Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Evacuación controlada por un plano de datos
Hay varias soluciones que puede implementar para llevar a cabo una evacuación de una zona de disponibilidad utilizando acciones únicamente basadas en un plano de datos. En esta sección, se describen tres de ellas y los casos de uso donde deberá elegir una en lugar de otra.
Al utilizar cualquiera de estas soluciones, debe asegurarse de tener suficiente capacidad en las zonas de disponibilidad restantes para manejar la carga de la zona de disponibilidad de la que va a salir. La forma más resiliente de hacerlo es aprovisionando previamente la capacidad requerida en cada zona de disponibilidad. Si utiliza tres zonas de disponibilidad, tendrá implementada en cada una el 50 % de la capacidad necesaria para manejar los picos de carga, de modo que con la pérdida de una única zona de disponibilidad seguiría quedándole el 100 % de la capacidad necesaria sin tener que depender de un plano de control para aprovisionar más.
Además, si utiliza EC2 Auto Scaling, asegúrese de que su grupo de escalado automático (ASG) no se reduzca horizontalmente durante el cambio, para que cuando finalice el cambio todavía tenga suficiente capacidad en el grupo para manejar el tráfico de los clientes. Para ello, asegúrese de que la capacidad mínima deseada de su ASG pueda manejar su carga de clientes actual. También puede asegurarse de que su ASG no se reduzca horizontalmente de manera inadvertida utilizando promedios en las métricas en lugar de métricas de percentiles atípicos, como P90 o P99.
Durante un cambio, los recursos que ya no prestan servicio al tráfico deberían tener un uso muy bajo, pero los demás recursos aumentarán su utilización con el nuevo tráfico, manteniendo el promedio bastante uniforme, lo que impedirá adoptar medidas de escalamiento. Por último, también puede usar la configuración de estado de grupo de destino para ALB y NLB, para especificar la conmutación por error de DNS con un porcentaje o un recuento de hosts en buen estado. Esto evita que el tráfico se enrute a una zona de disponibilidad que no tiene suficientes hosts en buen estado.
Cambio de zona en Controlador de recuperación de aplicaciones (ARC) de Route 53
La primera solución para la evacuación de zonas de disponibilidad utiliza el cambio de zona en Route 53 ARC. Esta solución se puede utilizar para cargas de trabajo de solicitud/respuesta que utilizan un NLB o un ALB como punto de entrada para el tráfico de los clientes.
Cuando detecte que una zona de disponibilidad se ha deteriorado, puede iniciar un cambio de zona con el Route 53 ARC. Una vez que se complete esta operación y caduquen las respuestas de DNS almacenadas en caché, todas las solicitudes nuevas solo se enrutarán a los recursos de las zonas de disponibilidad restantes. En la figura siguiente, se muestra cómo funciona el cambio de zona. En la siguiente figura, tenemos un registro de alias de Route 53 para www.example.com que apunta a my-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com. El cambio de zona se realiza para la zona de disponibilidad 3.
