Introduction
The AWS Cloud accelerates big data analytics. With access to instant scalability and elasticity on AWS, you can focus on analytics instead of infrastructure. Whether you are indexing large data sets, analyzing massive amounts of scientific data, or processing clickstream logs, AWS provides a range of big data products and services that you can leverage for virtually any data-intensive project.
There is a wide adoption of NoSQL databases in the growing industry of big data and real-time web applications. Amazon DynamoDB and Apache HBase are examples of NoSQL databases, which are highly optimized to yield significant performance benefits over a traditional relational database management system (RDBMS). Both Amazon DynamoDB and Apache HBase can process large volumes of data with high performance and throughput.
Amazon DynamoDB provides a fast, fully managed NoSQL database
service. It lets you offload operating and scaling a highly
available, distributed database cluster. Apache HBase is an
open-source, column-oriented, distributed big data store that runs
on the Apache
Hadoop
In the AWS Cloud, you can choose to deploy Apache HBase on
Amazon Elastic Compute Cloud (Amazon EC2)
With Apache HBase on Amazon EMR, you can use
Amazon Simple Storage Service (Amazon S3)
The following figure shows the relationship between Amazon DynamoDB, Amazon EC2, Amazon EMR, Amazon S3, and Apache HBase in the AWS Cloud. Both Amazon DynamoDB and Apache HBase have tight integration with popular open source processing frameworks like Apache Hive and Apache Spark to enhance querying capabilities as illustrated in the diagram.
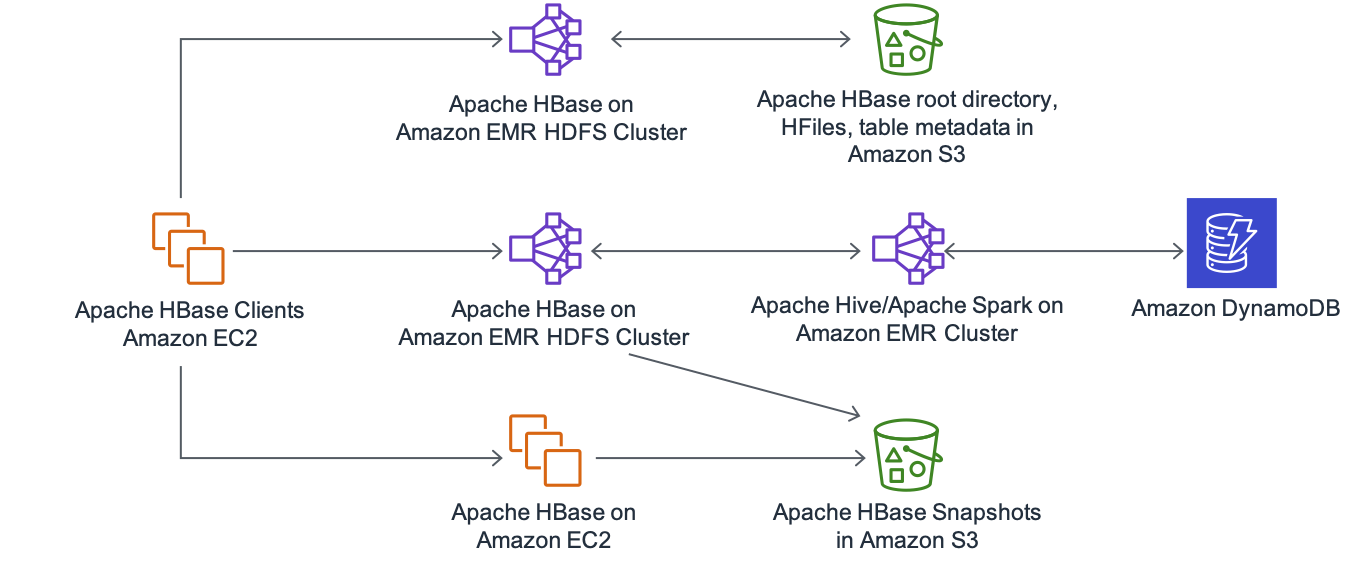
Figure 1: Relation between Amazon DynamoDB, Amazon EC2, Amazon EMR, and Apache HBase in the AWS Cloud
