la página de inicio de Profiler en la SageMaker consola, en lugar de a un enlace directo para abrir la aplicación de interfaz de usuario de Profiler.
Explore los datos de salida del perfil visualizados en la interfaz de usuario de Profiler SageMaker
En esta sección, se explica la interfaz de usuario del SageMaker generador de perfiles y se proporcionan consejos sobre cómo utilizarla y obtener información al respecto.
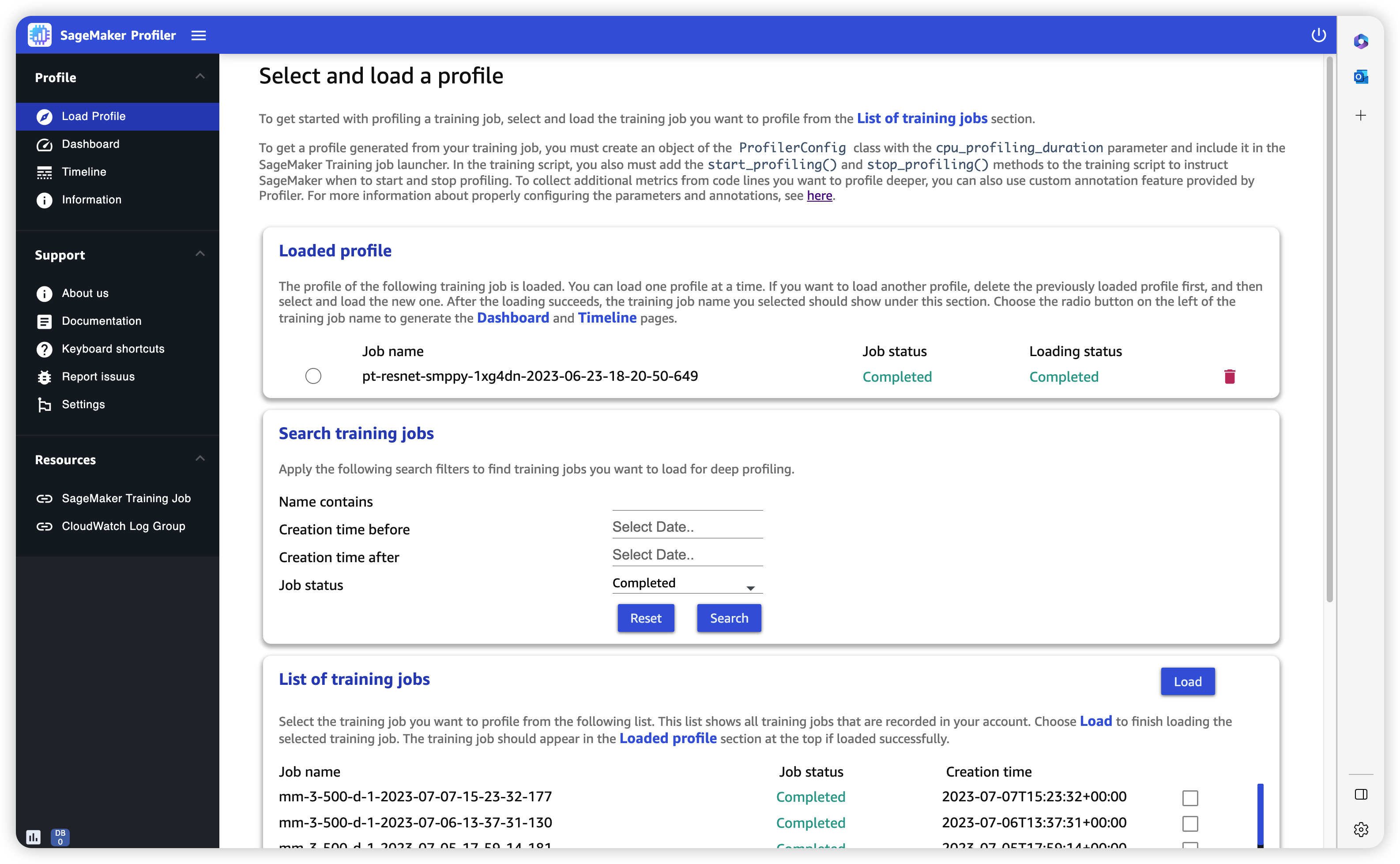
Cargar perfil
Al abrir la interfaz de usuario del SageMaker generador de perfiles, se abre la página Cargar perfil. Para cargar y generar Dashboard (Panel de control) y Timeline (Línea temporal), siga el siguiente procedimiento.
Para cargar el perfil de un trabajo de entrenamiento
-
En la sección List of training jobs (Lista de trabajos de entrenamiento), utilice la casilla de verificación para elegir el trabajo de entrenamiento para el que desea cargar el perfil.
-
Elija Load (Cargar). El nombre del trabajo debe aparecer en la sección Loaded profile (Perfil cargado), en la parte superior.
-
Pulse el botón de radio situado a la izquierda de Job name (Nombre del trabajo) para generar el Dashboard (Panel de control) y Timeline (Línea temporal). Tenga en cuenta que cuando selecciona el botón de opción, la interfaz de usuario abre automáticamente Dashboard (Panel de control). Tenga en cuenta también que si genera las visualizaciones mientras el estado del trabajo y el estado de carga aún parecen estar en curso, la interfaz de usuario del SageMaker generador de perfiles genera gráficos de panel y una cronología con los datos de perfil más recientes recopilados del trabajo de formación en curso o los datos del perfil cargados parcialmente.
sugerencia
Puede cargar y visualizar un perfil a la vez. Para cargar otro perfil, primero debe descargar el perfil cargado anteriormente. Para descargar un perfil, utilice el icono de la papelera situado en el extremo derecho del perfil, en la sección Loaded profile (Perfil cargado).