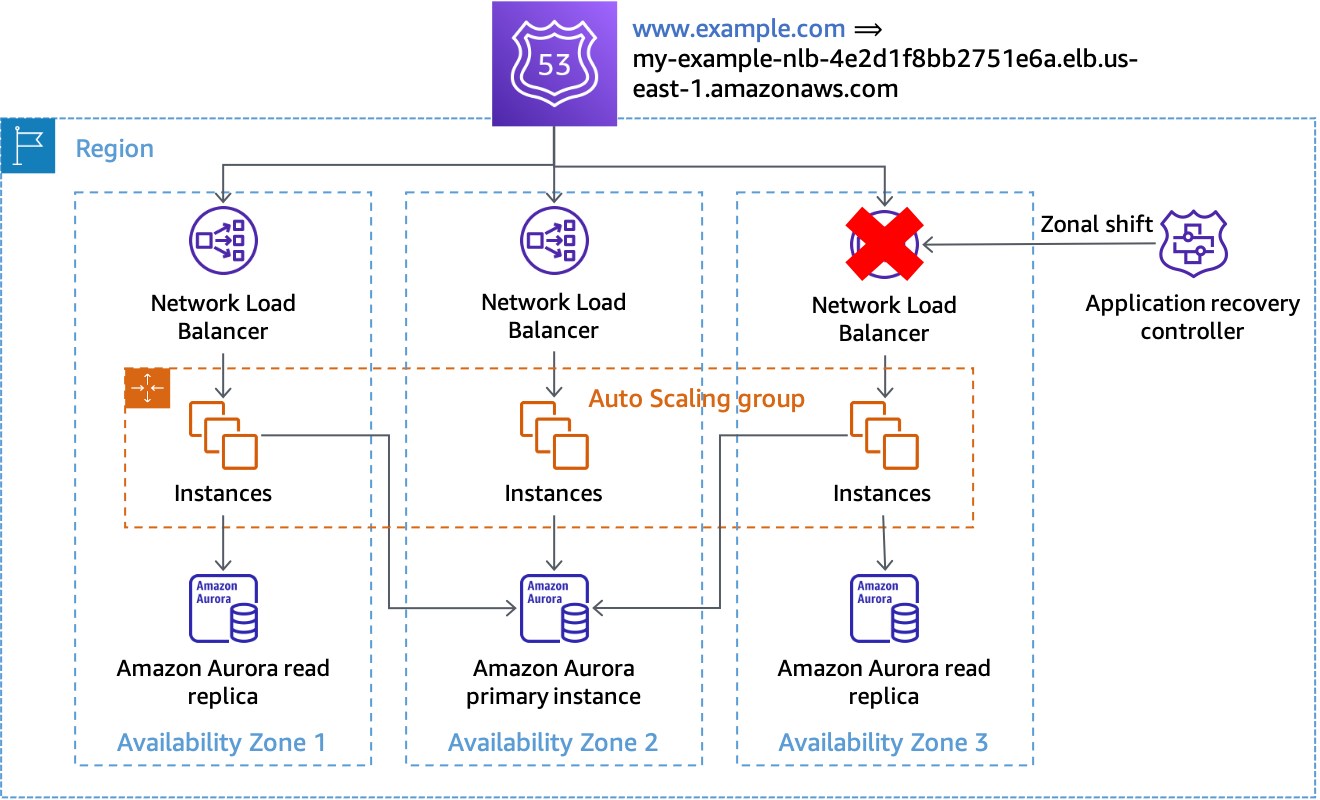
Cambio de zona
En el ejemplo, si la instancia de base de datos principal no se encuentra en la zona de disponibilidad 3, la única acción necesaria para lograr el primer resultado de evacuación es realizar el cambio de zona y evitar que el trabajo se procese en la zona de disponibilidad afectada. Si el nodo principal estaba en la zona de disponibilidad 3, puede realizar una conmutación por error iniciada manualmente (que depende del plano de control de Amazon RDS) en coordinación con el cambio de zona, si Amazon RDS no ha realizado ya la conmutación por error automática. Esto se aplicará a todas las soluciones controladas por el plano de datos de esta sección.
Debe iniciar el cambio de zona utilizando los comandos de CLI o la API para minimizar las dependencias necesarias para iniciar la evacuación. Cuanto más simple sea el proceso de evacuación, más fiable será. Los comandos específicos se pueden almacenar en un manual de procedimientos local al que los ingenieros de guardia pueden acceder fácilmente. El cambio de zona es la solución preferida y más sencilla para evacuar una zona de disponibilidad.
