Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Evacuación controlada por plano de control
El primer patrón utiliza las operaciones del plano de datos para evitar realizar trabajos en una zona de disponibilidad afectada y mitigar el impacto de un evento. Sin embargo, es posible que esté utilizando una arquitectura que no utilice equilibradores de carga o donde no sea posible configurar una comprobación de estado por cada host. O bien, puede que desee evitar que se despliegue nueva capacidad en la zona de disponibilidad afectada mediante el escalado automático o con una programación de trabajo normal.
Para abordar ambas situaciones, es necesario realizar acciones en el plano de control para actualizar la configuración del recurso. El patrón funcionará para cualquier servicio cuya configuración de red se pueda actualizar, por ejemplo, EC2 Auto Scaling, Amazon ECS, Lambda, etc. Requiere escribir código para cada servicio, pero la lógica empresarial sigue un patrón estándar. El código debe estar ejecutado localmente por un operador que responda al evento para minimizar las dependencias requeridas. El flujo básico de la lógica del script se muestra en la figura siguiente.
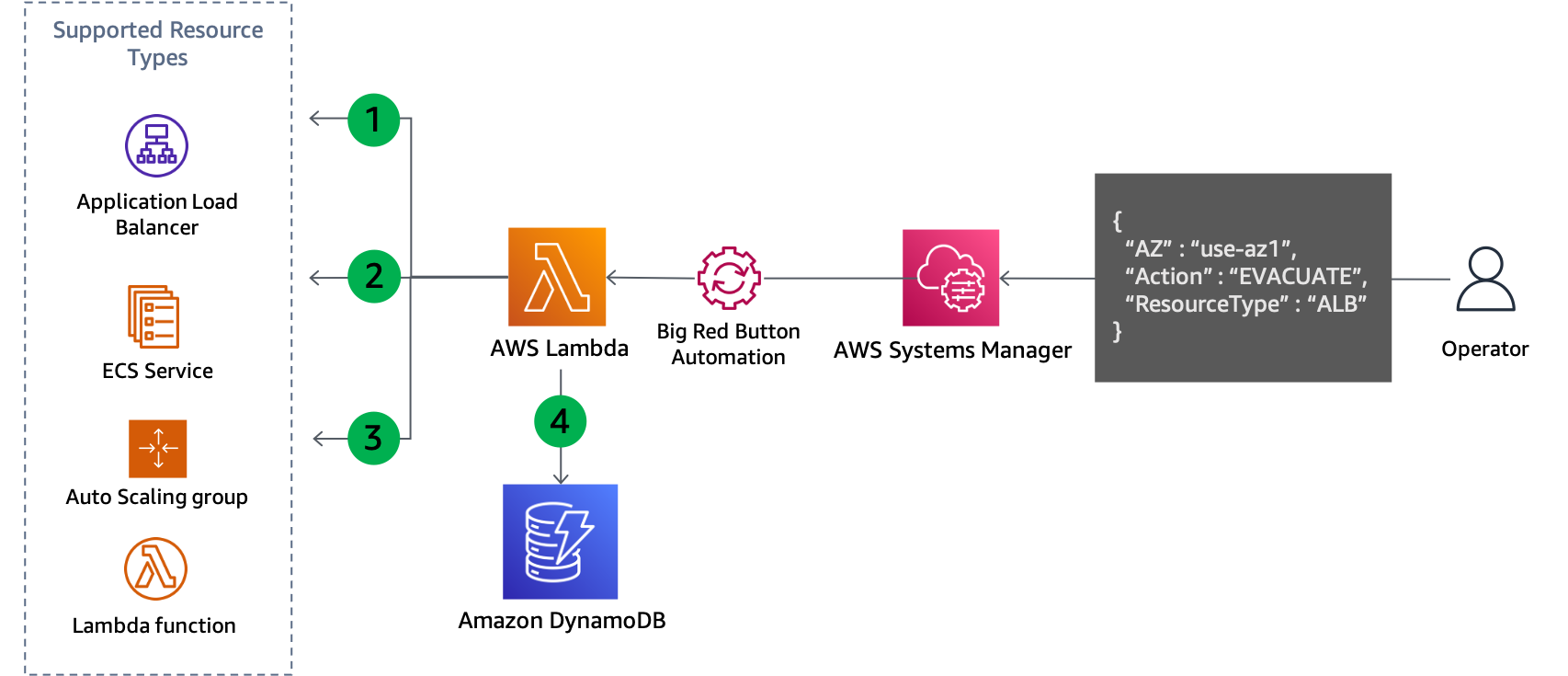
Actualización del plano de control para evacuar una zona de disponibilidad
-
El script muestra todos los recursos del tipo especificado, por ejemplo, el grupo de escalado automático, el servicio de ECS o la función de Lambda, y recupera sus subredes a partir de la información del recurso. Los recursos compatibles dependen de la compatibilidad que haya configurado el script.