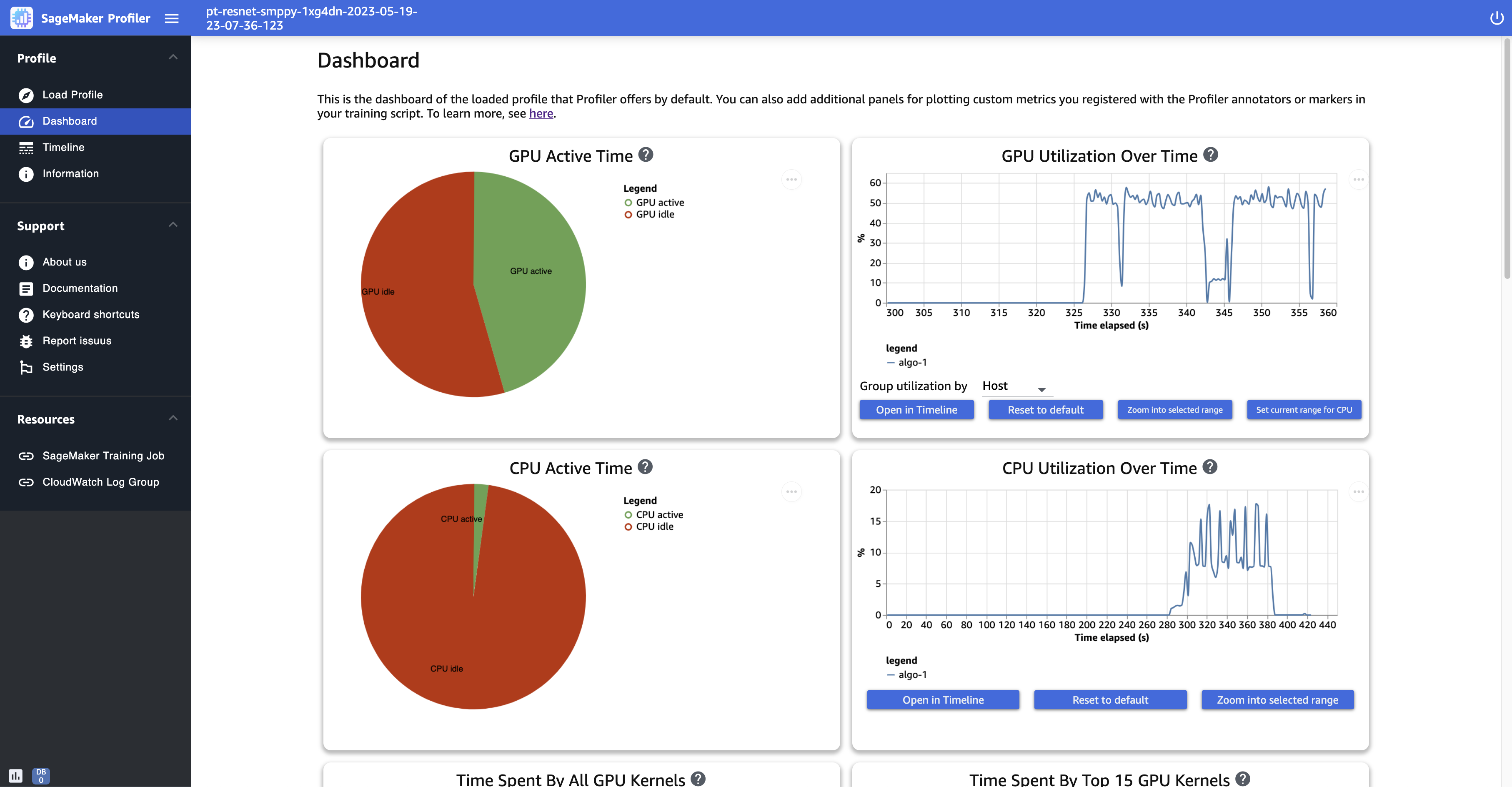
Panel de control
Cuando termine de cargar y seleccionar el trabajo de entrenamiento, la interfaz de usuario abre la página de Dahsboard (Panel de control), que incluye los siguientes paneles de forma predeterminada.
-
GPUtiempo activo: este gráfico circular muestra el porcentaje de tiempo GPU activo frente al tiempo de GPU inactividad. Puedes comprobar si GPUs estás más activo que inactivo durante todo el trabajo de formación. GPUel tiempo activo se basa en los puntos de datos del perfil con una tasa de utilización superior al 0%, mientras que el tiempo de GPU inactividad se basa en los puntos de datos perfilados con un 0% de utilización.
-
GPUutilización a lo largo del tiempo: este gráfico cronológico muestra la tasa de GPU utilización media a lo largo del tiempo por nodo y agrupa todos los nodos en un solo gráfico. Puede comprobar si GPUs tienen una carga de trabajo desequilibrada, problemas de infrautilización, cuellos de botella o problemas de inactividad durante determinados intervalos de tiempo. Para realizar un seguimiento de la tasa de utilización a GPU nivel individual y de las ejecuciones del núcleo relacionadas, utilice la. Interfaz de línea de tiempo Tenga en cuenta que la recopilación de GPU actividades comienza desde donde agregó la función de inicio del generador de perfiles
SMProf.start_profiling()en su guion de entrenamiento y termina enSMProf.stop_profiling(). -
CPUtiempo activo: este gráfico circular muestra el porcentaje de tiempo CPU activo frente al tiempo de CPU inactividad. Puedes comprobar si CPUs estás más activo que inactivo durante todo el trabajo de formación. CPUel tiempo activo se basa en los puntos de datos perfilados con una tasa de utilización superior al 0%, mientras que el tiempo de CPU inactividad se basa en los puntos de datos perfilados con un 0% de utilización.