Route 53 ARC
La segunda solución utiliza las capacidades de Route 53 ARC para especificar manualmente el estado de determinados registros de DNS. Esta solución tiene la ventaja de utilizar el plano de datos del clúster de Route 53 ARC de alta disponibilidad, lo que la hace resiliente al deterioro de hasta dos Regiones de AWS diferentes. Tiene la desventaja de un costo adicional y requiere una configuración adicional de los registros de DNS. Para implementar este patrón, debe crear registros de alias para los nombres de DNS específicos de la zona de disponibilidad proporcionados por el equilibrador de carga (ALB o NLB). Esto se muestra en la siguiente tabla.
Tabla 3: Registros de alias de Route 53 configurados para los nombres de DNS zonales del equilibrador de carga
|
Política de enrutamiento: ponderada Nombre: Tipo: Valor: Peso: Evaluar el estado del destino: true |
Política de enrutamiento: ponderada Nombre: Tipo: Valor Peso: Evaluar el estado del destino: |
Política de enrutamiento: ponderada Nombre: Tipo: Valor Peso: Evaluar el estado del destino: |
Para cada uno de estos registros de DNS, debe configurar una comprobación de estado de Route 53 asociada a un control de enrutamiento de Route 53 ARC. Cuando desee iniciar una evacuación de una zona de disponibilidad, establezca el estado del control de enrutamiento en Off. AWS recomienda hacerlo utilizando la CLI o la API para minimizar las dependencias necesarias para iniciar la evacuación de la zona de disponibilidad. Como práctica recomendada, debe conservar una copia local de los puntos de conexión del clúster de Route 53 ARC para no tener que recuperarlos del plano de control de ARC cuando necesite realizar una evacuación.
Para minimizar los costos al utilizar este enfoque, puede crear un único clúster de Route 53 ARC y realizar comprobaciones de estado en una sola Cuenta de AWS y compartir las comprobaciones de estado con otras Cuentas de AWSuse1-az1) en lugar del nombre de la zona de disponibilidad (por ejemplo, us-east-1a) para sus controles de enrutamiento. Como AWS asigna la zona de disponibilidad física de forma aleatoria a los nombres de las zonas de disponibilidad de cada Cuenta de AWS, el uso del AZ-ID proporciona una forma coherente de hacer referencia a las mismas ubicaciones físicas. Al iniciar una evacuación de una zona de disponibilidad, por ejemplo, para use1-az2, los conjuntos de registros de Route 53 en cada Cuenta de AWS deberían asegurarse de utilizar la asignación de AZ-ID para configurar la comprobación de estado adecuada para cada registro de NLB.
Por ejemplo, supongamos que tenemos una comprobación de estado de Route 53 asociada a un control de enrutamiento de Route 53 ARC para use1-az2, con un ID de 0385ed2d-d65c-4f63-a19b-2412a31ef431. Si en una Cuenta de AWS diferente que desea utilizar esta comprobación de estado, us-east-1c se ha asignado a use1-az2, deberá utilizar la comprobación de estado de use1-az2 para el registro us-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com. Deberá utilizar el ID de comprobación de estado 0385ed2d-d65c-4f63-a19b-2412a31ef431 con ese conjunto de registros de recursos.
Uso de un punto de conexión HTTP autoadministrado.
También puede implementar esta solución administrando su propio punto de conexión HTTP que indica el estado de una zona de disponibilidad concreta. Esto permite especificar manualmente cuándo una zona de disponibilidad tiene un estado incorrecto en función de la respuesta del punto de conexión HTTP. Esta solución tiene un costo menor que usar Route 53 ARC, pero es más costosa que el cambio de zona y requiere la administración de una infraestructura adicional. Tiene la ventaja de ser mucho más flexible para diferentes escenarios.
El patrón se puede usar con las arquitecturas NLB o ALB y con las comprobaciones de estado de Route 53. También se puede usar en arquitecturas sin equilibrio de carga, como los sistemas de detección de servicios o procesamiento de colas, donde los nodos de trabajo realizan sus propias comprobaciones de estado. En estos casos, los hosts pueden usar un subproceso en segundo plano donde realizan periódicamente una solicitud al punto de conexión HTTP con su AZ-ID (consulte Apéndice A: Obtener el ID de la zona de disponibilidad para obtener más información sobre cómo encontrarlo) y reciben una respuesta sobre el estado de la zona de disponibilidad.