-
Determina qué subredes deben eliminarse comparando el nombre de la zona de disponibilidad de cada subred con su ID de zona de disponibilidad asignado que se ha proporcionado como parámetro de entrada.
-
La configuración de red del recurso se actualiza para eliminar las subredes identificadas.
-
Los detalles de la actualización se registran en una tabla de DynamoDB. El ID de la zona de disponibilidad se almacena como la clave de partición y el ARN o el nombre del recurso se almacena como la clave de clasificación. Las subredes que se eliminan se almacenan como una matriz de cadenas. Por último, el tipo de recurso también se almacena y se usa como una clave hash para un índice secundario global (GSI).
Como en el paso cuatro se registran las actualizaciones realizadas, este enfoque también puede invertirse fácilmente cuando esté listo para la recuperación, como se muestra en la siguiente figura.
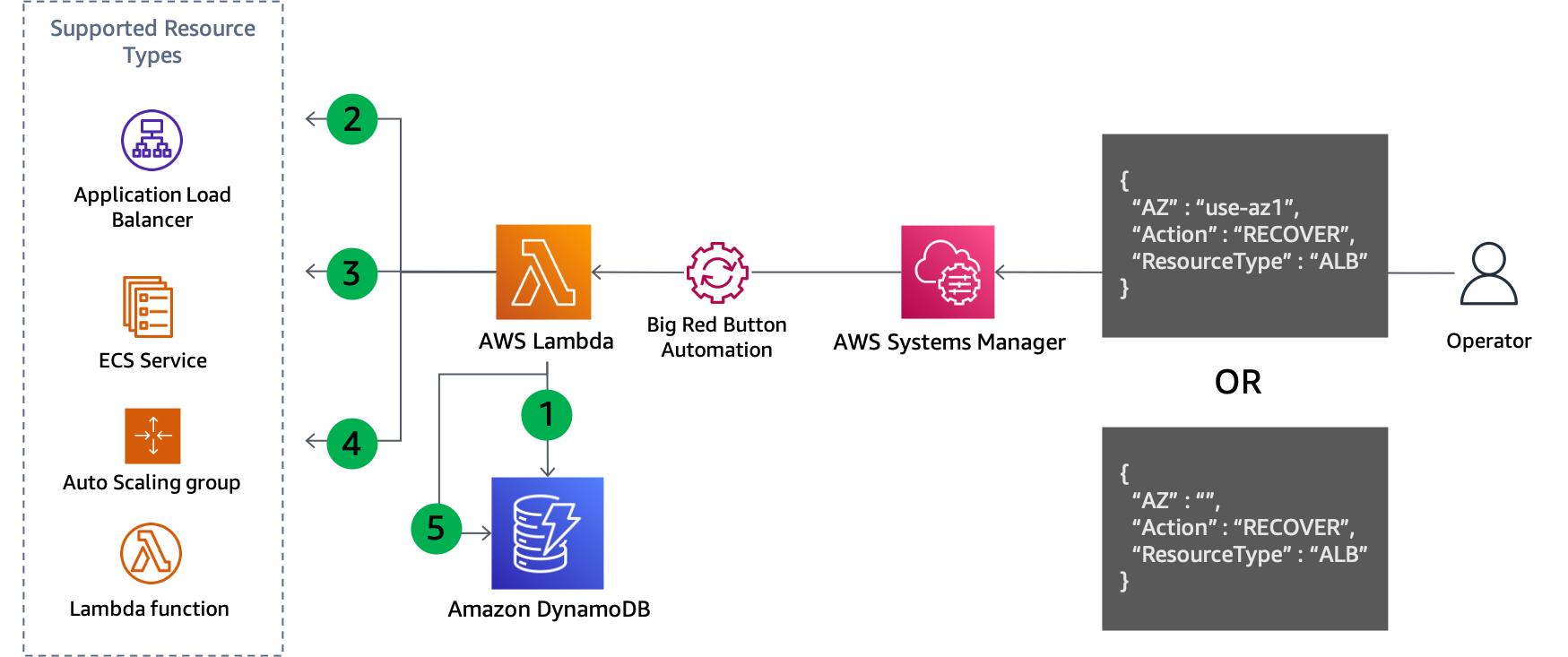
Actualización del plano de control para recuperarse de la evacuación de una zona de disponibilidad
Pasos de recuperación:
-
Consulte el GSI para eliminar las subredes de cada recurso del tipo especificado en la zona de disponibilidad especificada (o todas las zonas de disponibilidad, si no se especifica ninguna).