-
CPUutilización a lo largo del tiempo: este gráfico cronológico muestra la tasa de CPU utilización media a lo largo del tiempo por nodo y agrupa todos los nodos en un único gráfico. Puede comprobar si CPUs están obstruidos o infrautilizados durante determinados intervalos de tiempo. Para hacer un seguimiento de la tasa de utilización en función de CPUs la GPU utilización individual y de las ejecuciones del núcleo, utilice la. Interfaz de línea de tiempo Tenga en cuenta que las métricas de uso comienzan desde el principio, desde la inicialización del trabajo.
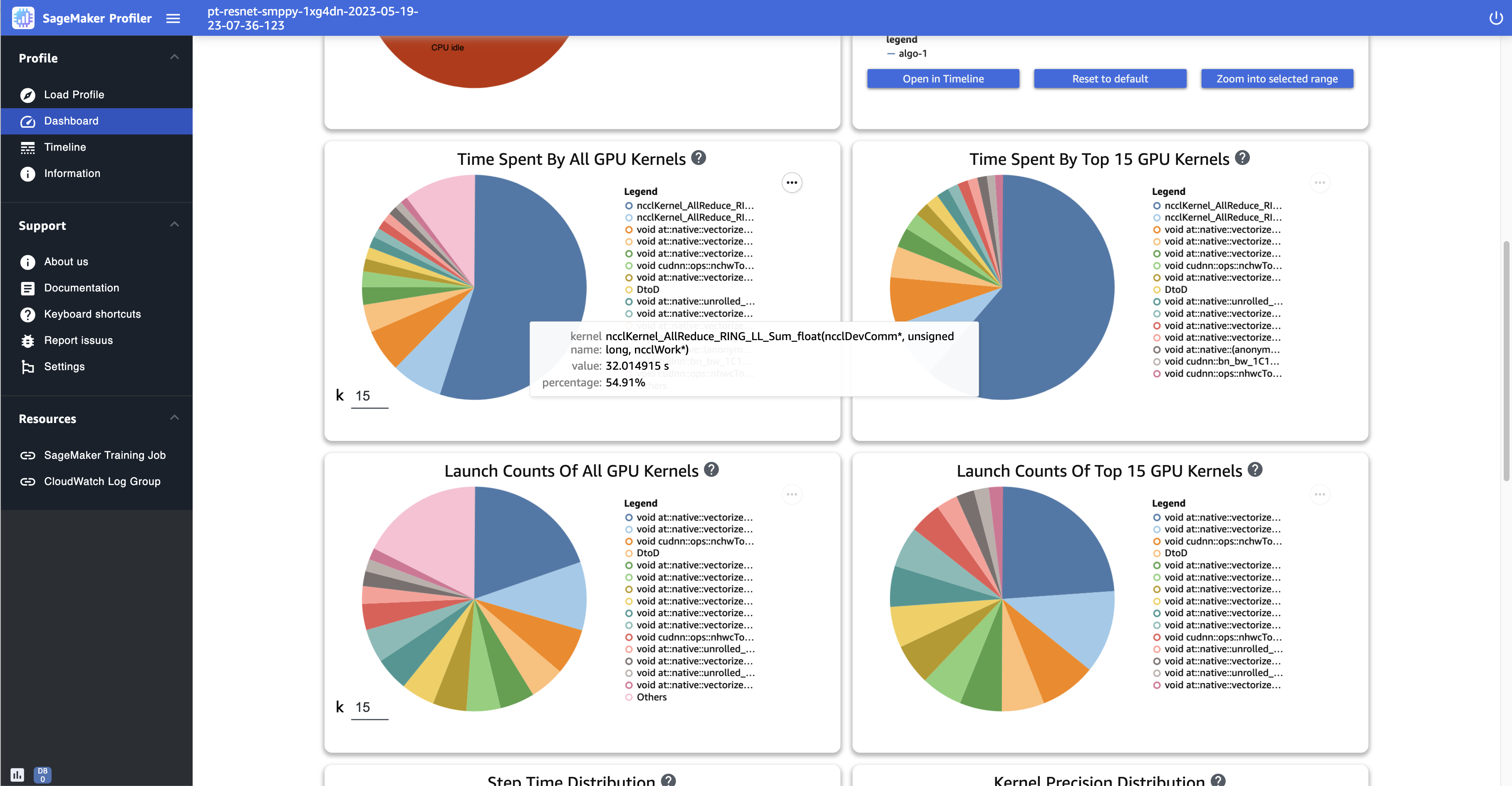
-
Tiempo empleado por todos los GPU núcleos: este gráfico circular muestra todos los GPU núcleos utilizados durante el trabajo de entrenamiento. Muestra los 15 GPU núcleos principales de forma predeterminada como sectores individuales y todos los demás núcleos en un sector. Pase el ratón sobre los sectores para ver información más detallada. El valor muestra el tiempo total de funcionamiento de GPU los núcleos en segundos y el porcentaje se basa en todo el tiempo del perfil.
-
Tiempo empleado por los 15 GPU granos principales: este gráfico circular muestra todos los GPU núcleos utilizados durante el trabajo de entrenamiento. Muestra los 15 GPU granos principales como sectores individuales. Pase el ratón sobre los sectores para ver información más detallada. El valor muestra el tiempo total de funcionamiento de GPU los núcleos en segundos y el porcentaje se basa en el tiempo total del perfil.
-
Recuentos de lanzamientos de todos los GPU núcleos: este gráfico circular muestra el número de recuentos de lanzamientos de cada GPU núcleo durante el trabajo de entrenamiento. Muestra los 15 GPU núcleos principales como sectores individuales y todos los demás núcleos en un sector. Pase el ratón sobre los sectores para ver información más detallada. El valor muestra el recuento total de los GPU núcleos lanzados y el porcentaje se basa en el recuento total de todos los núcleos.