Si se ha declarado que la zona de disponibilidad tiene un estado incorrecto, tienen varias opciones para responder. Pueden optar por no pasar una comprobación de estado externa procedente de fuentes como ELB o Route 53, o comprobaciones de estado personalizadas en las arquitecturas de detección de servicios para que parezcan tener un estado incorrecto para esos servicios. También pueden responder inmediatamente con un error si reciben una solicitud, lo que permite al cliente retroceder y volver a intentarlo. En las arquitecturas basadas en eventos, los nodos pueden dejar de procesar el trabajo de forma intencionada, por ejemplo, devolviendo intencionadamente un mensaje de SQS a la cola. En las arquitecturas de enrutadores de trabajo donde un servicio central programa el trabajo en hosts específicos, también se puede utilizar este patrón. El enrutador puede comprobar el estado de una zona de disponibilidad antes de seleccionar un trabajador, un punto de conexión o una celda. En las arquitecturas de detección de servicios que utilizan AWS Cloud Map, puede detectar los puntos de conexión proporcionando un filtro en la solicitud
En la siguiente figura, se muestra cómo se puede utilizar este enfoque para varios tipos de cargas de trabajo.
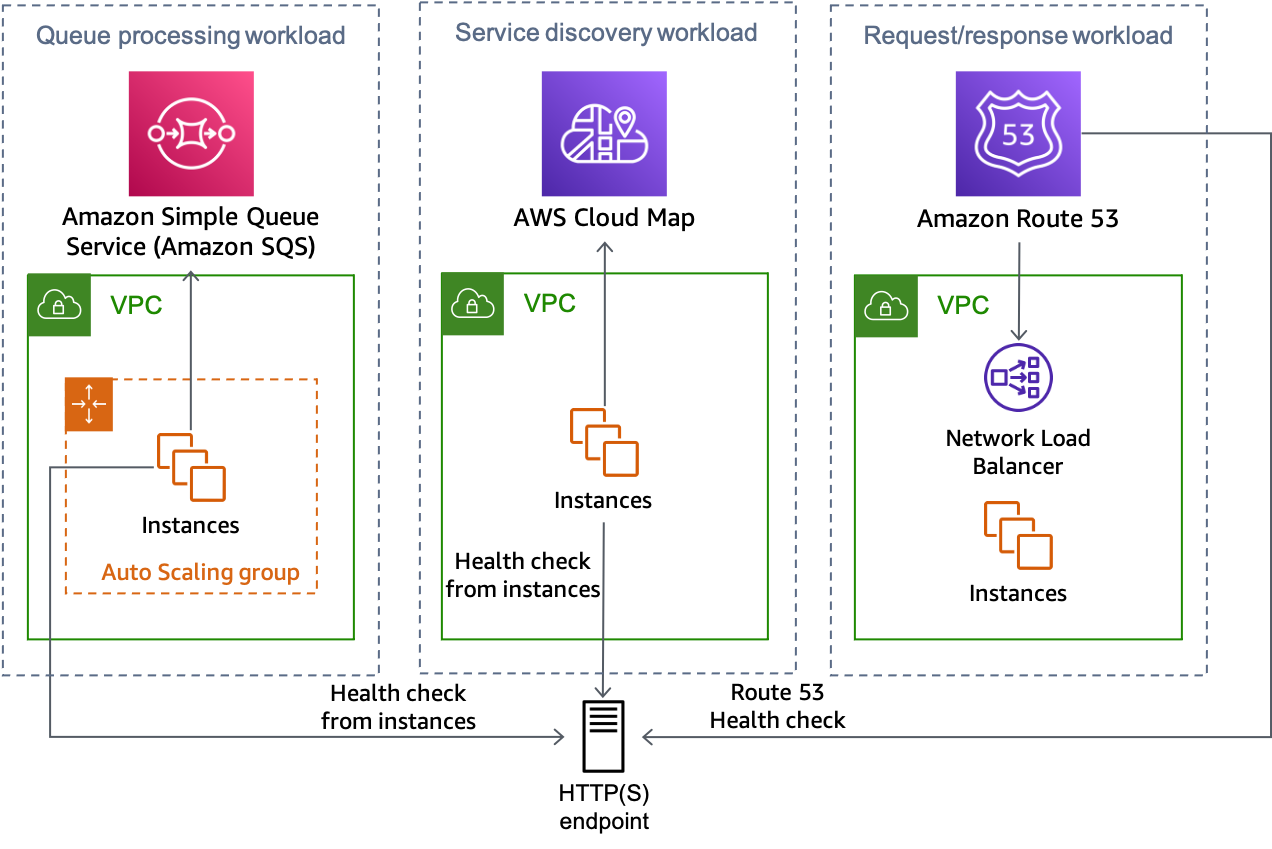
Varios tipos de carga de trabajo que pueden utilizar la solución de punto de conexión HTTP
Hay varias formas de implementar el enfoque de punto de conexión HTTP, dos de las cuales se describen a continuación.
Uso de Amazon S3
Este patrón se presentó originalmente en esta entrada de blog
En este escenario, debe crear conjuntos de registros de recursos de Route 53 DNA para cada registro de DNS zonal, como en el escenario de Route 53 ARC anterior, así como las comprobaciones de estado asociadas. Sin embargo, para esta implementación, en lugar de asociar las comprobaciones de estado con los controles de enrutamiento de Route 53 ARC, se configuran para usar un punto de conexión HTTP