-
Describa cada recurso encontrado en la consulta de DynamoDB para obtener su configuración de red actual.
-
Combine las subredes de la configuración de red actual con las recuperadas de la consulta de DynamoDB.
-
Actualice la configuración de red del recurso con el nuevo conjunto de subredes.
-
Elimine el registro de la tabla de DynamoDB una vez que la actualización se haya completado correctamente.
Este patrón generalizado impide enrutar el trabajo a la zona de disponibilidad afectada e impide que se implemente ninguna nueva capacidad en ella. Los siguientes son ejemplos de cómo se logra esto para diferentes servicios.
-
Lambda: actualice la configuración de VPC de la función para eliminar las subredes de la zona de disponibilidad especificada.
-
Grupo de escalado automático: elimine las subredes de la configuración de ASG que sustituirán esa capacidad en las zonas de disponibilidad restantes.
-
Amazon ECS: actualice la configuración de la VPC del servicio de ECS para eliminar las subredes.
-
Amazon EKS: aplique taints
a los nodos de la zona de disponibilidad afectada para expulsar los pods existentes y evitar que se programen nuevos pods en ella.
Cada servicio reaccionará de forma diferente a la actualización de la configuración. Por ejemplo, Amazon ECS seguirá la configuración de implementación del servicio después de una actualización y desencadenará una implementación continua o una implementación azul/verde de nuevas tareas.
Estas actualizaciones pueden trasladar el trabajo a las zonas de disponibilidad en buen estado con demasiada rapidez para algunas cargas de trabajo. Aunque está configurado para permanecer estable de forma estática ante el error (con suficiente capacidad aprovisionada previamente en las zonas de disponibilidad restantes para manejar el trabajo de la zona de disponibilidad afectada), es posible que también desee eliminar gradualmente capacidad de la zona de disponibilidad afectada.
Si tiene previsto actualizar la configuración de red de su grupo de escalado automático que es el grupo objetivo de un equilibrador de carga con el equilibro de cargas entre zonas deshabilitado, siga estas instrucciones.
El escalado automático reacciona a este cambio utilizando su lógica de reequilibrio de zonas de disponibilidad. Lanzará instancias en las demás zonas de disponibilidad para cumplir con la capacidad deseada y terminará las instancias en la zona de disponibilidad que haya eliminado. Sin embargo, el equilibrador de carga seguirá dividiendo el tráfico de manera uniforme en cada zona de disponibilidad, incluida la que ha eliminado del ASG, mientras se cancelen las instancias. Esto podría provocar una disminución de la capacidad restante en esa zona de disponibilidad hasta que todas las instancias se terminen correctamente en esa zona. Este es el mismo problema que se describe en Independencia de la zona de disponibilidad en relación con el desequilibrio de las zonas de disponibilidad cuando el equilibrio de carga entre zonas está deshabilitado. Para evitar que esto ocurra, puede hacer lo siguiente:
-
Ejecute siempre primero la evacuación de la zona de disponibilidad para que el tráfico solo se divida entre las zonas de disponibilidad restantes
-
Especifique un número mínimo de destinos con estado correcto con una conmutación por error de DNS que coincida con el número mínimo de destinos requerido para esa zona de disponibilidad.
Esto ayudará a garantizar que el tráfico no se envíe a la zona de disponibilidad que ha eliminado una vez que las instancias comiencen a terminarse.