-
Recuentos de lanzamientos de los 15 GPU núcleos principales: este gráfico circular muestra el número de lanzamientos de cada GPU núcleo durante el trabajo de entrenamiento. Muestra los 15 GPU núcleos principales. Pase el ratón sobre los sectores para ver información más detallada. El valor muestra el recuento total de los GPU núcleos lanzados y el porcentaje se basa en el recuento total de todos los núcleos.
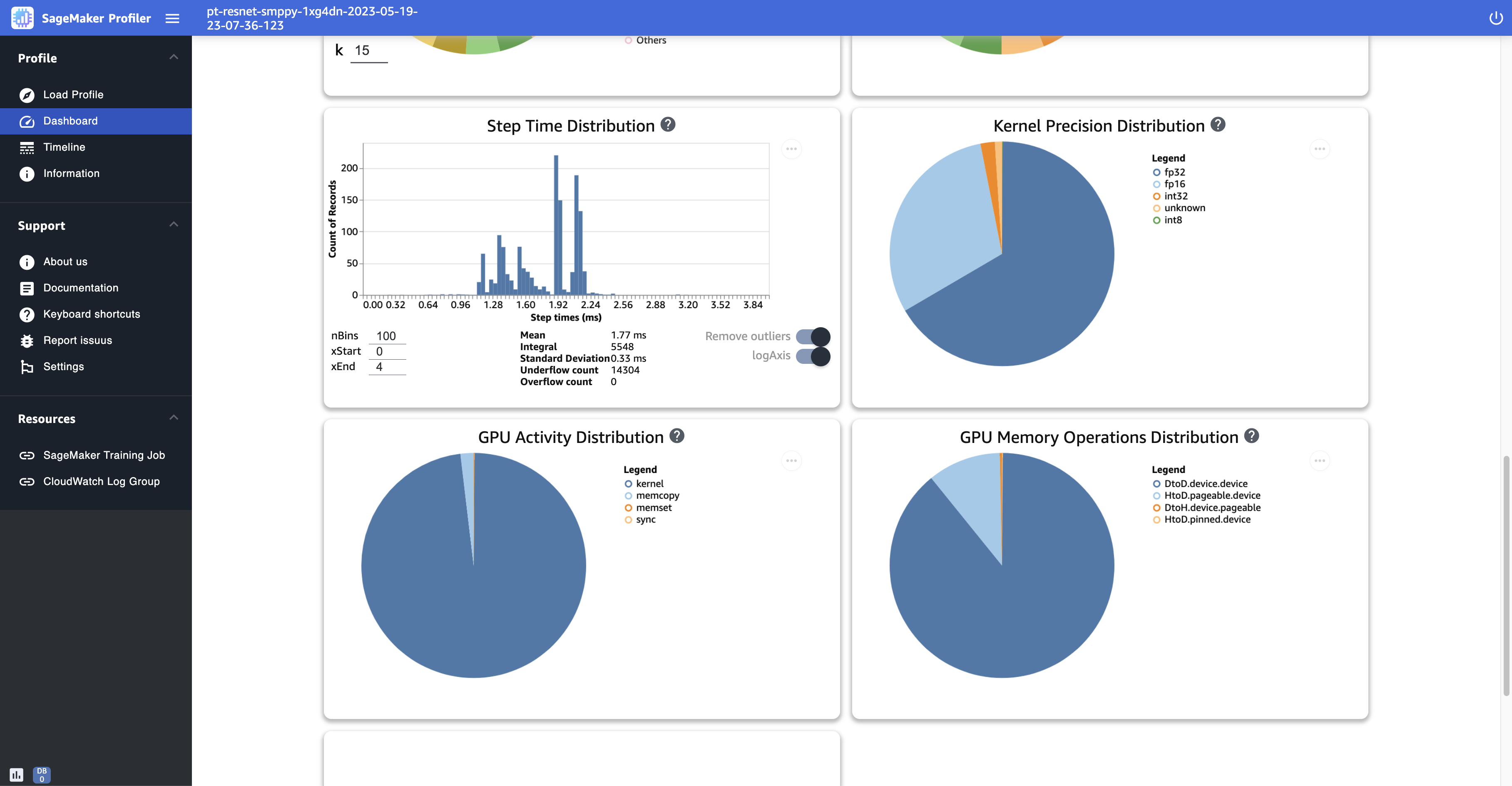
-
Distribución del tiempo de paso: este histograma muestra la distribución de las duraciones de los pasos. GPUs Este gráfico se genera solo después de añadir el anotador de pasos al script de entrenamiento.
-
Distribución de precisión del núcleo: este gráfico circular muestra el porcentaje de tiempo dedicado a ejecutar los núcleos en diferentes tipos de datosFP32, comoFP16, INT32 y. INT8
-
GPUdistribución de la actividad: este gráfico circular muestra el porcentaje de tiempo dedicado a GPU actividades, como la ejecución de los núcleos, la memoria (
memcpyymemset) y la sincronización (sync). -
GPUdistribución de las operaciones de memoria: este gráfico circular muestra el porcentaje de tiempo dedicado a las operaciones de GPU memoria. Esto visualiza las actividades
memcopyy ayuda a identificar si su trabajo de entrenamiento está dedicando demasiado tiempo a determinadas operaciones de memoria. -
Create a new histogram (Crear un histograma nuevo): cree un diagrama nuevo de una métrica personalizada que haya anotado manualmente durante Paso 1: Adapte su script de entrenamiento con los módulos SageMaker Profiler Python. Al añadir una anotación personalizada a un histograma nuevo, seleccione o escriba el nombre de la anotación que ha añadido en el script de entrenamiento. Por ejemplo, en el script de entrenamiento de demostración del paso 1,
step,Forward,Backward,OptimizeyLossestán las anotaciones personalizadas. Al crear un histograma nuevo, estos nombres de anotación deberían aparecer en el menú desplegable para seleccionar las métricas. Si eligeBackward, la interfaz de usuario añade al panel de control el histograma del tiempo dedicado a las pasadas hacia atrás a lo largo del tiempo perfilado. Este tipo de histograma es útil para comprobar si hay valores atípicos que tardan anormalmente más tiempo y provocan problemas de embotellamiento.