y se invierten para evitar que un deterioro en Amazon S3 desencadene accidentalmente una evacuación. La comprobación de estado se considera que tiene un buen estado cuando el objeto está ausente y un estado incorrecto cuando el objeto está presente. Esta configuración se muestra en la siguiente tabla.
Tabla 4: Configuración de registros de DNS para usar las comprobaciones de estado de Route 53 por zona de disponibilidad
|
Tipo de comprobación de estado: supervisar un punto de conexión Protocolo: ID: URL: |
Tipo de comprobación de estado: supervisar un punto de conexión Protocolo: ID: URL: |
Tipo de comprobación de estado: supervisar un punto de conexión Protocolo: ID: URL: |
← | Comprobaciones de estado |
| ↑ | ↑ | ↑ | ||
|
Política de enrutamiento: ponderada Nombre: Tipo: Valor: Peso: Evaluar el estado del destino: |
Política de enrutamiento: ponderada Nombre: Tipo: Valor: Peso: Evaluar el estado del destino: |
Política de enrutamiento: ponderada Nombre: Tipo: Valor: Peso: Evaluar el estado del destino: |
← | Los registros A de alias de nivel superior y ponderados uniformemente apuntan a puntos de conexión específicos de NLB AZ |
Supongamos que la zona de disponibilidad us-east-1a está asignada a use1-az3 en la cuenta donde tenemos una carga de trabajo y queremos realizar una evacuación de la zona de disponibilidad. Para el conjunto de registros de recursos creado para us-east-1a.load-balancer-name.elb.us-east-1.amazonaws.com, se asociará una comprobación de estado que compruebe la URLhttps://. Cuando desee iniciar una evacuación de una zona de disponibilidad para bucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3, cargue un archivo con el nombre use1-az3.txt en el bucket mediante la CLI o la API. No es necesario que el archivo contenga ningún contenido, pero sí que debe ser público para que la comprobación de estado de Route 53 pueda acceder a él. En la siguiente figura, se muestra cómo se utiliza esta implementación para evacuar use1-az3.