Las siguientes capturas de pantalla muestran la relación de tiempo CPU activo GPU y el promedio GPU y la tasa de CPU utilización con respecto al tiempo por nodo de cómputo.
La siguiente captura de pantalla muestra un ejemplo de gráficos circulares para comparar el número de veces que se lanzan los GPU núcleos y medir el tiempo empleado en ejecutarlos. En los paneles Tiempo empleado por todos los GPU núcleos y Recuentos de lanzamientos de todos los GPU núcleos, también puede especificar un número entero en el campo de entrada de k para ajustar el número de leyendas que se muestran en los gráficos. Por ejemplo, si especifica 10, los gráficos muestran los 10 kernels más ejecutados y lanzados, respectivamente.
La siguiente captura de pantalla muestra un ejemplo de paso, tiempo, duración, histograma y gráficos circulares para la distribución de precisión del núcleo, la distribución de la GPU actividad y la distribución de las operaciones de GPU la memoria.
Interfaz de línea de tiempo
Para obtener una visión detallada de los recursos informáticos a nivel de las operaciones y los núcleos programados CPUs y ejecutados en elGPUs, utilice la interfaz Timeline.
Puedes acercar y alejar la imagen y desplazarte hacia la izquierda o hacia la derecha en la interfaz de la línea de tiempo con el ratón, las teclas [w, a, s, d] o las cuatro teclas de flecha del teclado.
sugerencia
Para obtener más consejos sobre los métodos abreviados de teclado para interactuar con la interfaz de Timeline (Línea de tiempo), seleccione Keyboard shortcuts (Métodos abreviados de teclado) en el panel izquierdo.
Las pistas de la línea de tiempo están organizadas en una estructura de árbol, lo que proporciona información desde el nivel del host hasta el nivel del dispositivo. Por ejemplo, si ejecuta N instancias con ocho GPUs en cada una, la estructura temporal de cada instancia sería la siguiente.
-
algo-inode: estas son las SageMaker etiquetas que se utilizan para asignar los trabajos a las instancias aprovisionadas. El dígito inode se asigna de forma aleatoria. Por ejemplo, si usa 4 instancias, esta sección se expande de algo-1 a algo-4.
-
CPU— En esta sección, puede comprobar la tasa de CPU utilización media y los contadores de rendimiento.
-
GPUs— En esta sección, puede comprobar la tasa de GPU utilización media, la tasa de GPU utilización individual y los núcleos.
-
SUMUtilización: las tasas GPU de utilización promedio por instancia.
-
HOST-0 PID -123: un nombre exclusivo asignado a cada pista del proceso. El acrónimo PID es el ID del proceso y el número que se le adjunta es el número de ID del proceso que se registra durante la captura de datos del proceso. En esta sección se muestra la siguiente información del proceso.
-
GPU-i num_gpu utilización: tasa de utilización de la num_gpu i-ésima a lo GPU largo del tiempo.
-
GPU-i num_gpu dispositivo: el núcleo se ejecuta en el num_gpu i-ésimo GPU dispositivo.
-
stream i cuda_stream: CUDA secuencias que muestran que el núcleo se ejecuta en el GPU dispositivo. Para obtener más información sobre las CUDA transmisiones, consulte las diapositivas de PDF CUDAC/C++ Streams and Concurrency
proporcionadas por. NVIDIA
-
-
GPUnum_gpu-host: el núcleo se inicia en el host num_gpu GPU i-ésimo.
-
-
-
En las siguientes capturas de pantalla se muestra la cronología del perfil de un trabajo de formación realizado en ml.p4d.24xlarge instancias equipadas con 8 NVIDIA A100 Tensor Core en cada una. GPUs
La siguiente es una vista ampliada del perfil, en la que se imprimen una docena de pasos, incluido un cargador de datos intermitente entre step_232 y step_233 para recuperar el siguiente lote de datos.
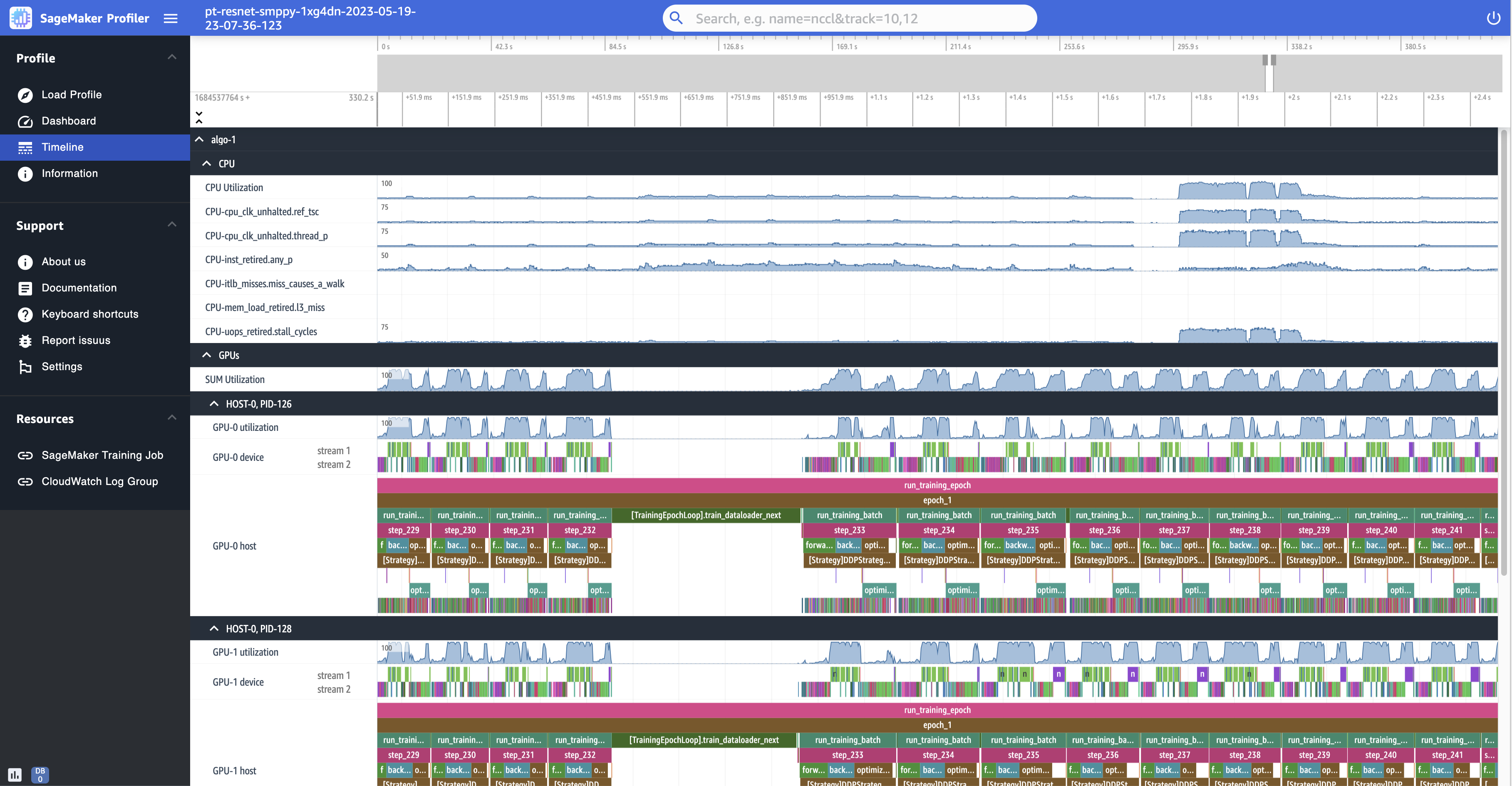
Para cada uno de ellosCPU, puede realizar un seguimiento de CPU los contadores de uso y rendimiento, como "clk_unhalted_ref.tsc" y"itlb_misses.miss_causes_a_walk", que son indicativos de las instrucciones que se ejecutan en el. CPU
Para cada uno de ellosGPU, puede ver un cronograma del anfitrión y un cronograma del dispositivo. Los lanzamientos del kernel se producen en la línea de tiempo del host y las ejecuciones del kernel se realizan en la línea temporal del dispositivo. También puedes ver las anotaciones (como avanzar, retroceder y optimizar) si has añadido un guion de entrenamiento a la cronología del GPU anfitrión.
En la vista de cronología, también puede realizar un seguimiento de los launch-and-run pares de núcleos. Esto le ayuda a entender cómo se ejecuta el lanzamiento del núcleo programado en un host (CPU) en el GPU dispositivo correspondiente.
sugerencia
Pulse la tecla f para ampliar el kernel seleccionado.
La siguiente captura de pantalla es una vista ampliada de step_233 y step_234 desde la captura de pantalla anterior. El intervalo temporal seleccionado en la siguiente captura de pantalla es la AllReduce operación, un paso esencial de comunicación y sincronización en el entrenamiento distribuido, que se ejecuta en el dispositivo GPU -0. En la captura de pantalla, observe que el inicio del núcleo en el host GPU -0 se conecta con el núcleo que se ejecuta en la secuencia de dispositivos GPU -0 1, indicada con una flecha en color cian.