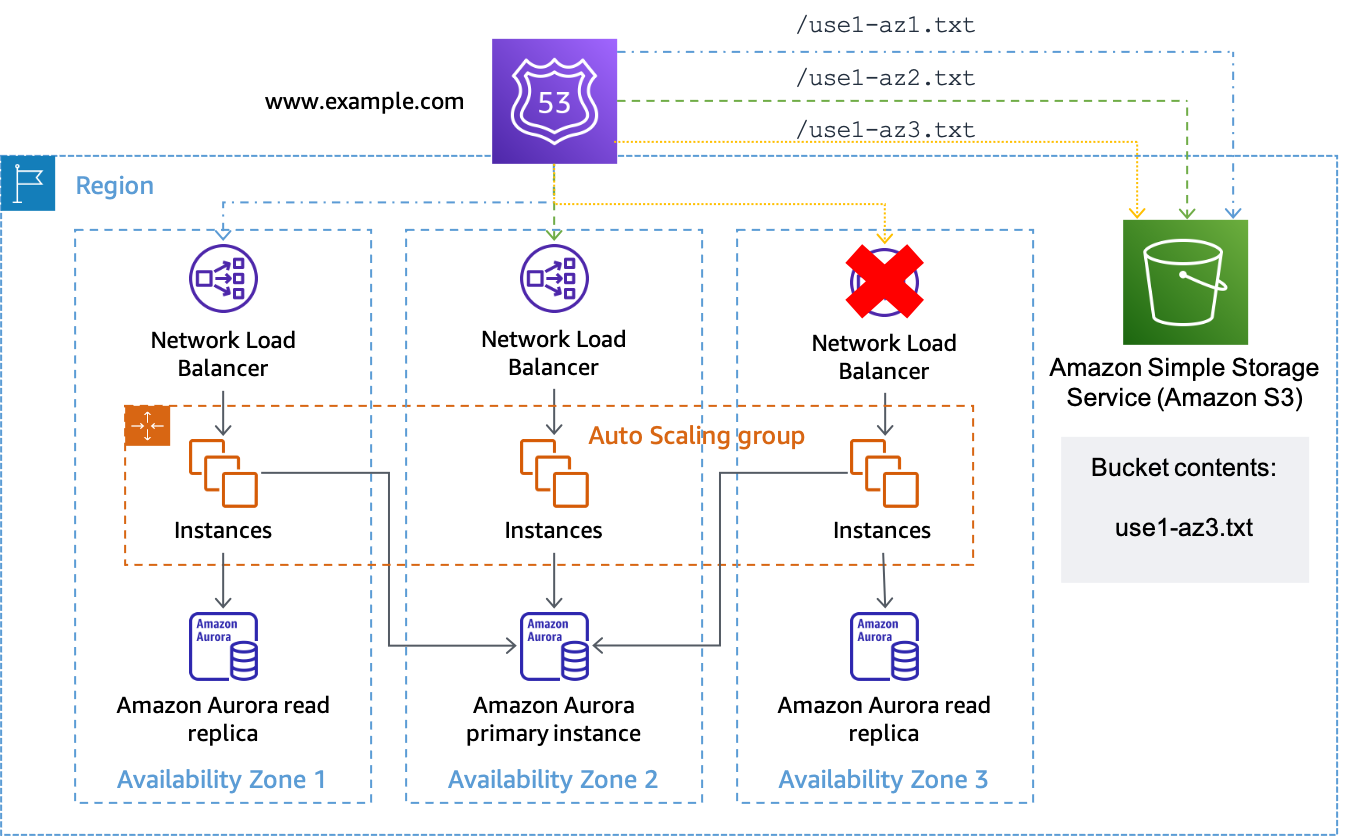
Uso de Amazon S3 como destino para una comprobación de estado de Route 53
Uso de API Gateway y DynamoDB
La segunda implementación de este patrón usa una API de REST de Amazon API Gateway
Si utiliza esta solución con una arquitectura NLB o ALB, configure sus registros de DNS de la misma manera que en el ejemplo anterior de Amazon S3, excepto que debe cambiar la ruta de comprobación de estado para utilizar el punto de conexión de API Gateway y proporcionar el AZ-ID en la URL. Por ejemplo, si API Gateway se ha configurado con un dominio personalizado az-status.example.com, la solicitud completa de use1-az1 aparecerá como https://az-status.example.com/status/use1-az1. Cuando desee iniciar una evacuación de una zona de disponibilidad, puede crear o actualizar un elemento de DynamoDB mediante la CLI o la API. El elemento utiliza el AZ-ID como clave principal y tiene un atributo booleano denominado Healthy que se utiliza para indicar cómo responde API Gateway. A continuación, se muestra un ejemplo de código utilizado en la configuración de API Gateway para realizar esta determinación.