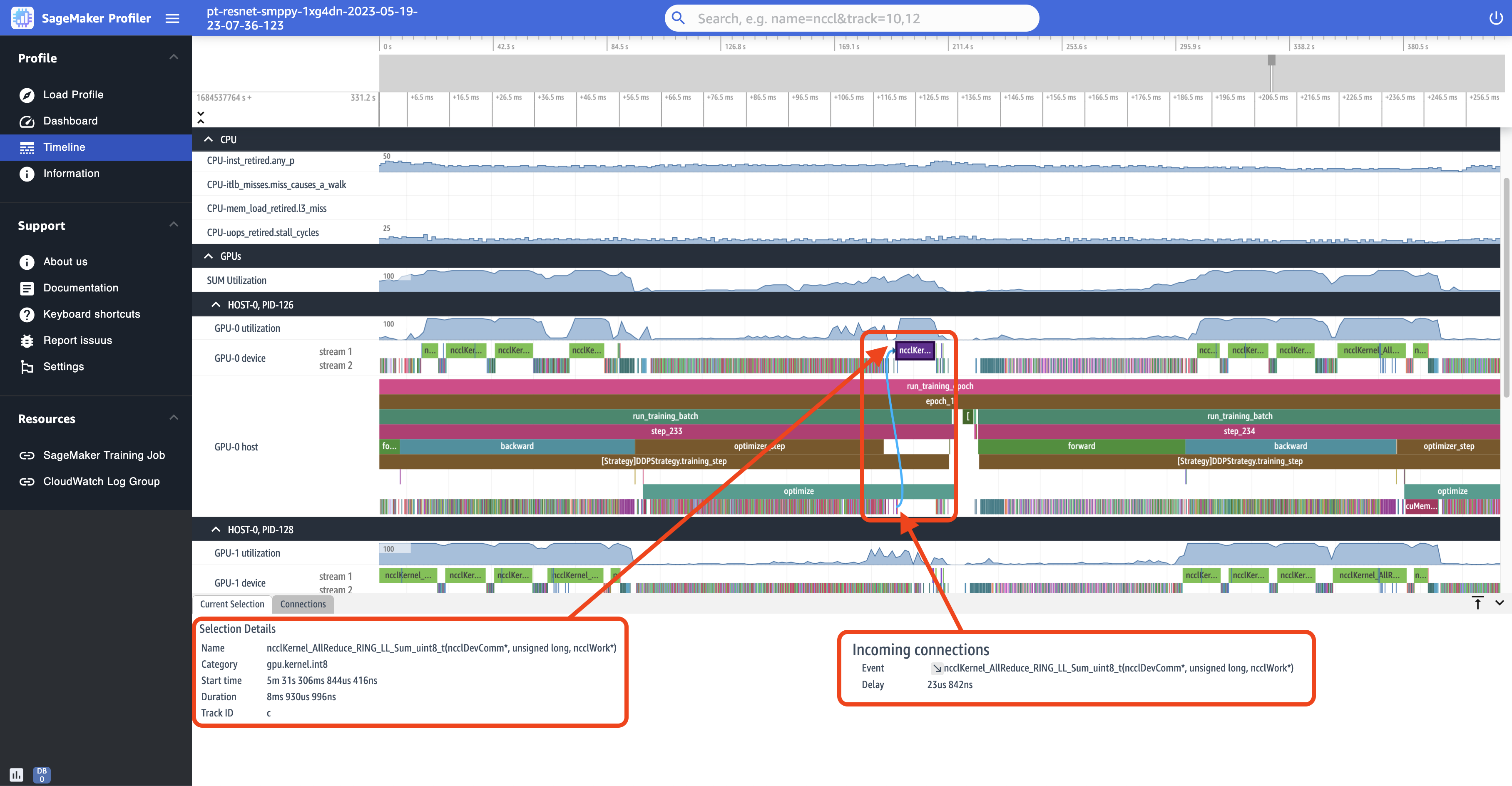
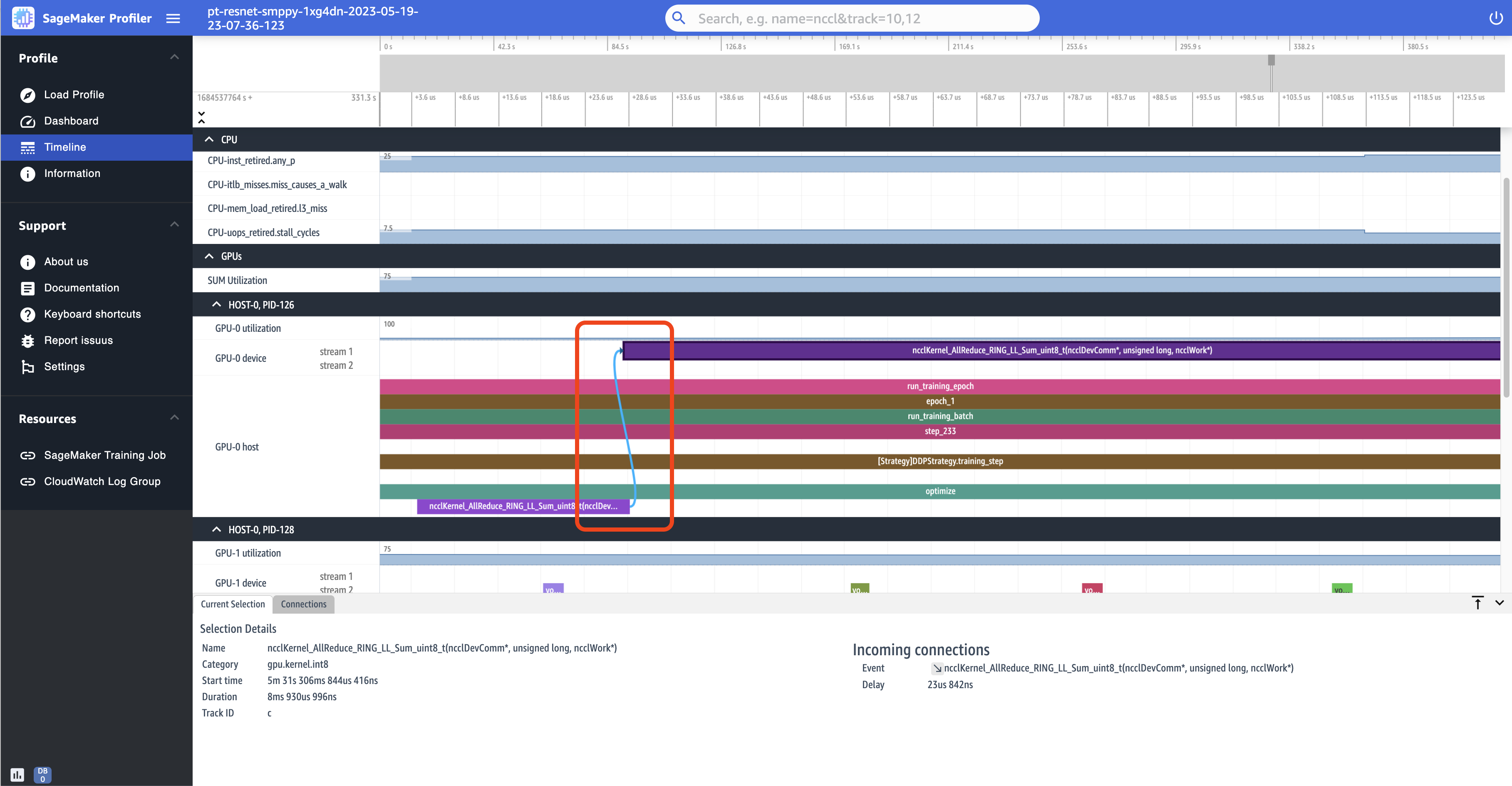
También aparecen dos pestañas de información en el panel inferior de la interfaz de usuario al seleccionar un intervalo de tiempo, como se muestra en la captura de pantalla anterior. La pestaña Current Selection (Selección actual) muestra los detalles del kernel seleccionado y del lanzamiento del kernel conectado desde el servidor. La dirección de la conexión es siempre del host (CPU) al dispositivo (GPU), ya que cada GPU núcleo siempre se llama desde unCPU. La pestaña Connections (Conexiones) muestra el par de inicio y ejecución del kernel elegido. Puede seleccionar cualquiera de ellas para moverla al centro de la vista Timeline (Línea de tiempo).
En la siguiente captura de pantalla se amplía aún más la combinación de inicio y ejecución de la operación AllReduce.
Información
En Información, puede acceder a la información sobre el trabajo de entrenamiento cargado, como el tipo de instancia, los nombres de los recursos de Amazon (ARNs) de los recursos informáticos aprovisionados para el trabajo, los nombres de los nodos y los hiperparámetros.
Configuración
De forma predeterminada, la instancia de la aplicación SageMaker Profiler UI está configurada para cerrarse tras 2 horas de inactividad. En Settings (Ajustes), use los siguientes parámetros para ajustar el temporizador de cierre automático.
-
Enable app auto shutdown (Habilitar el cierre de la aplicación): seleccione y configúrelo como Enabled (Habilitado) para permitir que la aplicación se cierre automáticamente después del número especificado de horas de inactividad. Para desactivar la función de apagado automático, selecciona DIsabled (Desactivado).
-
Auto shutdown threshold in hours (Umbral de cierre automático en horas): si selecciona Enabled (Habilitado) para Enable app auto shutdown (Habilitar apierre automático de aplicación), puede establecer el tiempo límite en horas para que la aplicación se cierre automáticamente. De forma predeterminada, se establece en 2.
Preguntas frecuentes sobre el uso de Profiler SageMaker
Utilice las siguientes preguntas frecuentes para encontrar respuestas sobre el uso de SageMaker Profiler.
P: Recibo un mensaje de error, ModuleNotFoundError: No
module named 'smppy'
Desde diciembre de 2023, el nombre del paquete SageMaker Profiler Python ha cambiado de smppy smprof a para resolver un problema de nombre de paquete duplicado; ya lo smppy usa un paquete de código abierto.
Por lo tanto, si lo ha estado utilizando smppy desde antes de diciembre de 2023 y tiene este ModuleNotFoundError problema, es posible que se deba a que el nombre del paquete de su script de entrenamiento estaba desactualizado mientras tenía el smprof paquete más reciente instalado o estaba utilizando uno de los últimos. SageMaker imágenes de framework preinstaladas con Profiler SageMaker En ese caso, asegúrate de sustituir todas las menciones por «smprofen el guion de smppy formación».
Al actualizar el nombre del paquete Python de SageMaker Profiler en sus scripts de entrenamiento, para evitar confusiones sobre la versión del nombre del paquete que debe usar, considere la posibilidad de usar una declaración de importación condicional, como se muestra en el siguiente fragmento de código.
try: import smprof except ImportError: # backward-compatability for TF 2.11 and PT 1.13.1 images import smppy as smprof
Tenga en cuenta también que, si lo ha estado utilizando smppy durante la actualización a la TensorFlow versión PyTorch o versiones más recientes, asegúrese de instalar el smprof paquete más reciente siguiendo las instrucciones que aparecen en. (Opcional) Instale el paquete SageMaker Profiler Python
P: Recibo un mensaje de error, ModuleNotFoundError: No
module named 'smprof'
En primer lugar, asegúrese de utilizar uno de los contenedores SageMaker Framework compatibles oficialmente. Si no usa uno de esos, puede instalar el smprof paquete siguiendo las instrucciones que aparecen en(Opcional) Instale el paquete SageMaker Profiler Python.
P: No puedo importar ProfilerConfig
Si no puede importar ProfilerConfig el script del iniciador de tareas mediante SageMaker PythonSDK, es posible que su entorno local o el núcleo de Jupyter tengan una versión de Python considerablemente desactualizada. SageMaker SDK Asegúrese de actualizarla SDK a la versión más reciente.
$ pip install --upgrade sagemaker
P: Recibo un mensaje de error, aborted: core dumped when
importing smprof into my training script
En una versión anterior desmprof, este problema se producía con la versión PyTorch 2.0+ y PyTorch Lightning. Para resolver este problema, instale también el smprof paquete más reciente siguiendo las instrucciones que se encuentran en(Opcional) Instale el paquete SageMaker Profiler Python.
P: No encuentro la interfaz de usuario SageMaker de Profiler en SageMaker Studio. ¿Cómo puedo encontrarla?
Si tiene acceso a la SageMaker consola, elija una de las siguientes opciones.
Si es usuario de un dominio y no tiene acceso a la SageMaker consola, puede acceder a la aplicación a través de SageMaker Studio Classic. Si este es tu caso, elige la siguiente opción.
Consideraciones
Tenga en cuenta lo siguiente cuando utilice SageMaker Profiler.
-
SageMaker El generador de perfiles no es compatible con las piscinas de agua caliente SageMaker gestionadas.