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
Si el atributo es true (o no está presente), API Gateway responde a la comprobación de estado con un HTTP 200; si es false, responde con un HTTP 500. Esta implementación se muestra en la siguiente figura.
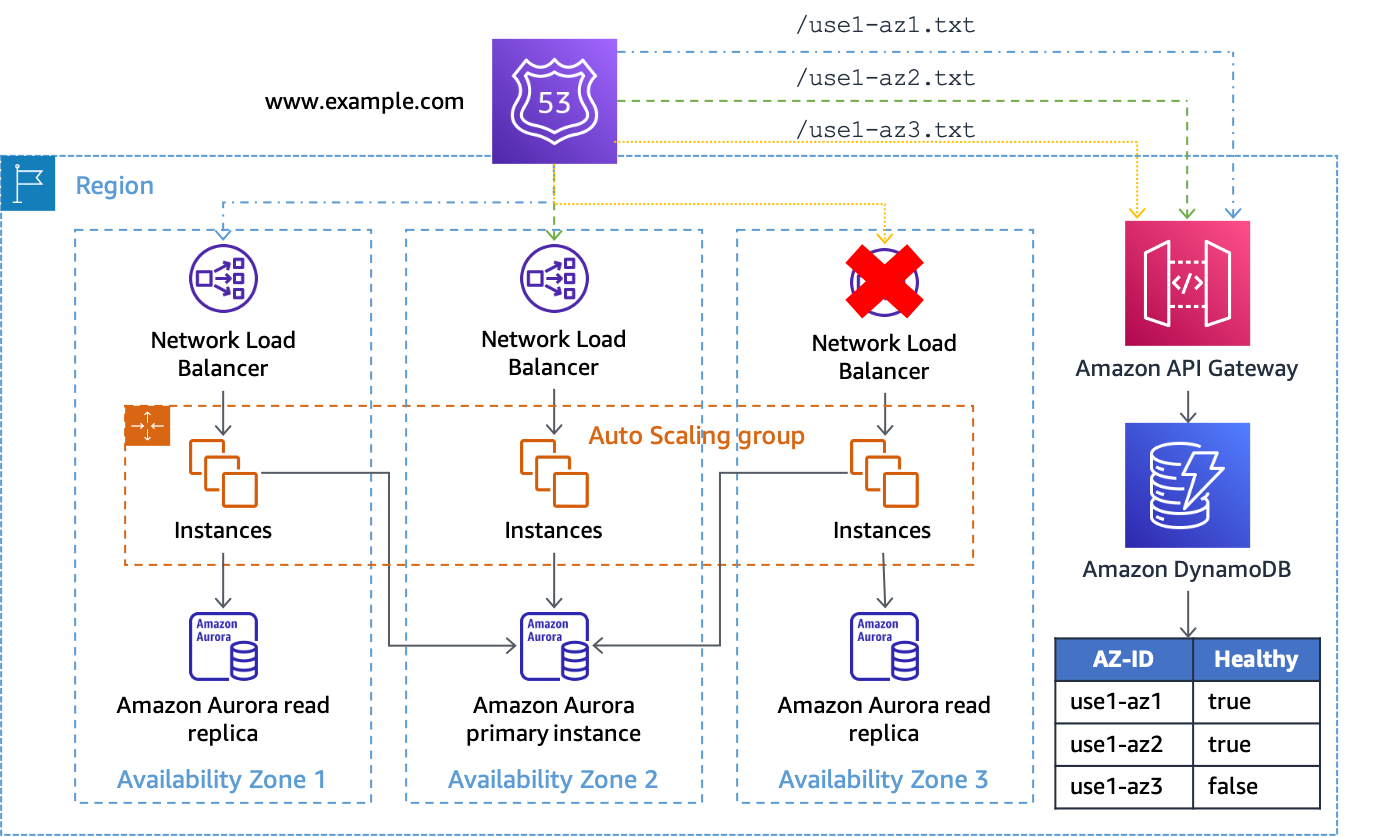
Uso de API Gateway y DynamoDB como el destino de las comprobaciones de estado de Route 53
En esta solución, debe usar API Gateway delante de DynamoDB para poder hacer que el punto de conexión sea de acceso público y manipular la URL de la solicitud para convertirla en una solicitud GetItem de DynamoDB. La solución también ofrece flexibilidad si desea incluir datos adicionales en la solicitud. Si desea crear estados más detallados, por ejemplo, por aplicación, puede configurar la URL de comprobación de estado para proporcionar un ID de aplicación en la ruta o cadena de consulta que también coincida con el elemento de DynamoDB.
El punto de conexión de estado de la zona de disponibilidad se puede implementar de forma centralizada para que varios recursos de comprobación de estado en las Cuentas de AWS puedan utilizar la misma vista coherente del estado de la zona de disponibilidad (lo que garantiza que la API de REST de API Gateway y la tabla de DynamoDB estén escaladas para manejar la carga) y eliminar la necesidad de compartir las comprobaciones de estado de Route 53.
La solución también se puede escalar en varias Regiones de AWS mediante una tabla global de Amazon DynamoDB
Si está creando una solución para que los hosts individuales la utilicen como un mecanismo para determinar el estado de su zona de disponibilidad, como alternativa, en lugar de proporcionar un mecanismo de extracción para las comprobaciones de estado, puede utilizar las notificaciones push. Una forma de hacerlo es con un tema de SNS al que estén suscritos los consumidores. Cuando desee desencadenar el interruptor de circuito, publique un mensaje en el tema de SNS en el que se indique qué zona de disponibilidad está deteriorada. Este enfoque presenta algunas contrapartidas respecto al anterior. Elimina la necesidad de crear y operar la infraestructura de API Gateway, y ejecutar la administración de la capacidad. También puede proporcionar una convergencia más rápida del estado de la zona de disponibilidad. Sin embargo, elimina la posibilidad de realizar consultas ad hoc y se basa en la Política de reintentos de entrega de SNS para garantizar que cada punto de conexión reciba la notificación. También requiere que cada carga de trabajo o servicio cree una forma de recibir la notificación de SNS y tomar medidas al respecto.
Por ejemplo, cada nueva instancia o contenedor de EC2 que se lance deberá suscribirse al tema con un punto de conexión HTTP durante su arranque. A continuación, cada instancia debe implementar un software que escuche en el punto de conexión donde se entrega la notificación. Asimismo, si la instancia se ve afectada por el evento, es posible que no reciba la notificación push y siga funcionando. Por el contrario, con una notificación pull, la instancia sabrá si su solicitud de extracción falla y podrá elegir qué acción realizar como respuesta.
Una segunda forma de enviar notificaciones push es con conexiones de WebSocket de larga duración. Amazon API Gateway se puede utilizar para proporcionar una API de WebSocket a la que los consumidores puedan conectarse y recibir un mensaje cuando lo envíe el backend. Con un WebSocket, las instancias pueden realizar extracciones periódicas para garantizar que su conexión esté en buen estado y también recibir notificaciones push de baja latencia.
